Der Enterprise Policy Generator richtet sich an Administratoren von Unternehmen und Organisationen, welche Firefox konfigurieren wollen. Damit löst die Erweiterung den bekannten CCK2 Wizard in der Ära Firefox Quantum ab. Die neue Version bringt eine Funktion für den Import und Export von Konfigurationen, womit Konfigurationen nun auch geräteübergreifend geteilt werden können.
Mit Firefox 60 und Firefox ESR 60 hat Mozilla die sogenannte Enterprise Policy Engine eingeführt. Die Enterprise Policy Engine erlaubt es Administratoren, Firefox über eine Konfigurationsdatei zu konfigurieren. Der Vorteil dieser Konfigurationsdatei gegenüber Group Policy Objects (GPO) ist, dass diese Methode nicht nur auf Windows, sondern plattformübergreifend auf Windows, Apple macOS sowie Linux funktioniert.
Zwar steht diese Erweiterung in keiner direkten Verbindung zum bekannten CCK2 Wizard, teilt aber die grundlegende Idee vom CCK2 Wizard, welcher in Firefox Quantum nicht mehr funktioniert. Der Enterprise Policy Generator wurde als Nachfolger vom CCK2 Wizard konzipiert – nur eben für Firefox Quantum und Enterprise Policies. Die Firefox-Erweiterung hilft bei der Zusammenstellung der sogenannten Enterprise Policies, so dass kein tiefergehendes Studium der Dokumentation und aller möglichen Optionen notwendig ist und sich Administratoren die gewünschten Enterprise Policies einfach zusammenklicken können. Mehr Informationen gibt es in der Ankündigung zum Enterprise Policy Generator.
Neuerungen Enterprise Policy Generator 3.0.0
Konfigurationen exportieren und importieren
Nachdem die vor genau einem Monat erschienene Version 2.0.0 die Möglichkeit brachte, Konfigurationen speichern und wieder laden zu können, folgte mit Version 3.0.0 der nächste logische Schritt: ab sofort können Konfigurationen auch exportiert und wieder importiert werden. Damit werden mit dem Enterprise Policy Generator erstellte Konfigurationen portabel, denn eine erstellte Konfiguration kann so nicht mehr nur am gleichen Computer, sondern zu jedem Zeitpunkt und von jedem Computer aus weiter angepasst werden.
Validierung von URL-Feldern
Der Enterprise Policy Generator hat bereits eine Validierung von Pflichtfeldern besessen. Neu in Version 3.0.0 ist eine zusätzliche Validierung von URL-Feldern. Nach ausführlichen Tests mit verschiedenen Validierungs-Ansätzen wurde sich für den simpelsten aller Ansätze entschieden: es findet lediglich eine Validierung des Protokolls statt, das heißt, URLs müssen mit https:// oder http:// beginnen. Auf diese Weise soll sichergestellt werden, dass die Konfiguration bei speziellen, aber gültigen URLs nicht an einer Validierung scheitert, die es besonders genau zu nehmen versucht. Leider ist die Validierung aller möglichen URLs eine Wissenschaft für sich, weswegen sich für diese Erweiterung für die sichere Variante entschieden worden ist.
UX-Verbesserungen
Wird eine Policy-Checkbox aktiviert, wird nun automatisch das erste Text- oder Auswahlfeld fokussiert, so dass sofort mit der Eingabe gestartet werden kann, ohne erneut klicken zu müssen. Ähnliches gilt für Mehrfachfelder: nach Klick auf ein Plus-Symbol wird direkt das erste Textfeld fokussiert. Im umgekehrten Fall, bei Klick auf ein Minus-Symbol in einem Mehrfachfeld, wird das vorherige Text-Feld automatisch fokussiert.
Der Dialog, welcher die bereits gespeicherten Konfigurationen anzeigt, zeigt nun einen entsprechenden Hinweis anstelle einer leeren Tabelle an, wenn noch keine Konfigurationen gespeichert worden sind.
Außerdem wurde die französische Übersetzung überarbeitet.
Neue Enterprise Policies
Mit dem Update auf Version 3.0.0 gab es auch einige Anpassungen der unterstützen Enterprise Policies. Ganz neu dazu gekommen ist die Unterstützung für eine Enterprise Policy zur Konfiguration des Zugriffes auf den Standort, die Kamera, das Mikrofon sowie für Benachrichtungen (Firefox 62, Firefox ESR 60.2). Ebenfalls neu ist eine Policy zur Konfiguration des Update-Servers von Firefox (Firefox 63). Die Policy für die integrierte Authentifizierung wurde um zwei Optionen erweitert (Firefox 63), außerdem gab es diverse Versions-Anpassungen.
Die folgenden Policies sind nicht länger auf Firefox ESR beschränkt: Firefox-Updates deaktivieren (Firefox 62), Updates von System-Erweiterungen deaktvieren (Firefox 62), Telemetrie deaktivieren (Firefox 63), Startseite festlegen (Firefox 63), Anzeige der separaten Suchleiste (Firefox 63), Erweiterungen installieren oder deinstallieren (Firefox 63), Aufruf bestimmter Webseiten verhindern (Firefox 63), Integrierte Authentifizierung (Firefox 63), Überschreiben der Seite beim ersten Browser-Start (Firefox 63), Überschreiben der Seite nach einem Update (Firefox 63).
Die folgenden Policies sind nicht länger auf die Mainstream-Version von Firefox beschränkt: Hardwarebeschleunigung deaktivieren (Firefox ESR 60.2), Suchmaschinen entfernen (Firefox ESR 60.2).
Roadmap
Wer sich für die Pläne der kommenden Versionen interessiert, findet hier die aktuelle Roadmap. Auch können an dieser Stelle Vorschläge für Verbesserungen gemacht werden.
Entwicklung unterstützen
Wer die Entwicklung des Add-ons unterstützen möchte, kann dies tun, indem er der Welt vom Enterprise Policy Generator erzählt und die Erweiterung auf addons.mozilla.org bewertet. Auch würde ich mich sehr über eine kleine Spende freuen, welche es mir ermöglicht, weitere Zeit in die Entwicklung des Add-on zu investieren, um zusätzliche Features zu implementieren.
Der Enterprise Policy Generator richtet sich an Administratoren von Unternehmen und Organisationen, welche Firefox konfigurieren wollen. Damit löst die Erweiterung den bekannten CCK2 Wizard in der Ära Firefox Quantum ab. Die neue Version bringt eine Funktion für den Import und Export von Konfigurationen, womit Konfigurationen nun auch geräteübergreifend geteilt werden können.
Mit Firefox 60 und Firefox ESR 60 hat Mozilla die sogenannte Enterprise Policy Engine eingeführt. Die Enterprise Policy Engine erlaubt es Administratoren, Firefox über eine Konfigurationsdatei zu konfigurieren. Der Vorteil dieser Konfigurationsdatei gegenüber Group Policy Objects (GPO) ist, dass diese Methode nicht nur auf Windows, sondern plattformübergreifend auf Windows, Apple macOS sowie Linux funktioniert.
Zwar steht diese Erweiterung in keiner direkten Verbindung zum bekannten CCK2 Wizard, teilt aber die grundlegende Idee vom CCK2 Wizard, welcher in Firefox Quantum nicht mehr funktioniert. Der Enterprise Policy Generator wurde als Nachfolger vom CCK2 Wizard konzipiert – nur eben für Firefox Quantum und Enterprise Policies. Die Firefox-Erweiterung hilft bei der Zusammenstellung der sogenannten Enterprise Policies, so dass kein tiefergehendes Studium der Dokumentation und aller möglichen Optionen notwendig ist und sich Administratoren die gewünschten Enterprise Policies einfach zusammenklicken können. Mehr Informationen gibt es in der Ankündigung zum Enterprise Policy Generator.
Neuerungen Enterprise Policy Generator 3.0.0
Konfigurationen exportieren und importieren
Nachdem die vor genau einem Monat erschienene Version 2.0.0 die Möglichkeit brachte, Konfigurationen speichern und wieder laden zu können, folgte mit Version 3.0.0 der nächste logische Schritt: ab sofort können Konfigurationen auch exportiert und wieder importiert werden. Damit werden mit dem Enterprise Policy Generator erstellte Konfigurationen portabel, denn eine erstellte Konfiguration kann so nicht mehr nur am gleichen Computer, sondern zu jedem Zeitpunkt und von jedem Computer aus weiter angepasst werden.
Validierung von URL-Feldern
Der Enterprise Policy Generator hat bereits eine Validierung von Pflichtfeldern besessen. Neu in Version 3.0.0 ist eine zusätzliche Validierung von URL-Feldern. Nach ausführlichen Tests mit verschiedenen Validierungs-Ansätzen wurde sich für den simpelsten aller Ansätze entschieden: es findet lediglich eine Validierung des Protokolls statt, das heißt, URLs müssen mit https:// oder http:// beginnen. Auf diese Weise soll sichergestellt werden, dass die Konfiguration bei speziellen, aber gültigen URLs nicht an einer Validierung scheitert, die es besonders genau zu nehmen versucht. Leider ist die Validierung aller möglichen URLs eine Wissenschaft für sich.
UX-Verbesserungen
Wird eine Policy-Checkbox aktiviert, wird nun automatisch das erste Text- oder Auswahlfeld fokussiert, so dass sofort mit der Eingabe gestartet werden kann, ohne erneut klicken zu müssen. Ähnliches gilt für Auswahlfelder: nach Klick auf ein Plus-Symbol wird direkt das erste Textfeld fokussiert. Im umgekehrten Fall, bei Klick auf ein Minus-Symbol in einem Mehrfachfeld, wird das vorherige Text-Feld automatisch fokussiert.
Der Dialog, welcher die bereits gespeicherten Konfigurationen anzeigt, zeigt nun einen entsprechenden Hinweis anstelle einer leeren Tabelle an, wenn noch keine Konfigurationen gespeichert worden sind.
Außerdem wurde die französische Übersetzung überarbeitet.
Neue Enterprise Policies
Mit dem Update auf Version 3.0.0 gab es auch einige Anpassungen der unterstützen Enterprise Policies. Ganz neu dazu gekommen ist die Unterstützung für eine Enterprise Policy zur Konfiguration des Zugriffes auf den Standort, die Kamera, das Mikrofon sowie für Benachrichtungen. Ebenfalls neu ist eine Policy zur Konfiguration des Update-Servers von Firefox. Die Policy für die integrierte Authentifizierung wurde um zwei Optionen erweitert, außerdem gab es diverse Versions-Anpassungen.
Die folgenden Policies sind nicht länger auf Firefox ESR beschränkt: Firefox-Updates deaktivieren (Firefox 62), Updates von System-Erweiterungen deaktvieren (Firefox 62), Telemetrie deaktivieren (Firefox 63), Startseite festlegen (Firefox 63), Anzeige der separaten Suchleiste (Firefox 63), Erweiterungen installieren oder deinstallieren (Firefox 63), Aufruf bestimmter Webseiten verhindern (Firefox 63), Integrierte Authentifizierung (Firefox 63), Überschreiben der Seite beim ersten Browser-Start (Firefox 63), Überschreiben der Seite nach einem Update (Firefox 63).
Die folgenden Policies sind nicht länger auf die Mainstream-Version von Firefox beschränkt: Hardwarebeschleunigung deaktivieren (Firefox ESR 60.2), Suchmaschinen entfernen (Firefox ESR 60.2).
Roadmap
Wer sich für die Pläne der kommenden Versionen interessiert, findet hier die aktuelle Roadmap. Auch können an dieser Stelle Vorschläge für Verbesserungen gemacht werden.
Entwicklung unterstützen
Wer die Entwicklung des Add-ons unterstützen möchte, kann dies tun, indem er der Welt vom Enterprise Policy Generator erzählt und die Erweiterung auf addons.mozilla.org bewertet. Auch würde ich mich sehr über eine kleine Spende freuen, welche es mir ermöglicht, weitere Zeit in die Entwicklung des Add-on zu investieren, um zusätzliche Features zu implementieren.
Entwickler brauchen Informationen. Dieses Argument wird bei jeder Diskussion über Das Tracking von Anwendern gebracht und es ist auch nicht falsch. Wenn man nicht weiß, wie ein Programm oder eine Internetseite genutzt wird, kann man schlecht optimieren und in die richtige Richtung entwickeln.
Man sollte daher nicht rundheraus jede Datenerhebung ablehnen, das ist realitätsfern (siehe: Warum Telemetrie-Daten notwendig sind). Wer aber Informationen haben möchte, sollte sich auch die Arbeit machen und die Datenerhebung sauber implementieren, sowie die Erhebung durch eigene Dienste durchführen.
Dazu gehört eine Wahlmöglichkeit für den Anwender, wie sie von jeder seriösen Software geboten werden sollte. Opt-In wäre wünschenswert, aber Opt-out ein gangbarer Kompromiss. Überhaupt nicht in Ordnung sind jene Dienste, die sich nur mittels eines Netzwerkfilters blockieren lassen.
Weiterhin darf man es sich nicht zu bequem machen und die vorgefertigten Bausteine der großen Trackinganbieter verwenden. Neben dem legitimen Informationsbedürfnis der Entwickler werden hier nämlich auch die Datenpools der riesigen IT-Giganten, die hinter den meisten dieser Trackingsdienstleister stehen, angereichert. Krakengleich durchziehen diese Anbieter bereits das Internet und auch bereits weitestgehend die mobilen App Stores.
Daher gilt sowohl für Entwickler, wie auch Webseitenbetreiber: Braucht ihr Informationen, lasst euren Anwendern die Wahl und erhebt eure Daten selbst. Mit Matomo (ehm. Piwik) gibt es dazu ja bereits ein praktikables Werkzeug, das datenschutzkonform eingesetzt werden kann.
Bilder:
Einleitungs- und Beitragsbild von kreatikar via pixabay / Lizenz: CC0 Creative Commons
Die Entscheidung der EU-Kommission vom 18. Juli 2018 Google eine Rekordstrafe für Praktiken rund um das Betriebssystem Android aufzuerlegen ist ein Meilenstein. Es gibt nun wieder ein bisschen Hoffnung für den Bereich der Mobilsysteme und Open Source.
Google steht momentan im besonderen Fokus der EU-Kommission. Dem aktuellen Verfahren ist bereits eine ebenfalls hohe Strafe im Bereich der Shoppingsuche vorausgegangen. Konkret moniert die EU Kommission vor allem, dass Smartphone-Hersteller, die den Play-Store ausliefern wollen, gleich ein ganzes Paket an Google-Diensten integrieren müssen. Wer zudem einmal ein solches Smartphone mit Google Apps ins Portfolio aufgenommen hat, darf gemäß den Lizenzbestimmungen keine alternativen Android-Distributionen nutzen. Google hat natürlich Widerspruch eingelegt und das ganze wird sich daher noch ein bisschen hinziehen.
Aus Sicht eines juristischen Laien ist die Selbstherrlichkeit der Silicon Valley Giganten überraschend. Glauben sie allen ernstes, dass Gesetze für sich nicht gelten? Gerade die Bündelung eines markbeherrschenden Betriebssystems mit Hersteller-Programmen ist kein neues Problem. Bereits vor vielen Jahren hat die EU Kommission hier gegenüber Microsoft Härte gezeigt, bis der Redmonder Konzern nach Milliarden-Bußgeldern in einem Vergleich die Browserwahl einführte. Man hätte bei Alphabet/Google also wissen können, dass es die EU ernst meint.
Für die Mobilsysteme und ein freies Ökosystem ist diese Entwicklung eine Chance. Google wird sicherlich noch ein wenig weiter prozessieren, aber der Microsoft-Fall legt die Vermutung nahe, dass man sich auf einen Vergleich einigen wird. Um die Presseberichterstattung von der Rekordstrafe weg zu lenken hat man in den letzten Tagen vermehrt Informationen zum Next Generation Betriebssystem Fuchsia lanciert. Alleine die anvisierten Zeitpläne zeigen jedoch, dass das nur Nebelkerzen sind. Wer weiß schon was in fünf Jahren für Hardware ausgeliefert wird, zumal die internen Entscheidungsprozesse noch nicht einmal abgeschlossen sind.
Kurz- und mittelfristig wird man im mobilen Segment weiterhin Android benötigen. Hier wird Google voraussichtlich eine Entkoppelung der Dienste und des Systems anstreben. Man kann zuversichtlich sein, dass viele Hersteller dann nur noch eine reduzierte Variante des Google-Pakets anbieten werden. Viele Smartphone-Hersteller experimentieren immerhin mit eigenen Diensten. Möglicherweise wird es sogar Produktlinien ohne Play Store und Google Dienste geben - man wird es sehen.
Bilder:
Einleitungs- und Beitragsbild von Pexels via pixabay / Lizenz: CC0 Creative Commons
New Tab Override ist eine Erweiterung zum Ersetzen der Seite, welche beim Öffnen eines neuen Tabs in Firefox erscheint. Die beliebte Erweiterung mit mehr als 120.000 aktiven Nutzern ist nun in Version 14.1 erschienen.
Was ist New Tab Override?
Seit Firefox 41 ist es nicht länger möglich, die Seite anzupassen, welche beim Öffnen eines neuen Tabs erscheint, indem die Einstellung browser.newtab.url über about:config verändert wird. Da diese Einstellung – wie leider viele gute Dinge – in der Vergangenheit von Hijackern missbraucht worden ist, hatte sich Mozilla dazu entschieden, diese Einstellung aus dem Firefox-Core zu entfernen. Glücklicherweise hat Mozilla nicht einfach nur die Einstellung entfernt, sondern gleichzeitig auch eine neue API bereitgestellt, welche es Entwicklern von Add-ons erlaubt, diese Funktionalität in Form eines Add-ons zurück in Firefox zu bringen.
New Tab Override war das erste Add-on, welches diese Möglichkeit zurückgebracht hat, und ist damit das Original. Mittlerweile hat New Tab Override mehr als 120.000 aktive Nutzer, wurde im Dezember 2016 sogar auf dem offiziellen Mozilla-Blog vorgestellt und schon mehrfach im Add-on Manager von Firefox beworben.
Bei Version 14.1 handelt es sich um ein kleineres Update. Wird in den Einstellungen der Erweiterung die Option „Benutzerdefinierte URL“ ausgewählt und keine URL in das entsprechende Feld eingetragen, so erscheint nun eine entsprechende Fehlermarkierung, welche erkennbar macht, dass hier noch etwas auszufüllen ist. Wird das Feld weiterhin leer gelassen, erscheint die Einstellungs-Seite von New Tab Override beim Öffnen eines neuen Tabs, so dass garantiert nicht mehr vergessen wird, die Konfiguration abzuschließen, und auch, um Probleme beim Öffnen eines neuen Tabs zu verhindern, da eine fehlerhafte Konfiguration eine Endlosschleife verursachen konnte.
Browser-Updates sind alleine aus Gründen der Sicherheit absolut wichtig und sollten nicht deaktiviert werden. Dennoch bietet Mozilla in Firefox eine Einstellung an, um Browser-Updates zu deaktivieren. Ab Firefox 63 funktioniert dies anders als bisher. Dieser Artikel zeigt, wie sich Firefox-Updates in Zukunft konfigurieren lassen.
Sicherheit sollte bei einem Browser für wirklich jeden die oberste Priorität haben. Dazu gehört auch, seinen Browser aktuell zu halten, indem alle Updates eingespielt werden. Nicht jedem ist klar: Sicherheits-Software ist kein Ersatz für Browser-Updates. Sicherheitslücken im Browser müssen durch Browser-Updates geschlossen werden, das ist alternativlos.
Ob es nun einen speziellen Grund gibt, die Updates zumindest kurzzeitig zu deaktivieren, oder ob einem Sicherheit vollkommen egal ist und man Updates dauerhaft deaktivieren möchte: Mozilla gibt dem Nutzer die Freiheit, dies selbst zu bestimmen. Bislang gibt es dazu in den Firefox-Einstellungen im Reiter „Allgemein“ drei mögliche Optionen: 1) Updates automatisch installieren, 2) Nach Updates suchen, aber vor der Installation nachfragen, 3) Nicht nach Updates suchen.
Ab Firefox 63 gibt es an dieser Stelle nur noch die ersten beiden Optionen. Neben der Standard-Einstellung, Updates automatisch zu installieren, kann also auch in Zukunft über die sichtbaren Optionen eingestellt werden, dass Firefox zwar nach Updates sucht, aber diese nicht installiert, ohne vorher zu fragen. Die sichtbare Option, gar nicht erst nach Updates zu suchen, fehlt allerdings komplett.
Auch in about:config muss nicht gesucht werden, denn der Schalter app.update.enabled , an welchen die sichtbare Option gekoppelt war, existiert ebenfalls nicht länger ab Firefox 63.
Ist ein vollständiges Deaktivieren der Firefox-Updates ab Firefox 63 nicht mehr möglich? Doch, ist es. Allerdings geschieht dies ab sofort über die Enterprise Policy Engine, genauer über die DisableAppUpdate-Policy. Dazu muss eine Datei mit dem Namen policies.json in einem Unterordner des Installationsverzeichnisses von Firefox abgelegt werden. Das ist nicht schwierig und mit dem Enterprise Policy Generator besonders einfach: einfach die Updates-Option auswählen, den Generieren-Button klicken und die generierte Datei in das Verzeichnis übernehmen, welches der Enterprise Policy Generator angibt.
Dieser Weg funktioniert übrigens bereits ab Firefox 62 sowie Firefox ESR 60.0.
Es gibt, was Firefox-Updates betrifft, also keinerlei funktionale Einschränkung in Firefox 63. Lediglich der Weg, um Updates vollständig zu deaktivieren, hat sich geändert und ist weniger offensichtlich als bisher. Wieso also diese Änderung?
Die Begründung ist denkbar simpel: es war bisher zu einfach, Updates zu deaktivieren. Nutzer, die das aus bestimmten Gründen mal gemacht haben, haben dies teilweise vergessen und sind daher unnötigerweise großen Gefahren ausgesetzt. Eine Einstellung, welche die Nutzer in Gefahr bringt, sollte nicht zu prominent angeboten werden. Dennoch ist hervorzuheben, dass Mozilla die Einstellung nicht einfach gestrichen hat, sondern bereits vor Entfernung einen neuen Weg bereitgestellt hat, um zum gleichen Ergebnis zu kommen. Und um vor der Installation von Updates gefragt zu werden, ändert sich sowieso überhaupt nichts, diese Einstellung bleibt weiterhin sichtbar. Der Nutzer behält also auch in Zukunft die volle Kontrolle über Firefox-Updates.
Abschließend sei aber noch ein weiteres Mal hervorgehoben, dass auch, wenn es weiterhin einfach ist, Firefox-Updates zu deaktivieren, es keinen guten Grund dafür gibt. Wie wichtig Sicherheit ist, wurde bereits mehrfach angesprochen. Gesagt sei auch, dass die Angst vor inkompatiblen Erweiterungen seit Erscheinen von Firefox Quantum kein Thema mehr ist, da es Erweiterungs-Inkompatibilitäten durch Firefox-Updates nur noch in Ausnahmefällen gibt. Neue Versionen bringt jedoch jedes Mal wieder neue Möglichkeiten für noch mehr und noch bessere Firefox-Erweiterungen, also auch als Nutzer von Firefox-Erweiterungen möchte man in der Regel Updates. Von den ständigen Geschwindigkeitsverbesserungen profitiert jeder Nutzer und natürlich ist das das wichtigste Merkmal eines Browsers: Web-Kompatibilität. Sehr viele Webseiten machen Gebrauch von aktuellen Webstandards und wer seinen Browser nicht aktualisiert, wird mit zunehmender Dauer immer mehr Webseiten nicht mehr richtig nutzen können. Es gibt also viele Gründe, seinen Browser aktuell zu halten, und nur wenige Argumente, dies nicht zu tun.
Splash Screens werden mitunter kontrovers diskutiert, sind aber üblicherweise Bestandteil größerer Anwendung wie auch GIMP. Dieses stellt eine ganz besondere Möglichkeit bereit, um auch diese anzupassen.
Ich kann mich ehrlich gesagt nicht mehr erinnern, wann ich darüber etwas gelesen habe, aber ich habe seit geraumer Zeit eigene benutzerdefinierte Splash Screens für GIMP auf meinem Rechner installiert. Dies geht überraschend einfach: einfach die entsprechenden Bilddateien im Ordner
~/.gimp-2.8/splashes
platzieren und GIMP starten. Beim Start wird dann, wenn sich mehrere Bilder im Ordner befinden, eins zufällig ausgewählt und anschließend angezeigt.
Splash Screens werden mitunter kontrovers diskutiert, sind aber üblicherweise Bestandteil größerer Anwendung wie auch GIMP. Dieses stellt eine ganz besondere Möglichkeit bereit, um auch diese anzupassen.
Ich kann mich ehrlich gesagt nicht mehr erinnern, wann ich darüber etwas gelesen habe, aber ich habe seit geraumer Zeit eigene benutzerdefinierte Splash Screens für GIMP auf meinem Rechner installiert. Dies geht überraschend einfach: einfach die entsprechenden Bilddateien im Ordner
~/.gimp-2.8/splashes
platzieren und GIMP starten. Beim Start wird dann, wenn sich mehrere Bilder im Ordner befinden, eins zufällig ausgewählt und anschließend angezeigt.
OpenSUSE Leap verfügt im Gegensatz zu Ubuntu über gut gepflegte Paketquellen, die aber auch nicht so umfangreich sind. Innerhalb einer Leap-Version werden jedoch manchmal Pakete verfügbar gemacht, von denen sich das Projekt in naher Zukunft verabschieden möchte. Dies soll den Übergang für Anwender erleichtern.
Identifizieren kann man solche Pakete mittels
$ zypper lifecycle
Im Idealfall zeigt das Ergebnis nur das anvisierte Supportende an. Im vorliegenden Fall als das der 15er-Reihe (30.11.2021) und das der aktuellen Minorversion 15.0 (30.11.2019) an. Sollten hier auch Pakete aufgelistet sein, muss man eine Migration einplanen um für künftige Upgrades gerüstet zu sein.
Die Leap 42-Serie enthielt z. B. noch MySQL, mahnte aber eine Migration auf MariaDB an. In Leap 15 ist MySQL nun nicht mehr enthalten.
Bilder:
Einleitungs- und Beitragsbild von dariolafelicia via pixabay / Lizenz: CC0 Creative Commons
Zum Schutz der eigenen Privatsphäre können Firefox-Nutzer einen Tracking-Schutz im Mozilla-Browser aktivieren. Für Firefox 63 plant Mozilla eine Erweiterung seines Schutzes. Aus dem Tracking-Schutz wird dann ein Content-Blocker.
Der Tracking-Schutz von Firefox, in der deutschen Version „Schutz vor Aktivitätenverfolgung“ genannt, hilft dabei, die eigene Privatsphäre besser zu schützen, und sorgt gleichzeitig für ein schnellere Laden von Webseiten. Ab Firefox 63 ist an dieser Stelle von Content Blocking die Rede. Der bisherige Tracking-Schutz wird dann eine Option des Content-Blockers. Eine weitere Option, die mit Firefox 63 ganz neu dazu kommen soll, wird die Möglichkeit sein, sämtliche Drittanbieter-Scripts zu blockieren, welche länger als fünf Sekunden zum Laden brauchen. Für beide Optionen kann der Nutzer unabhängig voneinander einstellen, ob diese immer, nur in privaten Fenstern oder nie zum Einsatz kommen sollen. Natürlich können wie bisher auch weiterhin Ausnahmen hinzugefügt werden.
Dies ist nur eine von mehreren Privatsphäre-Verbesserungen, an denen Mozilla derzeit für Firefox arbeitet. Bereits in Firefox 62 macht Mozilla den Tracking-Schutz über das Hauptmenü zugänglich und erlaubt ein einfaches Löschen aller Cookies einer Domain über das Info-Panel in der Adressleiste. Weiterhin plant Mozilla, den Cookie-Zugriff für Tracker einzuschränken.
Ich bin ja ein Fanboy von Fritz. Besonders gut finde ich auch die Fritzphones.
Wegen eines ISP wechsels mußte ich mir einen neuen Router aussuchen.
Ich habe mich für den 7590 entschieden. Vorher hatte ich Fritz!box 6390 Cable.
Mit dem 7590 hatte ich so meine Schwierigkeiten, Wlan verbinden klappte sehr gut, aber nach dem mein Notebook im Suspend to ram war, war ein reconnect unmöglich. Nur mit Fritzbox restart bzw. mit der WLan Taste aus/ein, konnte das behoben werden.
Auch eines meiner Android Spmartphones hatte Probleme, es behauptete immer Authentifizierungsproblem.
Der Softwarestand der 7590 war FRITZ!OS: 06.92. Ich habe mir die Labor Software fritzbox-7590-labor-59298 installiert, denn im Readme stand einiges in dieser Richtung.
Das Resultat mit dieser FRITZ!OS: 06.98-59298 BETA geradezu sensationell.
Endlich wieder rattenschnelles reconnect nach dem aufwachen des Laptops und auch das Android Smarphone meckert nicht mehr.
(Das war früher mit Debian Jessie auch schon mal so schnell, mit meinem Buster war es schon immer etwas langsamer)
Ist schon interessant, welchen Einfluß der Wifi Sender haben kann, es liegt nicht immer an den Clients, wie ich hier bemerken durfte.
Jetzt warte ich, bis die Preise für das 7590 runter gehen und hole mir eine zweite, damit hätte ich das Haus perfekt ausgeleuchtet.
Bislang gab es eine gemeinsame Erweiterungs-Plattform für Firefox, Firefox für Android, Thunderbird und SeaMonkey. Nun ging die neue Erweiterungs-Plattform für Thunderbird und SeaMonkey online, während addons.mozilla.org weiterhin die Erweiterungs-Plattform für Firefox und Firefox für Android bleibt.
Während Firefox und Firefox für Android Produkte sind, die von Mozilla aktiv entwickelt werden, handelt es sich bei Thunderbird und SeaMonkey um Community-Projekte, welche auf dem gleichen Unterbau wie Firefox basieren. Erweiterungen für Thunderbird und SeaMonkey konnten bislang ebenfalls wie Erweiterungen für Firefox und Firefox für Android auf addons.mozilla.org heruntergeladen werden. In Zukunft wird es Erweiterungen für Thunderbird und SeaMonkey stattdessen auf addons.thunderbird.net geben.
Bei addons.thunderbird.net handelt es sich um einen sogenannten Fork der Mozilla-Plattform addons.mozilla.org. Die neue Erweiterungs-Plattform für Thunderbird und SeaMonkey wird vom Thunderbird Council verwaltet und weiterhin auf Mozillas Infrastruktur betrieben. Da Firefox nur noch WebExtensions unterstützt, Mozilla eine Entfernung aller Legacy-Features von addons.mozilla.org noch in diesem Jahr anstrebt und Thunderbird sowie SeaMonkey auf absehbare Zeit weiterhin Legacy-Erweiterungen unterstützen, erfolgte nun aus technischen Gründen die Aufteilung auf zwei unterschiedliche Plattformen.
Alle Erweiterungen, die bisher auf addons.mozilla.org für Thunderbird oder SeaMonkey vorhanden waren, wurden auf die neue Seite übertragen. Für Nutzer, die bereits Erweiterungen installiert haben, ist keine Aktion erforderlich: Mozilla leitet alle Update-URLs um, so dass es keine Unterbrechung der automatischen Updates gibt. Weiterhin hat Mozilla Weiterleitungen der Erweiterungs-Seiten für Thunderbird-Erweiterungen auf addons.thunderbird.net eingerichtet.
Mit Veröffentlichung der ersten Devolo Unterputz-Module, Schalter und Dimmer, hat natürlich auch Kevin in die Tasten gehauen und sein Devolo-Plugin für Homebridge aktualisiert. # Installation npm install homebridge-devolo -g --unsafe-perm # Update npm update homebridge-devolo -g --unsafe-perm „Hey Siri, schalte das Licht in der Garage an“ schaltet bei uns die LED Leuchtstoffröhre in der Garage an, … Update für Unterputz-Module – Devolo Plugin für Homebridge – Apple HomeKit weiterlesen
Ich habe heute Abend etwas mit KeepassXC und KeepassXC-Browser herumgespielt und KeepassXC im Terminal Emulator gestartet. Nun wollte ich diesen beenden ohne das KeepassXC beendet wird.
Da ich KeepassXC ganz normal mit keepassxc gestartet habe, würde das Schließen des Terminal Emulators auch das Beenden von KeepassXC bedeuten. Aber dies lässt sich wie folgt verhindern.
Strg + Z
bg
disown %1
Mit der ersten Zeile legen wir den Prozess schlafen. Mit der zweiten Zeile befördern wir den Prozess in den Hintergrund. Und mit der dritten Zeile lösen wir den Prozess vom Terminal Emulator ab. Nun kann man das Fenster des Terminal Emulators einfach schließen und der Prozess läuft unabhängig davon weiter.
New Tab Override ist eine Erweiterung zum Ersetzen der Seite, welche beim Öffnen eines neuen Tabs in Firefox erscheint. Die beliebte Erweiterung mit mehr als 120.000 aktiven Nutzern wurde von Mozilla als eine von nur neun Erweiterungen als Teilnehmer einer Übersetzungs-Kampagne ausgewählt und ist nun in Version 14.0 mit neuen und überarbeiteten Übersetzungen erschienen.
Was ist New Tab Override?
Seit Firefox 41 ist es nicht länger möglich, die Seite anzupassen, welche beim Öffnen eines neuen Tabs erscheint, indem die Einstellung browser.newtab.url über about:config verändert wird. Da diese Einstellung – wie leider viele gute Dinge – in der Vergangenheit von Hijackern missbraucht worden ist, hatte sich Mozilla dazu entschieden, diese Einstellung aus dem Firefox-Core zu entfernen. Glücklicherweise hat Mozilla nicht einfach nur die Einstellung entfernt, sondern gleichzeitig auch eine neue API bereitgestellt, welche es Entwicklern von Add-ons erlaubt, diese Funktionalität in Form eines Add-ons zurück in Firefox zu bringen.
New Tab Override war das erste Add-on, welches diese Möglichkeit zurückgebracht hat, und ist damit das Original. Mittlerweile hat New Tab Override mehr als 120.000 aktive Nutzer, wurde im Dezember 2016 sogar auf dem offiziellen Mozilla-Blog vorgestellt und schon mehrfach im Add-on Manager von Firefox beworben.
Insgesamt neun Erweiterungen wurden im Rahmen einer Übersetzungs-Kampagne von Mozilla durch die freiwillige Übersetzer-Community in die Top-Sprachen übersetzt und bestehende Übersetzungen überarbeitet. Eine der Erweiterungen, die sich Mozilla dafür ausgesucht hat, ist New Tab Override. Außerdem gab es neue Übersetzungen für AdBlock für Firefox, 1-Click YouTube-Video-Downloader, Download Flash and Video, Greasemonkey, NoScript, „Merken“-Button von Pinterest, signTextJS plus sowie To Google Translate.
Während die Anzahl der Erweiterungen, welche auf diese Weise neue Übersetzungen erhalten konnten, sehr begrenzt war, hofft Mozilla, die Möglichkeit, Erweiterungen von der Community über eine Übersetzungs-Plattform übersetzen zu lassen, in naher Zukunft allen interessierten Entwicklern zur Verfügung stellen zu können.
Die Neuerungen von New Tab Override 14.0
Da New Tab Override bereits in einige Top-Sprachen übersetzt war, gibt es in diesem Update „nur“ zwei komplett neue Übersetzungen für New Tab Override. Die Erweiterung steht ab sofort auch in den Sprachen Italienisch und Brasilianisches Portugiesisch zur Verfügung. Weiterhin wurden die Französische, Chinesische sowie die Spanische Übersetzung aktualisiert. In Summe gibt es also fünf Übersetzungs-Updates. Neben der Erweiterung selbst wurde außerdem auch der Eintrag auf addons.mozilla.org übersetzt. Insgesamt steht New Tab Override derzeit in elf Sprachen zur Verfügung.
Abseits von Übersetzungen gab es auch noch eine Neuerung in New Tab Override 14.0: die beiden Optionen für die Standard-Startseite „about:home“ und die komplett leere Seite „about:blank“ wurden aus der Erweiterung entfernt. Zum einen sind diese Optionen seit Firefox 60/61 nicht mehr via WebExtension-API aufrufbar, zum anderen sind beide Optionen spätestens seit Firefox 61 nicht mehr notwendig, weil es für beides sichtbare Optionen in den Firefox-Einstellungen gibt und das sogar komplett ohne Erweiterung.
Entwickler, Webseitenbetreiber, Firmen & Co wollen über ihre Nutzer respektive Kunden gerne viel wissen. Nachdem man schnöde Internetaktivitäten schon lange nicht mehr ohne entsprechenden Blocker (Werbeblocker greift hier als Begriff viel zu kurz!) nutzen kann, geraten nun Apps und herkömmliche Programme in den Fokus. Wer glaubt, die Nutzung von Open Source-Apps schütze ihn ist auf dem Holzweg.
Auf Exodus kann man einzelne Apps unter die Lupe nehmen. Dabei handelt es sich um Analysen von Apps für Android, die ggf. in unterschiedlichen Versionen vorliegen und eine sehr lange Liste an Trackern erkennt.
Eine unsystematische Durchsicht, sowie ein Vergleich von beliebten proprietären Apps und Open Source Lösungen zeigt, dass der Open Source Gedanke keineswegs vor der Einbindung von Trackingdiensten schützt. Zur Verdeutlichung einige Beispiele prominenter Apps. Die Informationen zu den Trackern stammen von Exodus und berücksichtigen nicht, ob sich diese Dienste z. B. per Opt-out in den Einstellungen abschalten lassen.
Open Source Software mit Trackingdiensten:
Firefox: 4 Tracker (Adjust, Google Analytics, Google Firebase Analytics, Leanplum)
Entwickler, Webseitenbetreiber, Firmen & Co wollen über ihre Nutzer respektive Kunden gerne viel wissen. Nachdem man schnöde Internetaktivitäten schon lange nicht mehr ohne entsprechenden Blocker (Werbeblocker greift hier als Begriff viel zu kurz!) nutzen kann, geraten nun Apps und herkömmliche Programme in den Fokus. Wer glaubt, die Nutzung von Open Source-Apps schütze ihn ist auf dem Holzweg.
Auf Exodus kann man einzelne Apps unter die Lupe nehmen. Dabei handelt es sich um Analysen von Apps für Android, die ggf. in unterschiedlichen Versionen vorliegen und eine sehr lange Liste an Trackern erkennt.
Eine unsystematische Durchsicht, sowie ein Vergleich von beliebten proprietären Apps und Open Source Lösungen zeigt, dass der Open Source Gedanke keineswegs vor der Einbindung von Trackingdiensten schützt. Zur Verdeutlichung einige Beispiele prominenter Apps. Die Informationen zu den Trackern stammen von Exodus und berücksichtigen nicht, ob sich diese Dienste z. B. per Opt-out in den Einstellungen abschalten lassen.
Open Source Software mit Trackingdiensten:
Firefox: 4 Tracker (Adjust, Google Analytics, Google Firebase Analytics, Leanplum)
In vielen Software-Projekten, die länger als ein Jahr leben, gibt es eine Software-Architektur. Nicht immer sieht man sie sofort im Code, nicht immer entspricht die Realität dem Angedachten und sehr oft ist rein gar nichts dazu dokumentiert. Vor allem der letzte Punkt soll sich durch das Buch „arc42 in Aktion – Praktische Tipps zur Architekturdokumentation“ von Gernot Starke und Peter Hruschka bessern.
arc42-Template
Wer es nicht kennt: arc42 ist eine Vorlage für die Entwicklung, Dokumentation und Kommunikation von Software-Architekturen. Mit Template ist dabei keine Vorlage gemeint, die man strikt befolgt und ausfüllt, sondern es gibt eine Gliederung und Hinweise, welche Inhalte eine Architektur-Dokumentation haben kann und sollte.
Das Buch setzt genau dort an und stellt jedes Kapitel des Templates im Detail vor, welches Ziel damit verfolgt wird und wem es etwas nützt. Das Ganze an einem kleinen Beispiel, damit man die Vorlage auch einmal ausgefüllt sieht. Dabei muss man natürlich vor allem als Dokumentschreiber selbst abwägen, welche Teile man übernimmt und welche nicht. Das können die Autoren des Buches einem nicht abnehmen, aber sie geben wie gesagt Hinweise, was sinnvoll sein könnte.
Ich zähle hier nicht auf, wie das arc42-Template aufgebaut ist und welche Teile es enthält. Das kann man auf der Webseite nachschlagen. Positiv erwähnen will ich die Lizenz, denn das Template steht unter der Creative Commons Attribution Lizenz und darf damit von jeder Person frei benutzt, abgeändert und weiterverteilt werden. Nur die Originalquelle muss man angeben, wenn man sich darauf abstützt, was aber kein großes Problem sein sollte. Der Download steht für verschiedene Formate wie Office, LaTeX, Markdown oder HTML zur Verfügung.
Auch für Nicht-arc42-Nutzer
Besonders gefallen hat mir an dem Buch, dass der Sinn hinter der einzelnen Kapitel des arc42-Templates erklärt wird. Damit versteht man nämlich die Hintergründe, auch wenn man nicht arc42 als Template benutzt. So kann man sich sehr leicht einzelne Elemente, die einem zusagen, für die eigene Vorlage übernehmen.
Aus dem Grund fand ich vor allem Kapitel III „Grundregeln effektiver Dokumentation“ so wertvoll. Hier geht es wirklich um die Fallstricke für gute – und damit ist wertschöpfend gemeint – Dokumentation und wie man mit Problemen umgehen kann.
Aber natürlich kochen auch die Autoren bzw. die Entwickler des arc42-Templates nur mit Wasser. Nicht alles, was ich in dem Buch gelesen habe, halte ich für richtig. Nicht alles, was in der arc42-Vorlage steht, für sinnvoll. Alles in allem hat das Buch aber einen Mehrwert für jeden, der Architektur-Dokumente schreibt.
Nachtrag: Für mich sind die Grenzen zwischen Design und Architektur fließend. Aus dem Grund unterscheide ich nicht zwischen Architektur- und Design-Dokumenten. Deswegen können alle Tipps aus dem Buch fast eins zu eins für Design-Dokumente – oder allgemein fast jede Art von Dokumentation – übernommen werden.
In vielen Software-Projekten, die länger als ein Jahr leben, gibt es eine Software-Architektur. Nicht immer sieht man sie sofort im Code, nicht immer entspricht die Realität dem Angedachten und sehr oft ist rein gar nichts dazu dokumentiert. Vor allem der letzte Punkt soll sich durch das Buch „arc42 in Aktion – Praktische Tipps zur Architekturdokumentation“ von Gernot Starke und Peter Hruschka bessern.
arc42-Template
Wer es nicht kennt: arc42 ist eine Vorlage für die Entwicklung, Dokumentation und Kommunikation von Software-Architekturen. Mit Template ist dabei keine Vorlage gemeint, die man strikt befolgt und ausfüllt, sondern es gibt eine Gliederung und Hinweise, welche Inhalte eine Architektur-Dokumentation haben kann und sollte.
Das Buch setzt genau dort an und stellt jedes Kapitel des Templates im Detail vor, welches Ziel damit verfolgt wird und wem es etwas nützt. Das Ganze an einem kleinen Beispiel, damit man die Vorlage auch einmal ausgefüllt sieht. Dabei muss man natürlich vor allem als Dokumentschreiber selbst abwägen, welche Teile man übernimmt und welche nicht. Das können die Autoren des Buches einem nicht abnehmen, aber sie geben wie gesagt Hinweise, was sinnvoll sein könnte.
Ich zähle hier nicht auf, wie das arc42-Template aufgebaut ist und welche Teile es enthält. Das kann man auf der Webseite nachschlagen. Positiv erwähnen will ich die Lizenz, denn das Template steht unter der Creative Commons Attribution Lizenz und darf damit von jeder Person frei benutzt, abgeändert und weiterverteilt werden. Nur die Originalquelle muss man angeben, wenn man sich darauf abstützt, was aber kein großes Problem sein sollte. Der Download steht für verschiedene Formate wie Office, LaTeX, Markdown oder HTML zur Verfügung.
Auch für Nicht-arc42-Nutzer
Besonders gefallen hat mir an dem Buch, dass der Sinn hinter der einzelnen Kapitel des arc42-Templates erklärt wird. Damit versteht man nämlich die Hintergründe, auch wenn man nicht arc42 als Template benutzt. So kann man sich sehr leicht einzelne Elemente, die einem zusagen, für die eigene Vorlage übernehmen.
Aus dem Grund fand ich vor allem Kapitel III „Grundregeln effektiver Dokumentation“ so wertvoll. Hier geht es wirklich um die Fallstricke für gute – und damit ist wertschöpfend gemeint – Dokumentation und wie man mit Problemen umgehen kann.
Aber natürlich kochen auch die Autoren bzw. die Entwickler des arc42-Templates nur mit Wasser. Nicht alles, was ich in dem Buch gelesen habe, halte ich für richtig. Nicht alles, was in der arc42-Vorlage steht, für sinnvoll. Alles in allem hat das Buch aber einen Mehrwert für jeden, der Architektur-Dokumente schreibt.
Nachtrag: Für mich sind die Grenzen zwischen Design und Architektur fließend. Aus dem Grund unterscheide ich nicht zwischen Architektur- und Design-Dokumenten. Deswegen können alle Tipps aus dem Buch fast eins zu eins für Design-Dokumente – oder allgemein fast jede Art von Dokumentation – übernommen werden.
Tracking ist ein Phänomen, das meistens mit der Werbeindustrie und dem Internet in Verbindung gebracht wird. Das Phänomen betrifft jedoch auf Apps auf Mobilplattformen und immer mehr auch den Desktop. Litte Snitch zeigt das wahre Ausmaß auf dem Mac.
Dier Netzwerkverkehr hiesiger Systeme wird mittels Little Snitch gefiltert (siehe: Little Snitch 4 - macOS-Traffic im Blick). Nicht weil man damit ausgefeilte Schadsoftware bekämpfen kann - diese weiß sich schließlich zu tarnen - sondern, weil die kleine Petze jene Entwicklersünden aufzeigt um die es hier gehen soll.
Ausgefeiltes Tracking ist vor allem ein Internetphänomen (siehe: Tracking - Wenn dein eigener Browser dich verfolgt und allgemein Aktivitäten im Internet schützen) aber weil die Module leicht zu integrieren sind, greifen immer mehr Entwickler auf diese zurück. Im mobilen Bereich zeigt Exodus das Ausmaß der Verfolgung. Neben zahlreichen Verbindungen zu sozialen Netzwerken & Co wird gerne auf Analysetools zur Statistikerhebung und s. g. Tool zum "crash reporting" verwendet. Das ganze hat grenzenlose Ausmaße angenommen, manche Apps integrieren gleich mehrere dieser Tools.
"Crash reporting", also zu deutsch in etwa Absturzbericht, hört sich wunderbar technisch an und der unbedarfte Nutzer mag da einen Sinn hinter sehen. Die meisten dieser Werkzeuge können aber viel mehr. Verbreitung und Nutzungsdaten lassen sich damit mühelos erfassen. Viele verbreitete Dienste wie beispielsweise Crashlytics oder HockeyApp gehören zudem zu großen IT-Konzernen und reichern potenziell deren Datenpool an. Die Kaufpreise hat man ja nicht umsonst investiert.
Auf dem Desktop kann man sich mittels Werkzeuge wie Little Snitch oder auch einem Pi-Hole gegen viele dieser Spionagewerkzeuge schützen, mobil sieht das ganz anders aus. Insbesondere bei mobilen Datenübertragungen sind auf den hochgradig geschlossenen Systemen den Kontrollmöglichkeiten enge Grenzen gesetzt.
Natürlich kann man nachvollziehen, dass App-Entwickler Daten haben wollen um ihre Entwicklung benutzerorientiert voran zu treiben. Aber ist es so schwer in den Einstellungen ein Opt-out anzubieten? Hier fehlt jedes Problembewusstsein bei den Entwicklern. Daten werden erhoben, weil man es kann, weil die Dienste nichts kosten und weil die Entwicklungsbausteine verfügbar sind. Benutzerinteressen spielen keine Rolle.
Man sollte dabei auch nicht dem Glauben erliegen, dass dieses Problem nur Apps und Programme, die eh kein vernunftbegabter Anwender nutzt, betrifft. Die jüngst bekannt gewordene Datenerhebung durch den - bisher als vertrauenswürdig - bekannten Messenger Wire (siehe: Verschlüsselte (Video-)Kommunikation mit Wire) zeigt das Ausmaß der laxen Handhabung des Themas bei vielen Entwicklern. Unter macOS haben zahlreiche Apps solche Tracker integriert, auf den hiesigen Systemen geschätzt ein Drittel der Drittprogramme. Im mobilen Bereich sieht das noch viel schlimmer aus. Interessant wäre hier mal Linux unter die Lupe zu nehmen.
Bilder:
Einleitungs- und Beitragsbild von kreatikar via pixabay / Lizenz: CC0 Creative Commons
Retrocomputing ist in. Wer, wie ich, seine ersten Erfahrungen mit Computern in den 80er Jahren gemacht hat, ist für dieses Thema besonders empfänglich. Dabei ist der Blick zurück häufig ziemlich verklärt und die alte Zeit wird als die bessere angesehen. Dabei wird übersehen, dass früher nicht alles eitel Sonnenschein war. Der folgende Artikel bezieht sich allein auf meine Erfahrungen, welche sehr stark von Heimcomputern und PCs mit MS-DOS geprägt wurden und weniger von Konsolen. Ich habe exemplarisch das Jahr 1992 als Grundlage des Artikels genommen, wobei ich auch spätere Jahre (bis ca. 1997) anspreche um bestimmte Sachverhalte zu verdeutlichen.
Kurze Biographie meinerseits: Jahrgang 1977. Der erste C64 irgendwann im Jahr 1988. Im Oktober 1990 folgte ein Atari ST mit 1 MB RAM, im Mai 1992 dann ein PC (AMD 386SX25 CPU, 1 MB RAM und 40 MB HDD).
Warum ausgerechnet 1992? Weil ich in diesem Jahr meinen ersten PC gekauft habe und zusätzlich weil zu diesem Zeitpunkt der Computermarkt noch sehr viel heterogener war als heute. Neben den PCs waren noch sehr häufig Heimcomputer (Amiga, Atari ST oder C64) im Einsatz und viele Spiele und Programme wurden noch für mehrere Plattformen entwickelt. Zudem war der Leistungsunterschied zwischen den PCs und den Heimcomputern noch nicht so groß, obwohl Letztere mit der breiten Verfügbarkeit von 386er CPUs und VGA-Grafikkarten ins Hintertreffen gerieten.
Hier mal einige Punkte, welche meine Sicht auf die damalige Hardware und Software aufzeigen soll:
Die Hardware damals war sehr teuer
Mein erster PC (Den ich mir von meinem Konfirmationsgeld gekauft hatte) kostete damals im Mai 1992 2000 DM. Die Ausstattung (siehe obigen Kasten) war eher unterdurchschnittlich und von High-End weit entfernt. Der PC hatte zwei Diskettenlaufwerke und keine (!) Soundkarte. Diese habe ich mir im Oktober 1992 zusammen einem CD-ROM-Laufwerk angeschafft. Rechnet man den Kaufpreis von 2000 DM auf die heutige Kaufkraft um, kommt man auf ca. 1.650€ (Errechnet mit DM-Euro-Rechner). Für diesen Betrag bekommt man heute einen ziemlich guten PC inklusive eines guten Monitors.
Damals gab es eine Faustregel:
Für einen brauchbaren PC mit Monitor musste man mindestens 2000 DM ausgeben, für weniger Geld gab es nur veraltete Hardware, welche nicht mehr zeitgemäß war und moderne Programme mehr schlecht als recht ausführen konnte. Wer mehr fühlbare Leistung benötigte oder einen schnellen Mac, Amiga oder Atari wollte, musste deutlich mehr als 4000 DM ausgeben. High-End-PCs, Macs oder Unix-Workstations kosteten über 10000 DM. Vergleicht man die Situation mit heute, stellt sich die Gegenwart quasi als Paradies dar: Einsteiger-PCs bekommt man für unter 300 €, Einsteiger-Spiele-PCs für 500 € (jeweils ohne Monitor). Ab 1000 € bekommt man PCs, die für alle Anwendungen uneingeschränkt tauglich sind, ein High-End-PC mit 16 Kernen ist ab 2000 € verfügbar. Dabei reicht selbst die Rechenleistung eines 300 €-PCs locker aus um alle alltäglichen Aufgaben problemlos zu erledigen.
Der Rechner war immer zu schlecht ausgestattet
Die CPU meines ersten PCs hatte eine 386SX-CPU, was heißt, dass die CPU intern mit 32bit-breiten Registern arbeitete, aber nur einen 16 Bit breiten externen Datenbus und einen 24 Bit breiten Adressbus hatte (Der 386DX war durchgängig 32bit). Dadurch war er deutlich langsamer als ein 386DX mit gleicher Taktfrequenz (ca. 25%) und der maximale Speicherausbau war auf 16 MB beschränkt. Er war im Grunde nicht schneller als eine gleich getaktete 286-CPU, hatte aber den Vorteil, dass er ein echter 32bit-Prozessor war und dadurch echte 32bit-Betriebssysteme ausführen konnte. Schon direkt nach dem Kauf des PCs konnte ich viele Spiele nur mit Einschränkung spielen (Wing Commander 2 lief z.B. sehr zäh), weshalb das Mainboard relativ schnell gegen eines mit einem 386DX40 ersetzt wurde. Ein weiteres Problem war, dass der verfügbare Speicher (Egal ob RAM oder HDD) immer zu klein war. Windows benötigte mindestens 1 MB RAM, besser waren 2 MB. Bei OS/2 waren schon mindestens 4 MB notwendig, wobei man damit nicht viel mit dem System anfangen konnte, da es permanent am Swappen war. Besser waren 8 MB oder sogar 16 MB und das zu Zeiten wo in den PCs gerade 4 MB zum Standard wurden. Es dauerte noch Jahre bis PCs den Speicherhunger moderner Betriebssysteme befriedigen konnten und das System sich mangels RAM nicht mehr selbst ausgebremst hat. PC-Spiele wie Comanche und DOOM benötigten 1993 mindestens 4 MB RAM, um überhaupt zu starten und verlangten nach mindestens einem 486SX25 um auf spielbare Frameraten zu kommen. Oben genannter 386DX40, den ich zu diesem Zeitpunkt besaß, war für DOOM schon viel zu langsam und ich hatte nur die Wahl zwischen „Guckschlitz“ oder „Riesenpixel“.
Noch schlimmer sah es bei der Festplatte aus:
Meine damalige 40 MB Platte war im Grunde immer voll. Ich habe mir damals Wing Commander 2 von einem Freund ausgeliehen und dieses benötigte mit „Speech Pack“ 36 MB. Neben der DOS-Installation war also kein Platz mehr für andere Dinge. Ich war also permanent am Installieren und Kopieren. Die verfügbaren Festplattenkapazitäten stiegen zwar rasant an und die Kosten fielen ebenso rasant, aber im gleichen Maß stieg auch die Größe der Programme an.
Schaut man sich heute die Situation an, leben wir im Luxus:
4 GB RAM sind selbst in Billigrechnern verbaut, 8 GB Standard. Festplatten unter 1 TB Kapazität bekommt man fast nirgends mehr zu kaufen bzw. sind im Vergleich zu größeren Festplatten deutlich teuer. Die meisten Anwender kommen auch mit „kleinen“ 256 GB SSDs gut zurecht. Man muss heutzutage nur noch selten mit dem Plattenplatz haushalten. Mein beiden PCs (Desktop und Notebook) haben jeweils 16 GB RAM und eine 256 GB SSD und ich komme trotz meines Bioinformatikstudiums selten in die Situation, dass dieser Speicher nicht mehr ausreicht (Ein Beispiel dafür folgt in den nächsten Tagen).
Die Ergonomie der Bildschirme war grausam
Windows NT 4.0SP6 (2001), OpenStep 4.2 (1997), Slackware 1.1.2 mit FVWM (1994), Auflösung jeweils 1024×768 Bildpunkte
Mein damaliger PC wurde mit einem 14-Zoll Monitor ausgeliefert, der gerade mal eine Auflösung von 640×480 Bildpunkten bei 60 Hz schaffte. Die Bildqualität war mies und ich habe den Monitor auch nur ertragen, weil ich nichts Besseres kannte bzw. mir nichts besseres leisten konnte. Zum Spielen reichte der Monitor locker aus, da man bis Mitte der 90er eh meistens in der VGA-Auflösung mit 320×200 Bildpunkten gespielt hat. Bei solch einer geringen Auflösung spielte es keine große Rolle, wenn die Pixel etwas „matschig“ aussahen. Ein Problem wurden die billigen PC-Monitore zu dem Zeitpunkt als Windows zum Standard wurde. Eine Auflösung von 640×480 Bildpunkten genügte für einfache Arbeiten, wer aber Windows wirklich benutzen wollte, musste mindestens eine Auflösung von 800×600 Bildpunkten benutzen und da wurde es bei den 2000 DM-PCs ziemlich übel. Mein 14-Zoll-Monitor konnte diese Auflösung z.B. nur mit 56 Hz darstellen, eine höhere Auflösung (1024×768) war nur mit 43 Hz im Interlaced-Modus möglich. Also nichts, was auch nur ansatzweise als ergonomisch zu bezeichnen wäre. Ein guter Monitor kostete damals mehr als 1000 DM, einen Betrag, den ich mir nicht leisten konnte.
Wichtig wurde die Auflösung des Monitors für mich, als ich damals Linux entdeckte:
Während man Windows 3.1 und später Windows 95 relativ problemlos mit einer Auflösung von 640×480 Bildpunkten betreiben und mit 800×600 Bildpunkten gut arbeiten konnte, war daran unter Linux mit einer grafischen Oberfläche nicht zu denken. Das lag daran, dass X11 bzw. das „X Window System“ zuerst auf professionellen Unix-Workstations eingesetzt wurde und dort Auflösungen unter 1024×768 Bildpunkten quasi nicht existent waren. Also wurden die Programme bzw. die Widgets der eingesetzten Toolkits auch nicht für kleinere Auflösungen optimiert (Siehe Collage rechts). Einer der Hauptgründe warum ich mir einen besseren Monitor zulegte, war diesem Umstand geschuldet. Heutzutage sitzen die allermeisten PC-Besitzer vor einem flimmerfreien und hochauflösenden TFT-Monitor. Selbst bei Billig-Notebooks bekommt man mindestens eine Auflösung von 1366×768 Bildpunkten, Standard ist aber die Full-HD-Auflösung mit 1920×1080 Bildpunkten.
Die richtige Wahl der RAM-Verwaltung war ein Abenteuer
Im Jahr 1992 gab es für Heimanwender im PC-Bereich im Grunde nur ein Betriebssystem und zwar DOS. Ich nenne es absichtlich nicht MS-DOS, da z.B. mein damaliger PC mit Digital Research „DR DOS 5.0“ ausgeliefert wurde. Es gab damals noch ein gutes Dutzend weitere kompatible Versionen von verschiedenen Herstellern:
Es gab zwar modernere und bessere Alternativen (Windows NT, OS/2 oder ein kommerzielles Unix), diese benötigten aber einen leistungsfähigen Rechner und/oder kosteten ein Vermögen in der Anschaffung. Das größte Problem mit DOS war die Trennung des Speichers in verschiedene Bereiche. Für jemanden, wie mich, der vorher einen ATARI ST benutzt hat, war das eine neue Welt, da es beim ST keine Trennung des Speichers gab. Der ST konnte schon 1985 mit bis zu 4 MB RAM ausgestattet werden und der RAM war einfach verfügbar. Der wichtigste Speicherbereich für DOS war der Speicherbereich bis 640 kB, welcher von den normalen DOS-Programmen benutzt wurde. Ich spare mir hier weitere Details und verweise auf den passenden Wikipedia-Artikel:
Speicher oberhalb von 1 MB wurde auf hauptsächlich auf zwei Arten angesprochen:
Ältere Programme benötigten EMS-Speicher als zusätzlichen Speicher, neuere wollten aber XMS-Speicher (HIMEM.SYS, notwendig z.B. für Windows 3.x) . Dazu kamen dann noch Programme, welche den Speicher direkt adressieren konnten und einen sogenannten DOS-Extender einsetzten, welche aber nicht kompatibel zu EMS bzw. „EMM386.EXE“ waren (Emulierter EMS-Speicher war nicht mehr als XMS-Speicher verfügbar). Also fingen wir DOS-Benutzer an mit verschiedenen Boot-Disketten zu hantieren, welche unterschiedliche Konfigurationen vorhielten („CONFIG.SYS“ und „AUTOEXEC.BAT„). Auf der Festplatte lag die Konfiguration, welche von den meisten Programmen unterstützt wurde. Es wurde quasi zum Sport die beste Konfiguration, mit dem meisten verfügbaren Speicher unterhalb von 640 kB zu erstellen. Die diversen Hersteller von DOS-Betriebssystemen warben damals auch ziemlich offensiv mit diesen Zahlen. Mit dem Erscheinen von MS-DOS 6.0 konnte man sogenannte „Boot-Menüs“ anlegen, welche es ermöglichten beim Booten die jeweils benötigte Konfiguration in den Dateien „CONFIG.SYS“ und „AUTOEXEC.BAT“ auszuführen. Dadurch wurde der Einsatz von Bootdisketten hinfällig, aber nicht das Basteln an den Konfigurationen. Als größter Fallstrick sollten sich Spiele erweisen. 1992 wurde z.B. „Ultima 7“ veröffentlicht, welches einen eigenen Speichermanager implementierte und nicht mit EMS und XMS zurechtkam. Dazu kam noch, dass sehr viel Speicher unterhalb von 640 kB frei sein musste (620 kB, wenn ich mich richtig erinnere), damit das Spiel überhaupt startete. Das war gerade für deutsche Anwender ein Problem, da man hierzulande üblicherweise den deutschen Tastaturtreiber geladen hatte, welcher ca. 10kB verschlungen hat. Dazu kamen noch ca. 50 kB für die CD-ROM-Treiber und das Programm MSCDEX.EXE. Wer dieses Spiel spielen wollte, musste dafür eine eigene Konfiguration basteln, die im Grunde nur den Maustreiber geladen hat (Welcher üblicherweise 10 kb benötigte). Im Laufe des Jahres 1993 kamen dann die ersten Spiele auf den Markt, welche den DOS-Extender „DOS4GW.EXE“ benutzten. Spiele, welche EMS-Speicher benötigten, starben danach sehr schnell aus, was dazu führte, dass man die EMS-Konfiguration nur noch selten benötigte. Das Thema sollte aber Windows 95-Anwender noch ein paar Jahre verfolgen, da dieses Betriebssystem DOS zum Starten benötigte. Wollte man ein älteres Programm, welches EMS-Speicher benötigte unter Windows 95 starten, musste man in der „CONFIG.SYS“ den EMS-Speicher über „EMM386.EXE“ aktivieren. Dieser Speicher stand dann aber Windows 95 nicht mehr zur Verfügung. Man war also immer noch auf DOS-Basteleien angewiesen. Die Bastelei mit dem Speicher hatte erst ein Ende, als die meisten Entwickler auf die Win32-API umgestiegen waren bzw. Windows XP erschien. Heutzutage macht sich kein Mensch mehr Gedanken über die Speicheraufteilung. RAM ist einfach da und wird benutzt.
Treiber waren ein Abenteuer
Hier muss ich zwischen zwei Dingen unterscheiden:
Der Hardware bzw. Treiberkonfiguration.
Woher man den Treiber bekam.
Die Hardwarekonfiguration musste von Hand vorgenommen werden
In Zeiten vor PCI und Plug’n Play und zu Zeiten von DOS hatten PCs 16 IRQs (Interruptleitungen). Diese waren von 0 bis 15 durchnummeriert. Jedes Gerät und jede Erweiterungskarte benötigte üblicherweise einen dieser IRQs. Die Anzahl von 16 klingt erst einmal nach relativ viel, man muss aber bedenken, dass über die Hälfte von ihnen schon standardmäßgi vergeben waren. Eine Liste ist z.B. hier zu finden:
Ein großes Problem war, dass die damaligen Karten keine Autokonfiguration kannten und man bei den meisten Karten vor dem Einbau die passende Steckbrücke auf der Karte setzen musste. Gerade Anfänger wussten sehr häufig nicht, welche IRQs man verwenden musste bzw. welche noch zur freien Verfügung standen. Bei nur einer Erweiterungskarte spielte die IRQ-Problematik keine große Rolle, aber je mehr Karten man einbaute (Bei mir war damals z.B. eine Soundkarte und der Controller für mein CD-ROM-Laufwerk verbaut. Später kam dann eine Netzwerkkarte dazu), desto kritischer wurde die Situation. Dazu kam noch, dass jede Karte eine passende Hardwareadresse und oft auch einen DMA-Kanal benötigte. Je mehr Karten man im Rechner verbaut hatte, desto unübersichtlicher wurde die Situation. Amiga und Mac-Besitzer konnten damals nur müde über PC-Besitzer und ihre Probleme lächeln, da beide Rechnertypen schon immer „Plug’n Play“ bei ihren Erweiterungskarten unterstützten. Im Laufe des Jahres 1994 wurden die ersten PCs und ISA-Karten mit „Plug’n Play“-Unterstützung auf den Markt gebracht. Diese erlaubten eine Autokonfiguration der IRQs auch unter DOS (Wobei ein Zusatzprogramm benötigt wurde), trotzdem war deren Konfiguration für die meisten Benutzer aber genauso ein Gefrickel, da parallel dazu immer noch die alten Karten im Einsatz waren und man deren IRQs händisch blocken musste. Mit dem Erscheinen von Windows 95 (Integriertes „Plug’n Play“) und dem breiten Einsatz von PCI-Karten (Diese unterstützen Interrupt-Sharing) verlor das Thema langsam an Bedeutung. Heutzutage spielen IRQ -und Adresskonflikte keine Rolle mehr. Die Hardware wird einfach vollautomatisch konfiguriert.
Woher bekomme ich nur den passenden Treiber?
Auch wenn das Problem heute, in abgeschwächter Form, noch existiert, muss man bedenken, dass im Jahr 1992 und auch noch später, die einzige Quelle von Gerätetreibern die mitgelieferte Diskette (später CD) des Herstellers war. Ging diese verloren oder war defekt (Was bei Disketten sehr leicht passierte), stand man in der Regel sehr dumm da. Die einzigen weiteren Quellen waren Freunde mit der gleichen Hardware oder Computerläden, welche ihre Rechner selbst zusammengebaut haben. Bei den großen Märkten (Meinen PC habe ich bei ProMarkt gekauft) brauchte man erst gar nicht nachfragen, da sie nur als Händler fungierten. Zwei Beispiele sollen diese Problematik verdeutlichen:
Meinem ersten PC lag eine Treiberdiskette für die VGA-Karte (Irgendein Trident-Chip) bei. Auf dieser waren Treiber für Windows 3.0 und OS/2 2.0. Dumm war nur, dass der Treiber nicht richtig funktionierte und mein Monitor nach der Installation unter Windows 3.0 kein Bild dargestellt hat. Der Monitor zeigte nur quer laufende Streifen, was in Zeichen war, dass dieser außerhalb seiner Spezifikationen betrieben wurde. Es gab keine Möglichkeit die passende Bildwiederholfrequenz einzustellen. Ich konnte unter Windows 3.0 also nur 16 Farben benutzen. Erst Monate später fiel mir durch puren Zufall bei einem Kumpel eine passende Treiberdiskette in die Hände. Höhere Auflösungen hatten aber wegen der schlechten Daten des Monitors aber keinen großen Sinn. Immerhin kam ich in den Genuss von 256 Farben.
Als im Oktober 1994 „OS/2 3.0 Warp“ auf den Markt kam, gab es dieses vergünstigt für 99 DM zu kaufen. Ein Kumpel, mein Cousin und ich haben damals das Betriebssystem gekauft, da wir davon überzeugt waren, dass es sich durchsetzen würde. Jedenfalls hatte jener Kumpel einen IBM PS/2-Rechner, was eigentlich die perfekte Voraussetzung für den Betrieb von OS/2 sein sollte. Leider brachte die damalige Version von OS/2 keine Treiber für IDE-CD-ROM-Laufwerke mit (Welches im Rechner nachgerüstet war). Es war also nur möglich die Installation per Disketten (ca. 20 3,5″ Disketten) oder über ein vorübergehend eingebautes Mitsumi-CD-Laufwerk (Nostalgiker werden sich erinnern) durchzuführen. Ein passender Treiber für das IDE-CD-ROM-Laufwerk wurde erst ein paar Monate später als Beilage-Diskette des „PC Magazin“ nachgeliefert. Spätere CD-Pressungen von OS/2 3.0 lieferten den Treiber dann mit aus, aber das hat uns damals nicht viel gebracht, da wir ja nur die erste CD-Pressung besaßen.
Weitere Probleme ergaben sich durch die Treiber selbst:
Unterstützte die Hardware kein Plug’n Play musste man die Hardwarekonfiguration im Treiber von Hand vornehmen. Das konnte ziemlich blöd enden, wenn man z.B. einen falschen Interrupt gewählt hatte und das System nach der Treiberinstallation beim Booten hängen blieb. Unter DOS war es relativ einfach den Treiber zu entfernen, bei moderneren Systemen dagegen wurde es ziemlich aufwendig (z.B. Windows 95 im abgesicherten Modus booten, Treiber deinstallieren und nochmal von vorne anfangen).
Die Treiberqualität war damals sehr oft nur von schlechter Qualität. Abstürze waren an der Tagesordnung.
Lustigerweise hatte ich damals unter Linux die wenigsten Treiberprobleme. Meine Hardware war so gewöhnlich, dass alles OotB unterstützt wurde. Heute werden die meisten Treiber mit dem Betriebssystem ausgeliefert. Im Zweifelsfall gibt es das Internet. Dank modernem Plug’n Play muss nichts konfiguriert werden und Hardware funktioniert einfach so.
Disketten waren der Teufel!
Ich hasse Disketten, egal ob 5 1/4″) oder modernere 3,5″-Disketten. Disketten waren notorisch unzuverlässig und zwar immer dann, wenn man deren Inhalt am dringendsten benötigte. Ich weiß gar nicht, wie oft ich am PC saß und vor Frust fast in die Tastatur gebissen habe, weil mal wieder eine Diskette einen Lesefehler hatte. Die Hersteller konnten noch so sehr Werbung machen, aber meiner Erfahrung machte es kaum einen Unterschied ob man billige No-Name oder teure Markendisketten gekauft hat. Bei den teuren Disketten kamen die Fehler halt ein paar Wochen später. Zu Zeiten eines C64 waren die 5¼“ Floppydisketten viel unempfindlicher als die späteren 3½“ HD-Disketten eines PCs, da Erstere eine viel niedrigere Datendichte hatten und der Lesekopf des Laufwerks einfach mehr Fläche pro Bit zur Verfügung hatte (Ich habe mal eine C64-Diskette, über die Fruchtsaft gelaufen ist, einfach durch Aufschneiden der Hülle, Abspülen mit destilliertem Wasser und Einsetzen in eine neue Hülle retten können.) Das Problem fing mit den 3½“ DD-Disketten an und wurde mit den HD-Disketten richtig schlimm. Die Datendichte war sehr viel höher und jedes kleine Staubkorn, konnte die Diskette bzw. deren Inhalt zerstören. Aus diesem Grund sind die meisten Diskettenbenutzer irgendwann dazu übergegangen wichtige Daten redundant auf mehreren Disketten zu speichern (Praktikabel waren drei Disketten). Irgendwann wurde es ziemlich unpraktikabel, mit den Dingern herumzuhantieren da die Dateien immer größer wurden und man gezwungen war Inhalte auf mehrere Disketten zu verteilen, mit den bekannten Konsequenzen (z.B. Diskette 6 von 10 hatte einen Lesefehler). Was war das für eine Offenbarung, als es die ersten richtigen Alternativen zu Disketten gab (z.B. das ZIP-Laufwerk), die deutlich weniger fehleranfällig waren und deutlich mehr Speicherplatz anboten (Wobei das ZIP-Laufwerk irgendwann unter dem berüchtigten „Click of Death„-Fehler litt). Dazu kam noch, dass alle Alternativen zu Disketten deutlich schneller beim Lesen und Schreiben waren. Wer einmal ein Programm oder Spiel von 10 Disketten installiert hat, will diese Zeiten nie mehr zurück haben. Als dann die ersten USB-Sticks auf den Markt kamen, waren Disketten für mich komplett gestorben. Die letzte Diskette, welche ich in der Hand hatte, war eine Demo des DOS-Spiels „Aladdin“. Diese habe ich vor ein paar Monaten auf dem Weg zum Bahnhof auf der Straße gefunden. Ich fand den Fund so ungewöhnlich, dass ich die Diskette an die Tür meines Büros geklebt habe. Heutzutage muss man sich über solche Dinge keine Gedanken mehr machen. Datenaustausch findet üblicherweise das Internet statt und USB-Sticks sind so billig geworden, dass ich regelmäßig einen verliere.
Weitere Gedanken
War früher wirklich alles so schlecht? Natürlich nicht. Gerade was das Verständnis der Hardware und der Betriebssysteme betrifft, war es damals einfacher. Eine 16bit-CPU ist sehr viel einfacher zu programmieren als moderne 64bit-CPUs. Auch konnte man damals sehr viel einfacher selbst Hand anlegen. Beim ATARI ST war es üblich bei bestimmten Hardwareupgrades den Lötkolben zu schwingen. Ein MS-DOS war überschaubar groß und im Endeffekt gab es im Vergleich zu modernen Systemen kaum Stellschrauben. Vermisse ich diese Zeiten deswegen? Absolut nicht. Aber man erinnert sich gerne daran, da man durch sie geprägt wurde.
Sicherheit steht in einem permanenten Spannungsverhältnis zur Alltagstauglichkeit. Das darf weder zu Sicherheitsnihilismus führen, aber man sollte auch nicht den Fehler machen und Alltagstauglichkeit mit schnöder Bequemlichkeit zu verwechseln.
Dieses Dilemma konnte man kürzlich wieder sehr schön im Blog von Mike Kuketz sehen. In seinem Artikel zum sicheren Online-Banking empfiehlt er den Rückgriff auf ein getrenntes Linux-Live-System zur Erledigung von Online-Bankgeschäften. Damit hat er grundsätzlich natürlich vollkommen recht! Ein normales Alltagssystem ist vielfältigen Angriffsmöglichkeiten ausgesetzt und irgendwann möglicherweise einfach von Schadsoftware befallen.
Im weiteren Verlauf des Artikels sieht man aber schon welchen Aufwand das bedeutet. Erstens benötigt man ein vollständig abgeschottetes System, weshalb eine virtuelle Maschine eigentlich wegfällt. Hier muss eine Distribution gewählt, ein Live-Medium erstellt und gepflegt werden. Dazu ist ein erhebliches Vorwissen im Linux-Bereich unerlässlich, welches angesichts der Marktanteile nicht verbreitet ist. Selbst wenn man die Sicherheitsbedenken bezüglich anderer Betriebssysteme zurückstellt, lässt sich so ein System nur mit Linux betreiben - schon aufgrund der Lizenzkosten. Hinzu kommt ein potenziell mehrfach tägliches Wechseln des Betriebssystems mittels Neustart, je nachdem wie intensiv man Bankgeschäfte betreibt, was eine erhebliche Einschränkung des Arbeitsflusses darstellen kann.
An diesem Punkt hat man den Normalanwender eigentlich schon verloren. Da beißt sich die Katze zudem in den Schwanz, denn die Alltagssysteme von versierten Anwendern dürften bereits hochgradig geschützt und deutlich seltener von Schadsoftware befallen sein, als die von Normalanwendern (gezielte Angriffe auf eine Person mal ausgeschlossen). Genau diejenigen, die also von einer solchen Systemtrennung profitieren würden, werden aufgrund des Aufwands zurückschrecken.
Zumal das Risiko nicht immer gleich groß ist. Nimmt man ein 2009 installiertes Windows 7, das eher unsystematisch gewartet und mit zahlreichen Softwareprodukten "angereichert" wurde, besteht schon ein erhebliches Risiko Schadsoftware vorzufinden. Bei einem gepflegten Linux oder macOS-System sieht das aber schon wieder ganz anders aus. Schadsoftware ist für diese Systeme in freier Wildbahn einfach nicht in dem Maße unterwegs. Hier ist dann die Frage, ob der Sicherheitsgewinn durch ein Live-System nicht auch eher theoretischer Natur ist.
Genau an diesem Punkt muss man solche Ratgeber kritisieren. Sichere und leicht umzusetzende Maßnahmen wie ein chipTAN-Generator stehen gleichwertig neben extravaganten Lösungen wie einem Parallel-System für das erst einmal intensive Zusatzkenntnisse erworben werden müssen. Es findet oft - und bei weitem nicht nur in dem obigen Beispiel - keine Einordnung statt, ob beides gleichermaßen notwendig ist.
Hier kommt man wieder zum Sicherheitsnihilismus. Viele Experten sagen nun, dass ein nicht vollständig durchdachtes System von Vornherein unsicher ist. Faktisch würde der Normalanwender aber schon profitieren, wenn er mittels chipTAN-Generator am heimischen Desktopsystem - also ohne schlechte App, auf unsicherem Android - arbeitet.
Bilder:
Einleitungs- und Beitragsbild von pixelcreatures via pixabay / Lizenz: CC0 Creative Commons
Backups müssen leicht durchzuführen sein, ansonsten macht man sie zu selten. Apple hat dafür in sein Desktopbetriebssystem macOS Time Machine implementiert. Mit diesem kann man sowohl auf externen Speichermedien wie Festplatten sichern, als auch auf Netzwerkfreigaben. Das Ziel einer solchen Sicherung kann ein Linux Server sein (siehe: Time Machine Backups auf einen Linux Server sichern), aber auch FreeNAS eignet sich dafür.
FreeNAS basiert auf FreeBSD und bietet eine ebenso mächtige wie leicht konfigurierbare NAS-Lösung (siehe kurze Vorstellung: Ausflug in die BSD-Welt: FreeNAS). Durch Jails und VMs bietet FreeNAS inzwischen deutlich mehr als lediglich einen Netzwerkspeicher. Bei mir hat es aufgrund der Stabilität und übersichtlichen Oberfläche inzwischen den Linux-Heimserver abgelöst.
Apple hat für Time Machine-Freigaben lange Zeit auf die eigene Lösung AFP (Apple Filing Protocoll) gesetzt. Inzwischen ist man in Cupertino auch auf SMB umgestiegen, allerdings müssen die serverseitigen SMB-Implementierungen dafür einige Anpassungen vornehmen. Diese haben sowohl viele LTS-Distributionen noch nicht erreicht, als auch FreeBSD/FreeNAS. Daher muss man gegenwärtig noch auf AFP zurückgreifen, was entgegen vieler Pressemeldungen auch immer noch funktioniert. (siehe: Time Machine Backup auf einen Linux Server - Stand macOS 10.13 "High Sierra").
Freigabe unter FreeNAS einrichten
FreeNAS unterstützt AFP mit Time Machine-Erweiterung von Haus, weshalb keine zusätzlichen Konfigurationsschritt notwendig sind.
In einem ersten Schritt legt man einen Benutzer an mittels dessen man auf die Freigabe zugreifen möchte. Diesen Benutzer kann man beliebig benennen, im vorliegenden Fall heißt er einfach tmb. Ein Heimatverzeichnis braucht er nicht.
Anschließend legt man auf dem Datenträger ein ZFS-Dataset an. Dieses kann ebenfalls beliebig benannt werden und heißt im vorliegenden Fall ebenfalls tmb mit dem Kommentar Time Machine Backup. Die Voreinstellungen kann man so belassen. Im erweiterten Modus kann man bei Bedarf ein Quota festlegen. Dieses sollte einerseits genug Platz für mehre Sicherungsversionen lassen, andererseits aber den anderen Einsatzzwecken des FreeNAS Rechnung tragen. Im hiesigen Beispiel sind das z. B. 500 GB, was ausreicht, da das zu sichernde System lediglich knapp 70 GB an Daten gespeichert hat.
Im folgenden müssen noch die Zugriffsrechte für das Dataset geändert werden. Über die Schaltfläche Zugriffsrechte ändern legt man den angelegten Nutzer tmb als Eigentümer der Freigabe fest.
Zu guter letzt braucht es nun noch die Freigabe selbst. Unter Freigaben kann man Apple (AFP) Freigaben anlegen. Unter Pfad wählt man das soeben eingerichtete Dataset an. Der Haken bei Time Machine ist selbstverständlich zu setzen.
Time Machine Sicherung in macOS einrichten
Ist die Freigabe eingerichtet kann man in den Systemeinstellungen unter Time Machine die Freigabe als Sicherungsziel auswählen. Sollte die Freigabe nicht sofort auftauchen kann man den Finder einmal neustarten. Entweder im Terminal mittels killall Finder oder bei gedrückter Alt-Taste mit einem Rechtsklick auf das Finder-Symbol.
Hier sollte man noch eine Verschlüsselung das Backups auswählen, sofern man das zu sichernde System ebenfalls per FileVault verschlüsselt hat (siehe: macOS mit FileVault verschlüsseln).
Anschließend fragt das System noch nach dem Benutzer für die Freigabe. Hier ist als Benutzernamen tmb und das zugehörige Passwort einzugeben. Das zu wählende Backup-Passwort verschlüsselt das Sparsebundle, das macOS für die Sicherung auf FreeNAS anlegt.
Abschließend führt macOS Time Machine die erste Sicherung durch, die je nach Größe mehrere Stunden dauern kann. Die folgenden Sicherungen beinhalten nur noch die geänderten Dateien. Sofern FreeNAS und macOS angeschaltet sind, sichert Time Machine einmal stündlich. Diese stündlichen Sicherungen werden einmal täglich zu einer Tagessicherung zusammengefasst. Nach einem Monat erfolgt eine Bereinigung, wodurch nur ein Backup pro Woche aufgehoben wird. Ist das Backupziel voll löscht Time Machine die ältesten Sicherungen.
Auf der FreeNAS-Freigabe befindet sich dabei eine sparsebundle-Date. Dabei handelt es sich um ein mitwachsendes Image, das man auch mittels des Festplattendienstprogrammes für andere Einsatzzwecke anlegen kann. Bei Bedarf kann man diese Datei mit dem DiskImageMounter einbinden und nachgucken welche Sicherungen vorhanden sind. Bei einer vor drei Tagen erstmals eingerichteten Sicherung sieht das wie folgt aus:
Bilder:
Einleitungs- und Beitragsbild von FreePhotosART via pixabay / Lizenz: CC0 Creative Commons
In der OSS-Welt hat Guido van Rossum den Begriff des BDFL, Benevolent Dictator for Life (zu dt. Wohlwollender Diktator auf Lebenszeit), geprägt. Von diesem Amt ist er nun zurückgetreten, wie er in der Python Mailing List bekannt gab.
Die Programmiersprache Python sollte den meisten technisch versierten Lesern, die bereits einige Erfahrungen mit Programmierung sammeln konnten, bekannt sein. So setzt diese Sprache auf Einfachheit und Lesbarkeit und greift seit über 20 Jahren zu teils kontroversen Mitteln wie einem Zwang zur Indentation mit Leerzeichen (oder auch Tabs) für Blöcke und (mehr oder weniger) dem Verzicht auf einem klassischen Trennzeichen wie dem Semikolon.
Nicht nur, dass bereits viele Programmierer Python aufgrund dieser Charastika verachten, gab es aufgrund eines Änderungsvorschlags intern viele Proteste. Dies hat im Endeffekt nun dazu geführt, dass der Python-Gründer van Rossum von seiner Leitungsfunktion zurückgetreten ist - aber eins nach dem anderen.
PEP 572
Programmiersprachen werden ebenso wie die durch sie ermöglichte Software laufend weiterentwickelt. Während bei z.B. C++ in bestimmten Abständen neue Versionen wie C++17 veröffentlicht werden, läuft dies bei Python in ähnlicher Weise. Grundlage hierfür bilden die Python Enhancement Proposals, kurz PEP, die als Spezifikationen eine Diskussionsgrundlage für z.B. mögliche neue Features schaffen. Aber auch Empfehlungen wie z.B. die Code style guide in PEP 8 werden hierüber verbreitet.
PEP 572 wird mit "Assignment Expressions" betitelt und beschreibt eine neue Möglichkeit, bestimmte Ausdrücke als Variable für einen untergeordneten Scope zuzuordnen - ich nenne es quasi "with statements auf Stereoide" (stimmt nicht ganz, with statements haben einen anderen Zweck). Ein Codebeispiel:
ohne PEP 572:
env_base = os.environ.get("PYTHONUSERBASE", None)
if env_base:
return env_base
mit PEP 572:
if env_base := os.environ.get("PYTHONUSERBASE", None):
return env_base
Der Code wird damit kürzer, aber bleiben die "Maxime" der Python-Sprache (Einfachheit, Lesbarkeit, ...) erhalten? Diese Entscheidung überlasse ich euch. Mir selber würden zwar auf Anhieb einige Anwendungsbereiche einfallen, es wären aber ähnliche, wo ich jetzt schon zu ternären Operationen greife.
Rückzug
Am 11. Juli 2018 wurde die PEP 572 und ihr Vorschlag akzeptiert. Überraschend hat sich gestern Guido van Rossum in einer E-Mail mit dem Titel "Transfer of power" in der Mailing List gemeldet.
Er möchte laut Mail nicht mehr für eine PEP so intensiv kämpfen müssen, die am Ende trotzdem zu so viel Verachtung führt. Aus diesem Grund zieht er sich permanent aus dem Entscheidungsprozess zurück und gibt somit das erstmals für ihn eingeführte Amt (so die allg. Annahme) des Wohlwollenden Diktators auf Lebenszeit, das mittlerweile in viele andere Open Source-Projekte adaptiert wurde, ab. Der BDFL ist das Oberhaupt eines Projektes und hat dort immer das letzte Wort. Zurückzuführen ist dies auch auf gesundheitliche Gründe, so die Mail. Für die nächste Zeit werde er dennoch als Core Developer aktiv sein. Nun benötige er jedenfalls eine Pause.
Die Projektführung ist jetzt vakant, da van Rossum keinen Nachfolger benannt und diese Entscheidung an das Projekt übergeben hat. Er habe jedoch hinsichtlich des Tagesgeschäfts keine großartigen Sorgen um die Nachfolge.
Am Ende seiner Mail verweist der Entwickler, der Python 1991 veröffentlicht hat, auf den Code of Conduct als Grundsatz. Wer diesen "nicht mag", solle das Projekt freiwillig verlassen.
Aus meiner Sicht ist es nun wichtig, dass Python die Frage um die Projektleitung zeitnah löst. Guido van Rossum wünsche ich auf diesem Wege alles Gute und schätze seine bisherige Arbeit.
Wissenswertes
Python entstand als ABC-Nachfolger und kleines Projekt für die Weihnachtstage im Dezember 1989 und ist heute - je nach Betrachtungsweise - eine der wichtigsten und nachgefragtesten Programmiersprachen. Aktuell in Version 3.7 und der auslaufenden Version 2.7 erhältlich, ist es Grundlage für viele wichtige Programme.
Guido van Rossum ist seit 2013 bei Dropbox angestellt und war vorher von 2005 bis 2012 bei Google tätig.
In der OSS-Welt hat Guido van Rossum den Begriff des BDFL, Benevolent Dictator for Life (zu dt. Wohlwollender Diktator auf Lebenszeit), geprägt. Von diesem Amt ist er nun zurückgetreten, wie er in der Python Mailing List bekannt gab.
Die Programmiersprache Python sollte den meisten technisch versierten Lesern, die bereits einige Erfahrungen mit Programmierung sammeln konnten, bekannt sein. So setzt diese Sprache auf Einfachheit und Lesbarkeit und greift seit über 20 Jahren zu teils kontroversen Mitteln wie einem Zwang zur Indentation mit Leerzeichen (oder auch Tabs) für Blöcke und (mehr oder weniger) dem Verzicht auf einem klassischen Trennzeichen wie dem Semikolon.
Nicht nur, dass bereits viele Programmierer Python aufgrund dieser Charastika verachten, gab es aufgrund eines Änderungsvorschlags intern viele Proteste. Dies hat im Endeffekt nun dazu geführt, dass der Python-Gründer van Rossum von seiner Leitungsfunktion zurückgetreten ist - aber eins nach dem anderen.
PEP 572
Programmiersprachen werden ebenso wie die durch sie ermöglichte Software laufend weiterentwickelt. Während bei z.B. C++ in bestimmten Abständen neue Versionen wie C++17 veröffentlicht werden, läuft dies bei Python in ähnlicher Weise. Grundlage hierfür bilden die Python Enhancement Proposals, kurz PEP, die als Spezifikationen eine Diskussionsgrundlage für z.B. mögliche neue Features schaffen. Aber auch Empfehlungen wie z.B. die Code style guide in PEP 8 werden hierüber verbreitet.
PEP 572 wird mit "Assignment Expressions" betitelt und beschreibt eine neue Möglichkeit, bestimmte Ausdrücke als Variable für einen untergeordneten Scope zuzuordnen - ich nenne es quasi "with statements auf Stereoide" (stimmt nicht ganz, with statements haben einen anderen Zweck). Ein Codebeispiel:
ohne PEP 572:
env_base = os.environ.get("PYTHONUSERBASE", None)
if env_base:
return env_base
mit PEP 572:
if env_base := os.environ.get("PYTHONUSERBASE", None):
return env_base
Der Code wird damit kürzer, aber bleiben die "Maxime" der Python-Sprache (Einfachheit, Lesbarkeit, ...) erhalten? Diese Entscheidung überlasse ich euch. Mir selber würden zwar auf Anhieb einige Anwendungsbereiche einfallen, es wären aber ähnliche, wo ich jetzt schon zu ternären Operationen greife.
Rückzug
Am 11. Juli 2018 wurde die PEP 572 und ihr Vorschlag akzeptiert. Überraschend hat sich gestern Guido van Rossum in einer E-Mail mit dem Titel "Transfer of power" in der Mailing List gemeldet.
Er möchte laut Mail nicht mehr für eine PEP so intensiv kämpfen müssen, die am Ende trotzdem zu so viel Verachtung führt. Aus diesem Grund zieht er sich permanent aus dem Entscheidungsprozess zurück und gibt somit das erstmals für ihn eingeführte Amt (so die allg. Annahme) des Wohlwollenden Diktators auf Lebenszeit, das mittlerweile in viele andere Open Source-Projekte adaptiert wurde, ab. Der BDFL ist das Oberhaupt eines Projektes und hat dort immer das letzte Wort. Zurückzuführen ist dies auch auf gesundheitliche Gründe, so die Mail. Für die nächste Zeit werde er dennoch als Core Developer aktiv sein. Nun benötige er jedenfalls eine Pause.
Die Projektführung ist jetzt vakant, da van Rossum keinen Nachfolger benannt und diese Entscheidung an das Projekt übergeben hat. Er habe jedoch hinsichtlich des Tagesgeschäfts keine großartigen Sorgen um die Nachfolge.
Am Ende seiner Mail verweist der Entwickler, der Python 1991 veröffentlicht hat, auf den Code of Conduct als Grundsatz. Wer diesen "nicht mag", solle das Projekt freiwillig verlassen.
Aus meiner Sicht ist es nun wichtig, dass Python die Frage um die Projektleitung zeitnah löst. Guido van Rossum wünsche ich auf diesem Wege alles Gute und schätze seine bisherige Arbeit.
Wissenswertes
Python entstand als ABC-Nachfolger und kleines Projekt für die Weihnachtstage im Dezember 1989 und ist heute - je nach Betrachtungsweise - eine der wichtigsten und nachgefragtesten Programmiersprachen. Aktuell in Version 3.7 und der auslaufenden Version 2.7 erhältlich, ist es Grundlage für viele wichtige Programme.
Guido van Rossum ist seit 2013 bei Dropbox angestellt und war vorher von 2005 bis 2012 bei Google tätig.
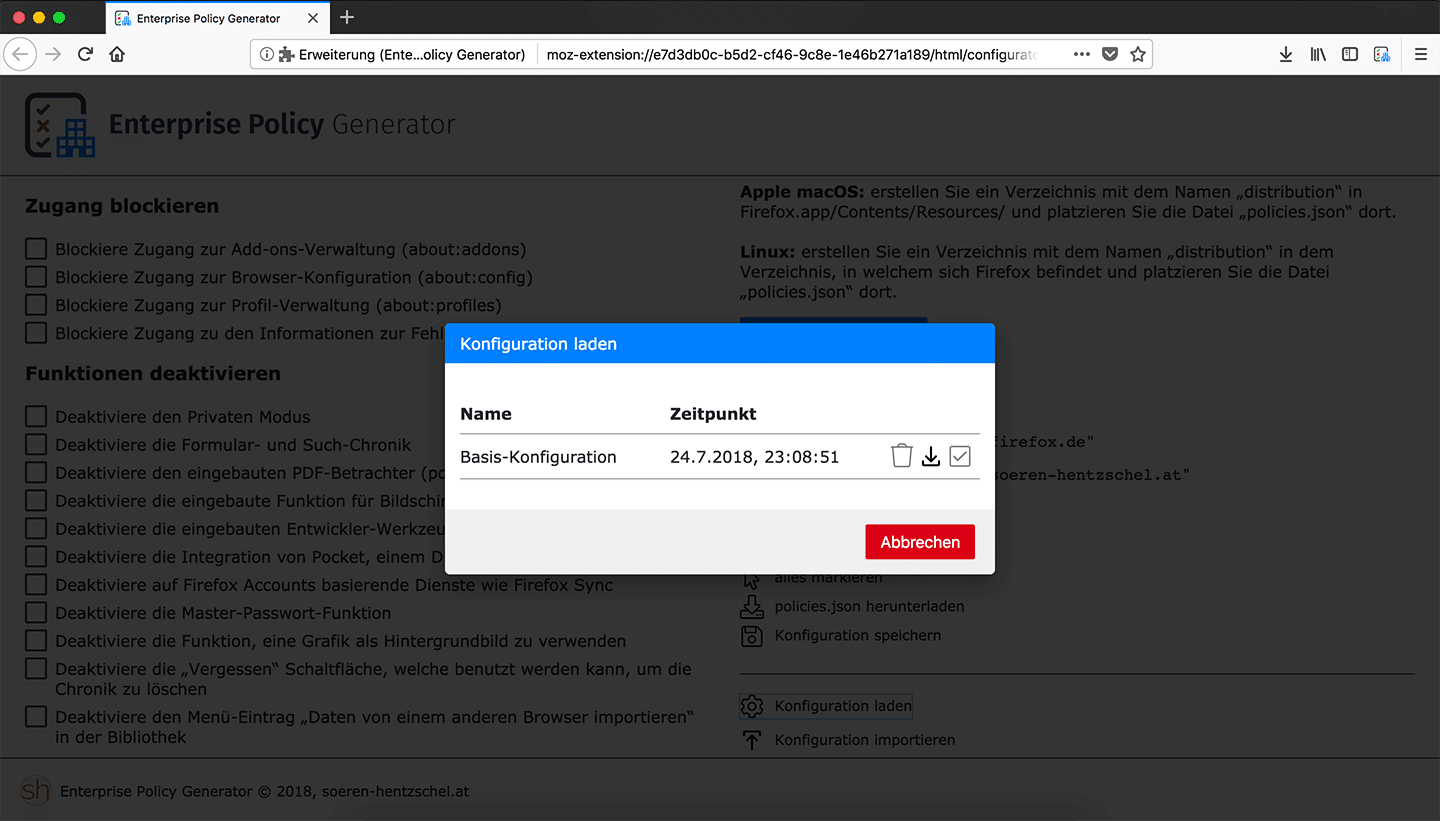
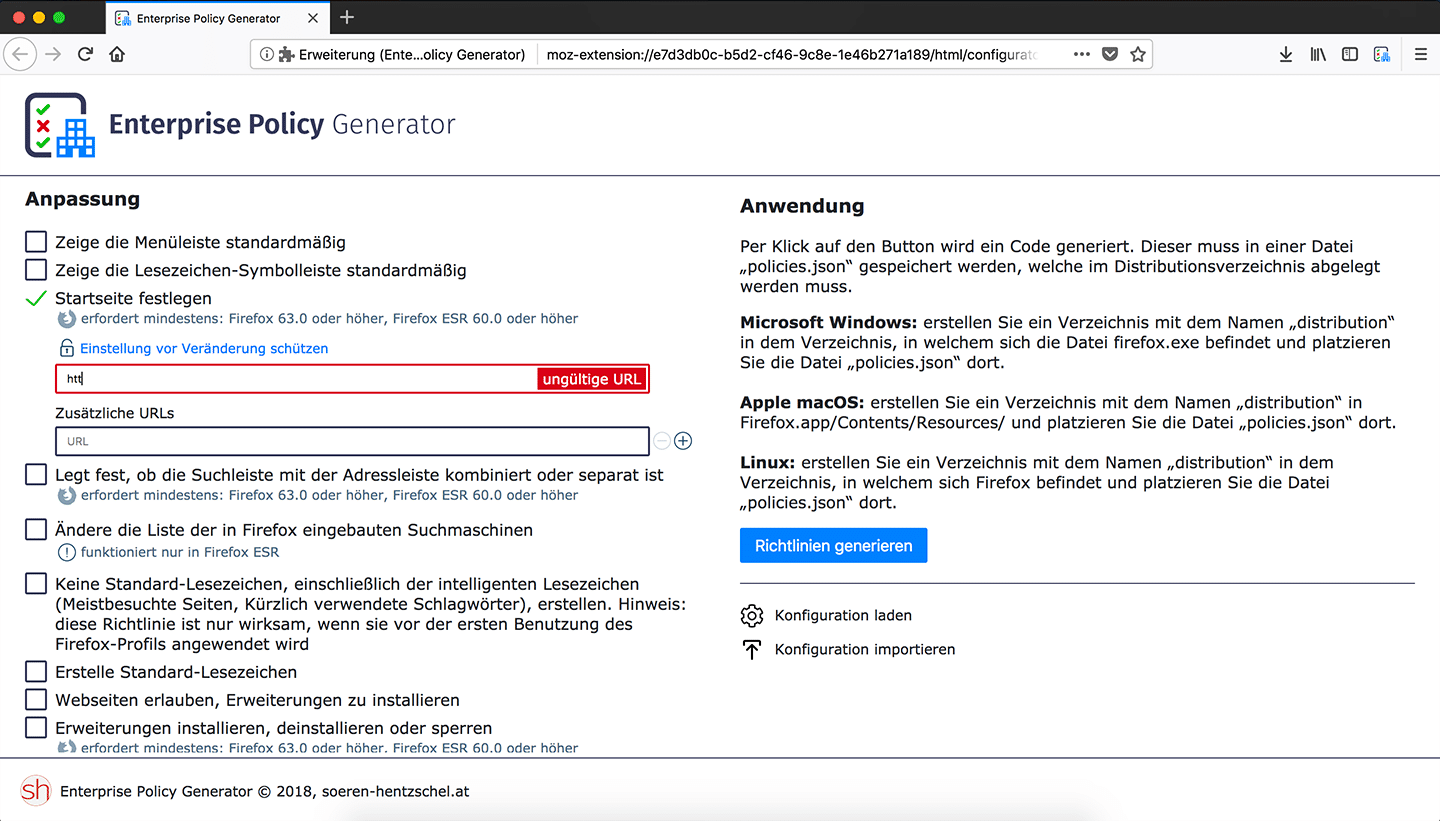
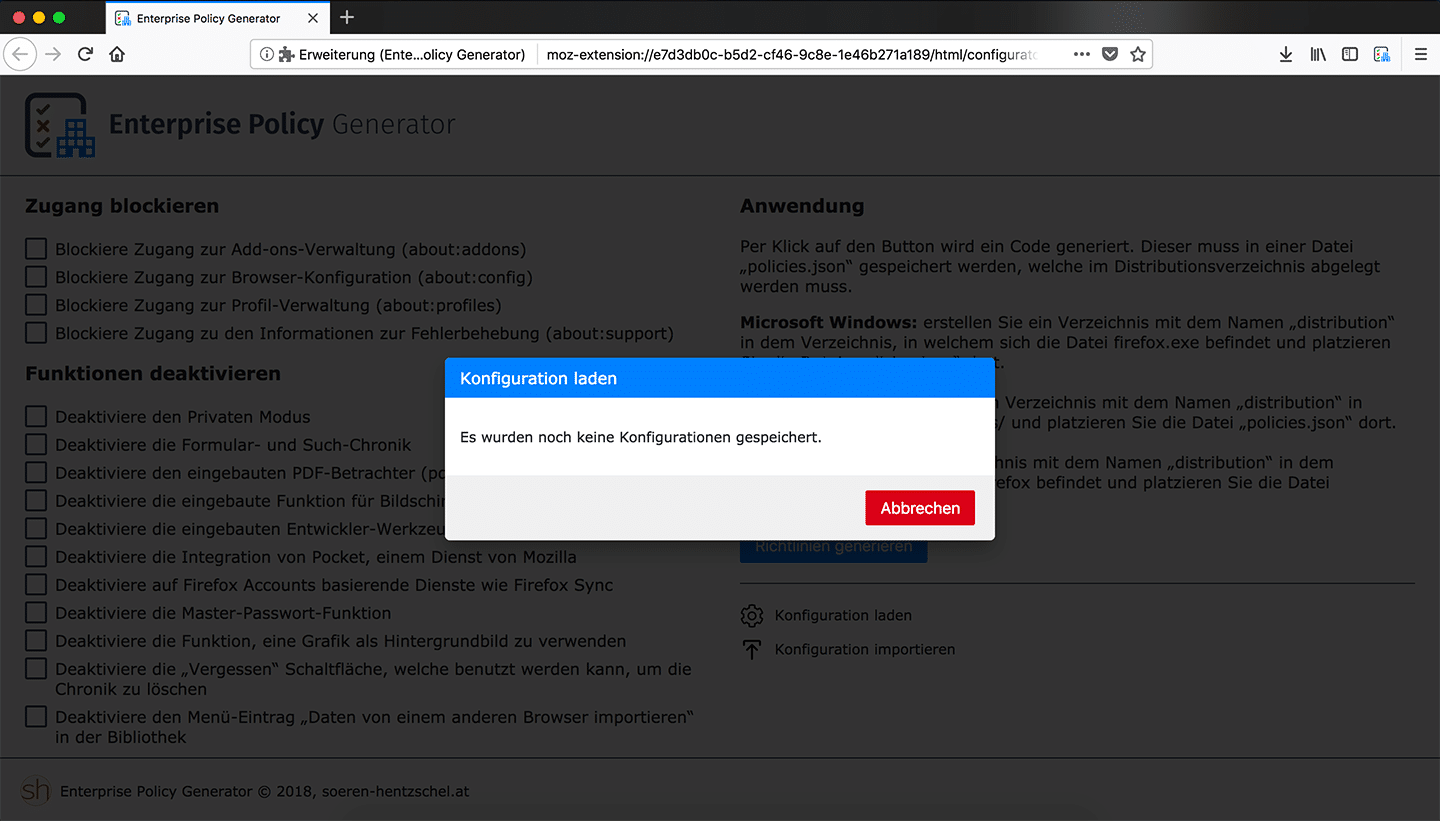


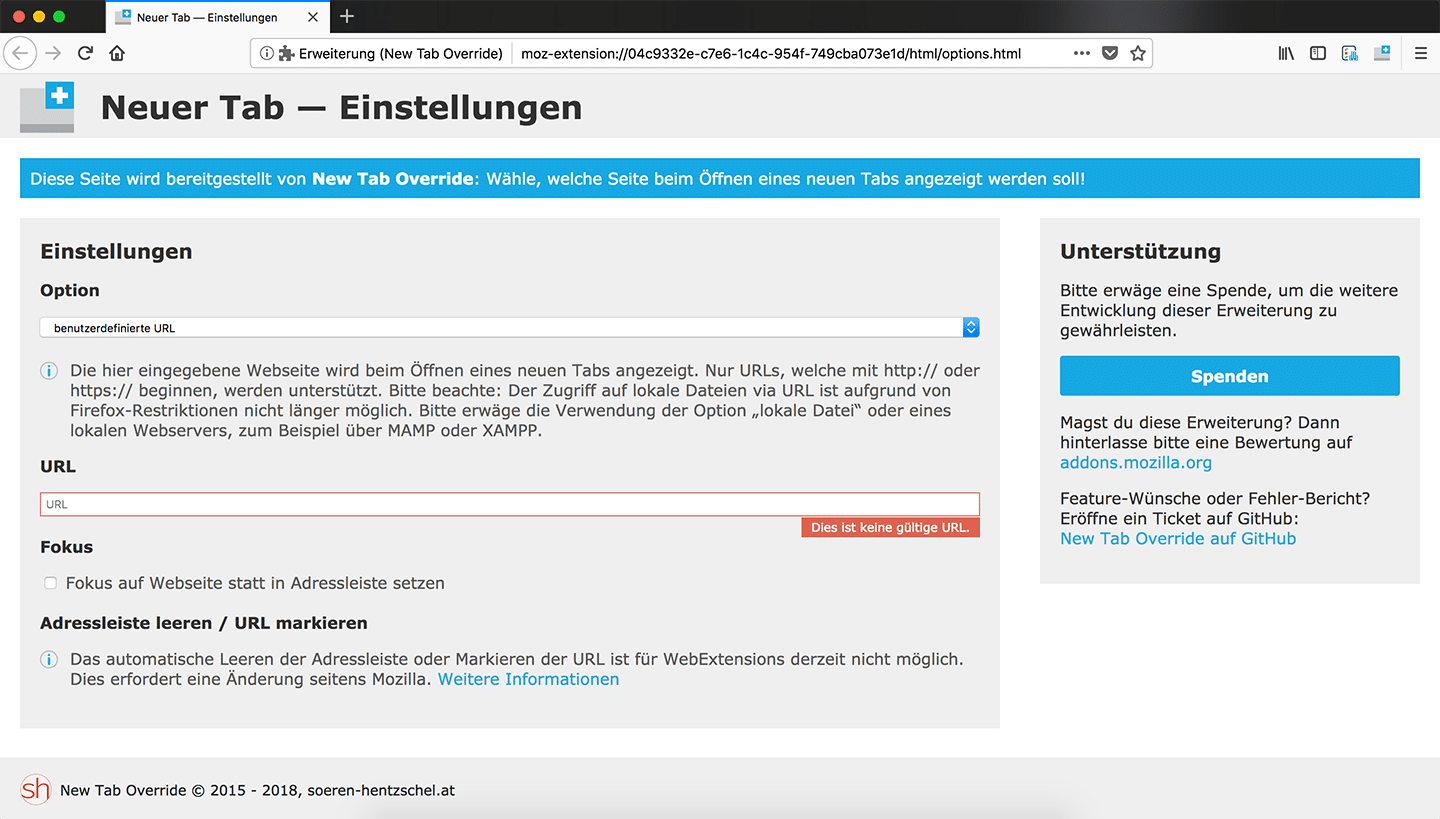
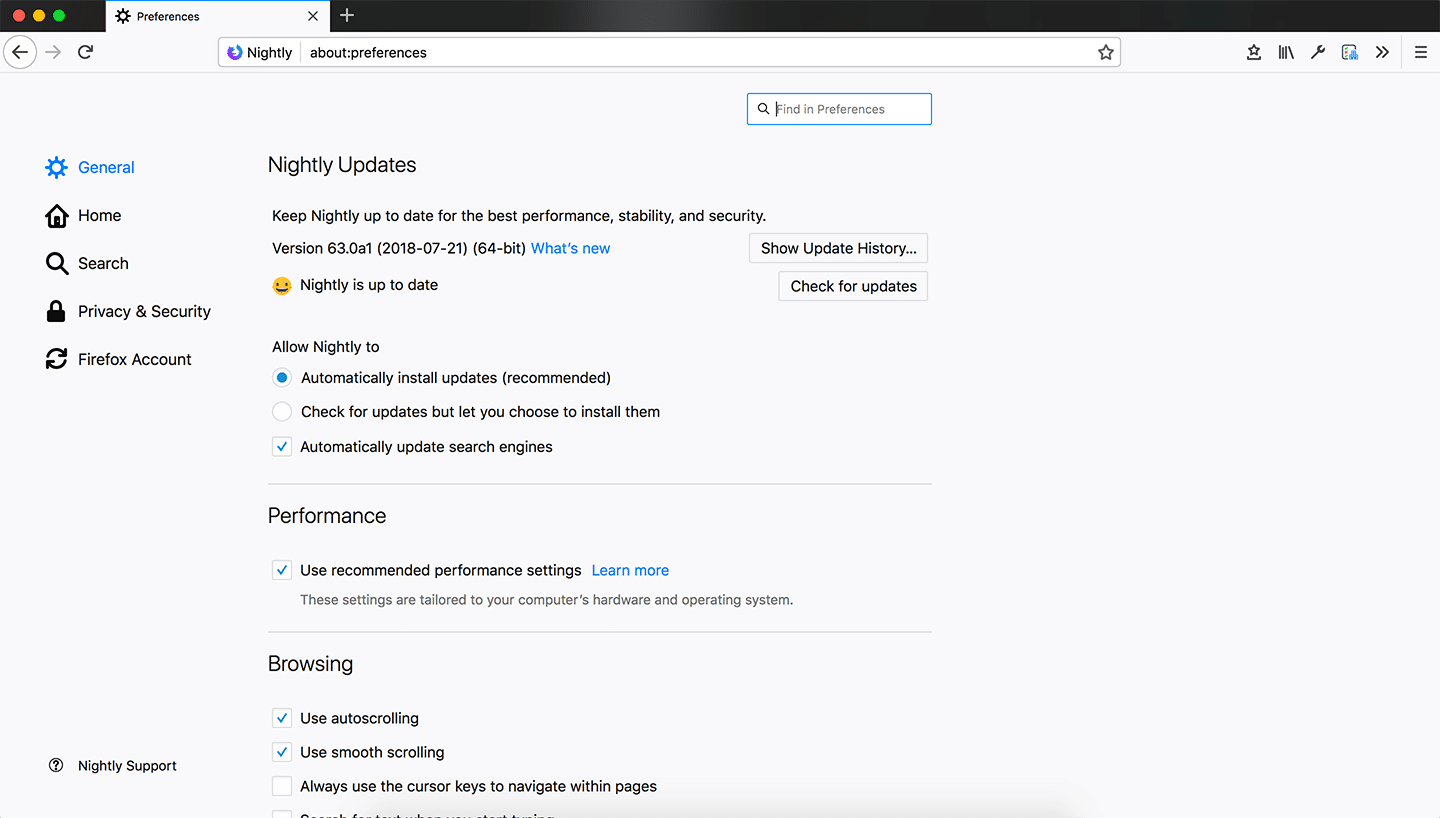
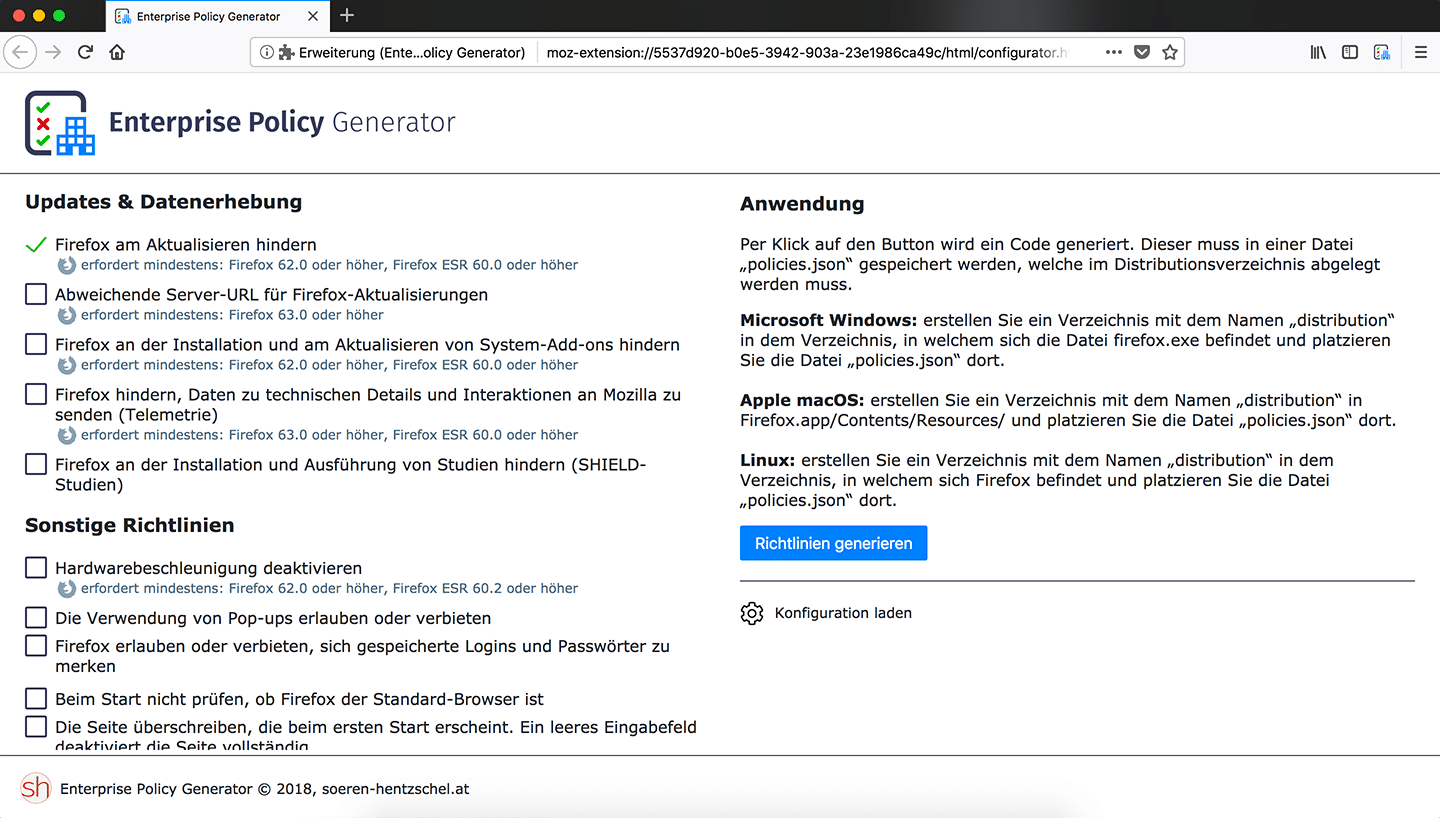

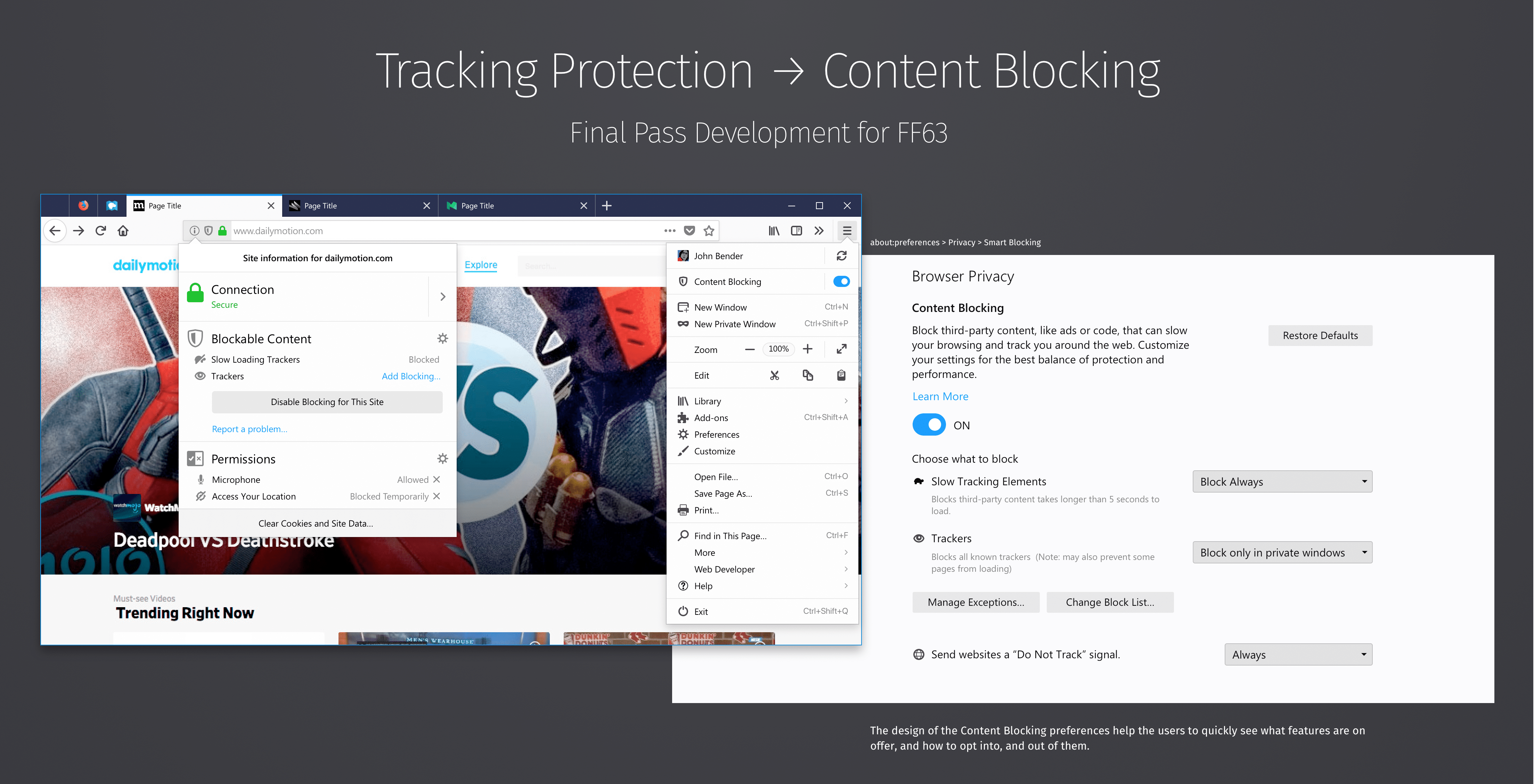
 Mit Veröffentlichung der ersten Devolo Unterputz-Module, Schalter und Dimmer, hat natürlich auch Kevin in die Tasten gehauen und sein Devolo-Plugin für Homebridge aktualisiert. # Installation npm install homebridge-devolo -g --unsafe-perm # Update npm update homebridge-devolo -g --unsafe-perm „Hey Siri, schalte das Licht in der Garage an“ schaltet bei uns die LED Leuchtstoffröhre in der Garage an, …
Mit Veröffentlichung der ersten Devolo Unterputz-Module, Schalter und Dimmer, hat natürlich auch Kevin in die Tasten gehauen und sein Devolo-Plugin für Homebridge aktualisiert. # Installation npm install homebridge-devolo -g --unsafe-perm # Update npm update homebridge-devolo -g --unsafe-perm „Hey Siri, schalte das Licht in der Garage an“ schaltet bei uns die LED Leuchtstoffröhre in der Garage an, … 










{kind=link}