Server in einem Rechenzentrum laufen normalerweise unverschlüsselt; was nicht weiter verwundert, immerhin können die Server nicht einfach per Tastatur freigeschaltet werden. Ich habe das Problem vor Jahren so für mich gelöst, dass die Hostmaschine unverschlüsselt lief und auf dieser Maschine verschlüsselte und virtualisierte Gastmaschinen liefen. Genutzt wurde hierfür KVM. Für einen neuen Server, möchte ich den physikalischen Server verschlüsseln und diesen per SSH freischalten. Einzig und alleine die boot-Partion sollte dann noch unverschlüsselt.
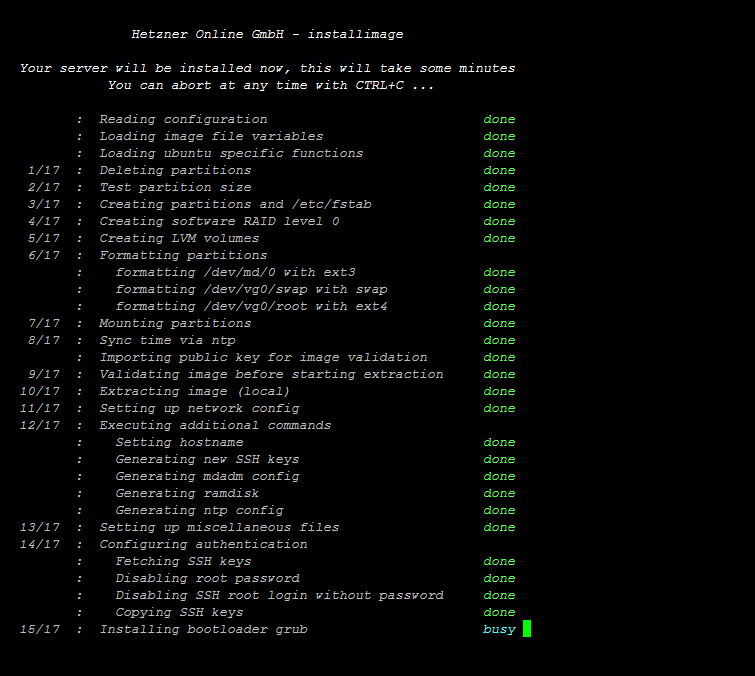
Die Installation des Servers über das Tool installimage
Beschrieben wird das ganze Prozedere hierbei anhand des Hoster Hetzner. Bei anderen Hostern, werden sich Feinheiten, wie die initiale Installation und ähnliches unterscheiden. Im ersten Schritt wird der Server über das Webinterface von Hetzner im Rescue-Modus gebootet. Dazu muss dieser aktiviert werden und anschließend der Server neugestartet werden. Installiert wird das neue System über das Tool installimage. Um die Installation zu automatisieren, wird im root-Verzeichnis ein Datei mit dem Namen autosetup angelegt:
nano /autosetup
Diese Datei wird mit folgendem Inhalt befüllt:
## Hetzner Online GmbH - installimage - config
## HARD DISK DRIVE(S):
# Onboard: ST4000NM0024-1HT178
DRIVE1 /dev/sda
# Onboard: ST4000NM0024-1HT178
DRIVE2 /dev/sdb
## SOFTWARE RAID:
## activate software RAID? < 0 | 1 >
SWRAID 1
## Choose the level for the software RAID < 0 | 1 | 10 >
SWRAIDLEVEL 0
## BOOTLOADER:
BOOTLOADER grub
## HOSTNAME:
HOSTNAME server
## PARTITIONS / FILESYSTEMS:
PART /boot ext3 2G
PART lvm vg0 all
LV vg0 swap swap swap 64G
LV vg0 root / ext4 all
## OPERATING SYSTEM IMAGE:
IMAGE /root/.oldroot/nfs/install/../images/Ubuntu-1804-bionic-64-minimal.tar.gz
Anschließend wird installimage gestartet:
installimage
Findet installimage beim Start besagte autosetup-Datei wird die Installation automatisch durchgeführt. Nach einigen Minuten ist die Installation abgeschlossen. Die Partitionierung des Servers wurde bewusst einfach gehalten, so existiert eine Boot-, eine Swap- und eine Datenpartion. Im einzelnen existieren technisch gesehen zwei Partitionen, eine boot-Partition und eine Partition für das LVM. Innerhalb des LVM werden zwei logische Partitonen für Swap- und die Datenpartition bzw. das root-Verzeichnis hinterlegt. Nach der Installation kann der Server aus dem Rescue-System heraus neugestartet werden:
reboot
Die Verbindung zum Server wird dadurch getrennt. Diese Pause kann man nun nutzen um die SSH-Schlüssel für die Freischaltung auf dem lokalen Rechner anzulegen:
ssh-keygen -t rsa -b 4096 -f .ssh/dropbear
Nachdem dies geschehen ist, kann sich wieder per SSH mit dem Server verbunden werden. Dies wird mit einer Fehlermeldung quittiert werden:
WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED!
Hintergrund ist dass die Informationen in der known_hosts-Datei auf dem lokalen System nicht mehr mit dem Fingerprint des Servers zusammenpassen. Dies ist nicht weiter verwunderlich. Immerhin hat sich das System vom Rescue-System in Richtung des installierten Systems geändert. Die known_hosts-Datei muss entsprechend bereinigt werden:
ssh-keygen -R server.example.org
Damit wird der entsprechende Eintrag entfernt und die Verbindung per SSH kann wiederhergestellt werden. Auf dem installierten System werden nun die Pakete auf den aktuellen Stand gebracht und anschließend werden BusyBox und Dropbear installiert:
apt-get update && apt-get dist-upgrade
apt-get install busybox dropbear-initramfs
BusyBox und Dropbear werden später für die Freischaltung per SSH benötigt. Bei BusyBox handelt es sich um eine Sammlung von Kommandozeilentools, während Dropbear ein minimaler SSH-Server ist. Diese sollen in das initramfs integriert werden und somit beim Start des System zur Verfügung stehen. Dazu wird im nächsten Schritt die Datei initramfs.conf bearbeitet:
nano /etc/initramfs-tools/initramfs.conf
Dort wird der Wert:
BUSYBOX=auto
in
BUSYBOX=y
geändert. Anschließend werden die Schlüssel für den SSH-Server Dropbear hinterlegt:
nano /etc/dropbear-initramfs/authorized_keys
In die Datei authorized_keys wird nun der, in der auf dem lokalen Rechner enthaltenden Datei dropbear.pub, hinterlegte Schlüssel eingefügt und die Datei gespeichert. Da es einen Bug in Ubuntu 18.04 gibt, welcher das spätere Entsperren verhindern, muss ein passender Workarround installiert werden.
cd /etc/initramfs-tools/hooks/
nano cryptsetup-fix.sh
In die Datei wird nun folgendes Skript kopiert:
#!/bin/sh
# This hook is for fixing busybox-initramfs issue while unlocking a luks
# encrypted rootfs. The problem is that the included busybox version
# is stripped down to the point that it breaks cryptroot-unlock script:
# https://bugs.launchpad.net/ubuntu/+source/busybox/+bug/1651818
# This is a non-aggressive fix based on the original busybox-initramfs hook
# until the bug is fixed.
# busybox or busybox-static package must be present for this to work
# This file should be placed in /etc/initramfs-tools/hooks/ and have +x flag set
# after that you need to rebuild the initramfs with 'update-initramfs -u'
# Users reported the solution working on at least:
# Ubuntu 17.04, 17.10, 18.04
# Also note that this does not replace busybox-initramfs package.
# The package must be present, this hook just fixes what's broken.
# Hamy - www.hamy.io
set -e
case "${1:-}" in
prereqs) echo ""; exit 0;;
esac
[ n = "$BUSYBOX" ] && exit 0
[ -r /usr/share/initramfs-tools/hook-functions ] || exit 0
. /usr/share/initramfs-tools/hook-functions
# Testing the presence of busybox-initramfs hook
[ -x /usr/share/initramfs-tools/hooks/zz-busybox-initramfs ] || exit 0
# The original busybox binary added by busybox-initramfs
BB_BIN_ORG=$DESTDIR/bin/busybox
[ -x $BB_BIN_ORG ] || exit 0
# The one we want to replace it with
[ -x /bin/busybox ] || exit 0
BB_BIN=/bin/busybox
# Ensure the original busybox lacks extended options
# and the soon-to-be-replaced-by one does not
if $BB_BIN_ORG ps -eo pid,args >/dev/null 2>&1; then
exit 0
elif ! $BB_BIN ps -eo pid,args >/dev/null 2>&1; then
exit 0
fi
# Get the inode number of busybox-initramfs binary
BB_BIN_ORG_IND=$(stat --format=%i $BB_BIN_ORG)
# Replace the binary
rm -f $BB_BIN_ORG
copy_exec $BB_BIN /bin/busybox
echo -n "Fixing busybox-initramfs for:"
for alias in $($BB_BIN --list-long); do
alias="${alias#/}"
case "$alias" in
# strip leading /usr, we don't use it
usr/*) alias="${alias#usr/}" ;;
*/*) ;;
*) alias="bin/$alias" ;; # make it into /bin
esac
# Remove (and then re-add) all the hardlinks added by busybox-initramfs
if [ -e "$DESTDIR/$alias" ] && [ $(stat --format=%i "$DESTDIR/$alias") -eq $BB_BIN_ORG_IND ]; then
echo -n " ${alias##*/}"
rm -f "$DESTDIR/$alias"
ln "$DESTDIR/bin/busybox" "$DESTDIR/$alias"
fi
done
# To get a trailing new line
echo
Anschließend muss das Skript ausführbar gemacht werden:
chmod +x cryptsetup-fix.sh
Der betreffende Bug ist zwar mittlerweile mit einem Fix versehen, bisher taucht die Version 2:2.0.2-1ubuntu2 des cryptsetup-Paketes allerdings nur in der nächsten Ubuntu Version 18.10 auf. Der nun installierte Hook sorgt dafür das bestimmte Kommandos beim Generieren des initramfs korrigiert werden. Anschließend muss der Server wieder in das Rescue-System von Hetzner gestartet werden. Dazu wird dieses wieder über das Hetzner-Webinterface aktiviert und anschließend der Server neugestartet:
reboot
Im Rescue-System wird nun das LVM gemountet. Da dieses nicht standardmäßig unter /dev/mapper/ auftaucht muss das Tool lvm bemüht werden:
lvm vgscan -v
lvm vgchange -a y
Dabei werden die Volume Groups gesucht und anschließend aktiviert. Nun kann das LVM gemountet werden.
mount /dev/mapper/vg0-root /mnt/
Vom gemounteten LVM wird nun eine Sicherung im Ordner /oldroot angelegt:
mkdir /oldroot/
rsync -a /mnt/ /oldroot/
Nachdem die Sicherung, welche einige Minuten in Anspruch nehmen kann, durchgeführt wurde, wird das LVM wieder deaktiviert:
umount /mnt/
Im nächsten Schritt wird die Volume Group gelöscht:
vgremove vg0
Dabei muss man eine Reihe von Abfragen mit y beantworten:
Do you really want to remove volume group "vg0" containing 2 logical volumes? [y/n]: y
Do you really want to remove active logical volume swap? [y/n]: y
Logical volume "swap" successfully removed
Do you really want to remove active logical volume root? [y/n]: y
Logical volume "root" successfully removed
Volume group "vg0" successfully removed
Nachdem die alte Volume Group gelöscht wurde, wird das verschlüsselte dm-crypt-Device angelegt:
cryptsetup --cipher aes-xts-plain64 --key-size 256 --hash sha256 --iter-time=10000 luksFormat /dev/md1
Während dieses Prozess muss bestätigt werden das /dev/md1, das bei der Installation definierte RAID 0, wirklich gelöscht werden soll und eine sichere Passphrase eingegeben werden:
WARNING!
========
This will overwrite data on /dev/md1 irrevocably.
Are you sure? (Type uppercase yes): YES
Enter passphrase:
Verify passphrase:
Danach wird das erzeugte dm-crypt-Device geöffnet:
cryptsetup luksOpen /dev/md1 cryptroot
Hierbei muss die verwendete Passphrase wieder eingegeben werden. Danach wird das physische Volume für cryptroot erzeugt:
pvcreate /dev/mapper/cryptroot
Nun wird eine neue Volume Group mit logischen Volumes angelegt:
vgcreate vg0 /dev/mapper/cryptroot
lvcreate -n swap -L64G vg0
lvcreate -n root -l100%FREE vg0
Nachdem die Volume Group erstellt wurde, wird auf den logischen Volumes dieser, wieder ein Dateisystem installiert:
mkfs.ext4 /dev/vg0/root
mkswap /dev/vg0/swap
Das vorher erstellte Backup kann nun wieder zurückgespielt werden. Dazu wird das Volume gemountet und anschließend mittels rsync wieder befüllt:
mount /dev/vg0/root /mnt/
rsync -a /oldroot/ /mnt/
Danach bereiten wir das System auf chroot vor, das heißt wir begeben uns in den Kontext der eigentlichen Ubuntu-Installation:
mount /dev/md0 /mnt/boot
mount --bind /dev /mnt/dev
mount --bind /sys /mnt/sys
mount --bind /proc /mnt/proc
chroot /mnt
In diesem Kontext geben wir das verschlüsselte Blockgerät bekannt, indem wir die Datei /etc/crypttab anpassen:
nano /etc/crypttab
Dort fügen wir folgende Zeile hinzu:
cryptroot /dev/md1 none luks
Nachdem die Datei gespeichert wurde, aktualisieren wir das initramfs:
update-initramfs -u
Kommt es hierbei zur Fehlermeldung:
dropbear: WARNING: Invalid authorized_keys file, remote unlocking of cryptroot via SSH won't work!"
so wurde die Datei authorized_keys im falschen Pfad hinterlegt. Nachdem das initramfs korrekt aktualisiert wurde, kann GRUB aktualisiert werden:
update-grub
grub-install /dev/sda
grub-install /dev/sdb
Beim update-grub kann es zu folgenden Warnungen und Fehlern kommen:
Generating grub configuration file ...
WARNING: Failed to connect to lvmetad. Falling back to device scanning.
WARNING: Failed to connect to lvmetad. Falling back to device scanning.
error: cannot seek `/dev/mapper/cryptroot': Invalid argument.
error: cannot seek `/dev/mapper/cryptroot': Invalid argument.
error: cannot seek `/dev/mapper/cryptroot': Invalid argument.
error: cannot seek `/dev/mapper/cryptroot': Invalid argument.
Found linux image: /boot/vmlinuz-4.15.0-29-generic
Found initrd image: /boot/initrd.img-4.15.0-29-generic
Found linux image: /boot/vmlinuz-4.15.0-24-generic
Found initrd image: /boot/initrd.img-4.15.0-24-generic
WARNING: Failed to connect to lvmetad. Falling back to device scanning.
WARNING: Failed to connect to lvmetad. Falling back to device scanning.
error: cannot seek `/dev/mapper/cryptroot': Invalid argument.
error: cannot seek `/dev/mapper/cryptroot': Invalid argument.
error: cannot seek `/dev/mapper/cryptroot': Invalid argument.
error: cannot seek `/dev/mapper/cryptroot': Invalid argument.
WARNING: Failed to connect to lvmetad. Falling back to device scanning.
done
Diese können grundsätzlich ignoriert werden. Die Warnung entsteht durch den im Rescue-System nicht vorhandenen Dienst lvmetad; im eigentlichen System ist dieser Dienst verfügbar. Die Fehlermeldungen entstehen beim Erzeugen der GRUB-Konfiguration mittels update-grub. Wenn man diesen Vorgang mittels grub-mkconfig laufen lässt, wird man feststellen das die Dateien /etc/grub.d/10_linux und /etc/grub.d/20_linux_xen hierfür verantwortlich sind. Um die Fehlermeldung zu deaktivieren muss folgender Block aus beiden Dateien entfernt werden:
# btrfs may reside on multiple devices. We cannot pass them as value of root= parameter
# and mounting btrfs requires user space scanning, so force UUID in this case.
if [ "x${GRUB_DEVICE_UUID}" = "x" ] || [ "x${GRUB_DISABLE_LINUX_UUID}" = "xtrue" ] \
|| ! test -e "/dev/disk/by-uuid/${GRUB_DEVICE_UUID}" \
|| ( test -e "${GRUB_DEVICE}" && uses_abstraction "${GRUB_DEVICE}" lvm ); then
LINUX_ROOT_DEVICE=${GRUB_DEVICE}
else
LINUX_ROOT_DEVICE=UUID=${GRUB_DEVICE_UUID}
fi
Anschließend kann erneut ein:
update-grub
ausgeführt werden. Danach wird die chroot-Umgebung verlassen, die Dateisysteme werden ausgehangen und der Server neugestartet:
exit
umount /mnt/boot /mnt/proc /mnt/sys /mnt/dev
umount /mnt
sync
reboot
Wenn man sich nun mit dem System über den Dropbear-Schlüssel verbindet:
ssh -i .ssh/dropbear root@server.example.org
wird man von BusyBox begrüßt:
To unlock root partition, and maybe others like swap, run `cryptroot-unlock`
BusyBox v1.27.2 (Ubuntu 1:1.27.2-2ubuntu3) built-in shell (ash)
Enter 'help' for a list of built-in commands.
Zur Entsperrung muss der Befehl cryptroot-unlock eingegeben und anschließend die Passphrase eingegeben. Dies führt zu folgender Ausgabe:
...
/bin/cryptroot-unlock: line 1: usleep: not found
/bin/cryptroot-unlock: line 1: usleep: not found
/bin/cryptroot-unlock: line 1: usleep: not found
Error: Timeout reached while waiting for PID 388.
Wenige Sekunden später sollte die Verbindung abbrechen und anschließend das System hochfahren. Auf dem System kann sich nun mit dem für den Server verwendeten SSH-Schlüssel angemeldet werden.