Eines der großen Vorteile gegenüber Windows ist bei Linux die Shell. Öffnet man ein Terminal, eröffnet sich gleichzeitig eine ganz neue Welt der Möglichkeiten, um Aufgaben automatisiert zu lösen. Da man für produktives Arbeiten aber einige Befehle und Tricks kennen sollte, hatte ich schonmal in einem früheren Blogartikel über nützliche Kniffe geschrieben. In diesem Artikel soll es nun um empfehlenswerte Terminalanwendungen gehen.
Warum Terminalanwendungen?
Zunächst einmal: Die unten stehende Liste will natürlich in keinster Weise vollständig sein, es handelt sich dabei nur um persönliche Empfehlungen zu Terminalanwendungen (also keine Befehle, die nur eine Sache tun), über Ergänzungen jeder Art freue ich mich natürlich.
Warum setze ich überhaupt Terminalanwendungen ein?
Terminalanwendungen…
- …machen verstärkt Gebrauch von Tastaturkürzeln => das ist schnell & produktiv, wenn man sich daran gewöhnt hat
- …sind i.d.R. ressourcenschonend und laufen gut unter Linux (Linux ist in erster Linie als OS ohne GUI konzipiert)
- … haben oft einfache, d.h. nicht überladene Oberflächen, die meist auch sehr gut anpassbar sind
- …können auch problemlos von entfernten Rechnern per SSH genutzt werden, da keine grafische Oberfläche notwendig ist
Meine Grundausstattung
urxvt - schneller Terminal-Emulator
Seit einiger Zeit benutze ich nicht mehr das Standardterminal von Gnome, sondern urxvt. Dabei handelt es sich um einen schnellen Terminal-Emulator, der durch die Konfigurationsdatei (~/.Xdefaults) sehr gut anpassbar und mittels Perl-Plugins erweiterbar ist. Besonders gefällt mir dabei das Tabplugin (urxvt-tabbedex), mit dem ich mit Tastenkombinationen (Shift+Pfeiltaste_nach_unten = Neuer Tab, Navigation mit Shift+Pfeiltasten_links_rechts, Tabbenennung mit Shift+Pfeiltaste nach oben, Verschieben der Tabs mit Strg+Pfeiltasten) sehr leicht mehrere Terminals verwalten kann. Meine Konfiguration befindet sich übrigens auch auf github, zusammen mit Einstellungen zu anderen hier angesprochenen Tools (z.B. zsh) in meinem dotfiles Repository.
Installation - Archlinux:
$ sudo pacman -S rxvt-unicode
Installation - Ubuntu/Debian (universe):
$ sudo apt-get install rxvt-unicode-256color
zsh - die bessere Shell
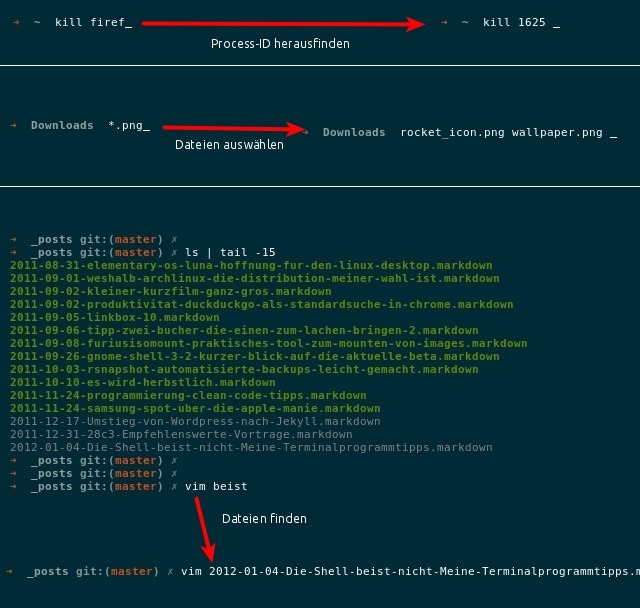
Ich benutze statt der Bash die zsh zusammen mit oh-my-zsh. Letzteres ist eine Community-Sammlung an Einstellungen, Plugins und Themes für zsh. Die Z-Shell selbst hat viele Vorteile gegenüber bash und ist gleichzeitig dazu kompatibel, sodass man auf keine bash-Features verzichten muss. So bietet zsh beispielsweise umfangreichere Tab-Vervollständigungen und Komfortfunktionen wie die Korrektur von Tippfehlern oder das Nachfragen beim Löschen vieler Dateien. Die Screenshots unten zeigen einige Beispiele. Falls du noch nie von zsh gehört haben solltest, lohnt es sich auf jeden Fall, sich einmal damit zu beschäftigen!
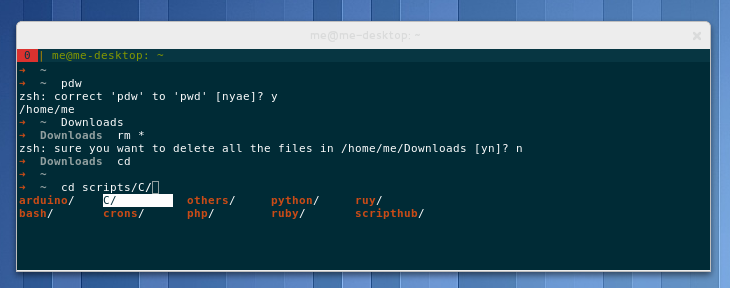
Tab-Verfollständigungs-Beispiele bei zsh:
tmux
Mitlerweile verwende ich es wegen urxvt zwar seltener, allerdings ist auch tmux (eine screen-Alternative) allemal eine Erwähnung wert. Ich verweise hier mal auf einen älteren Artikel zu tmux.
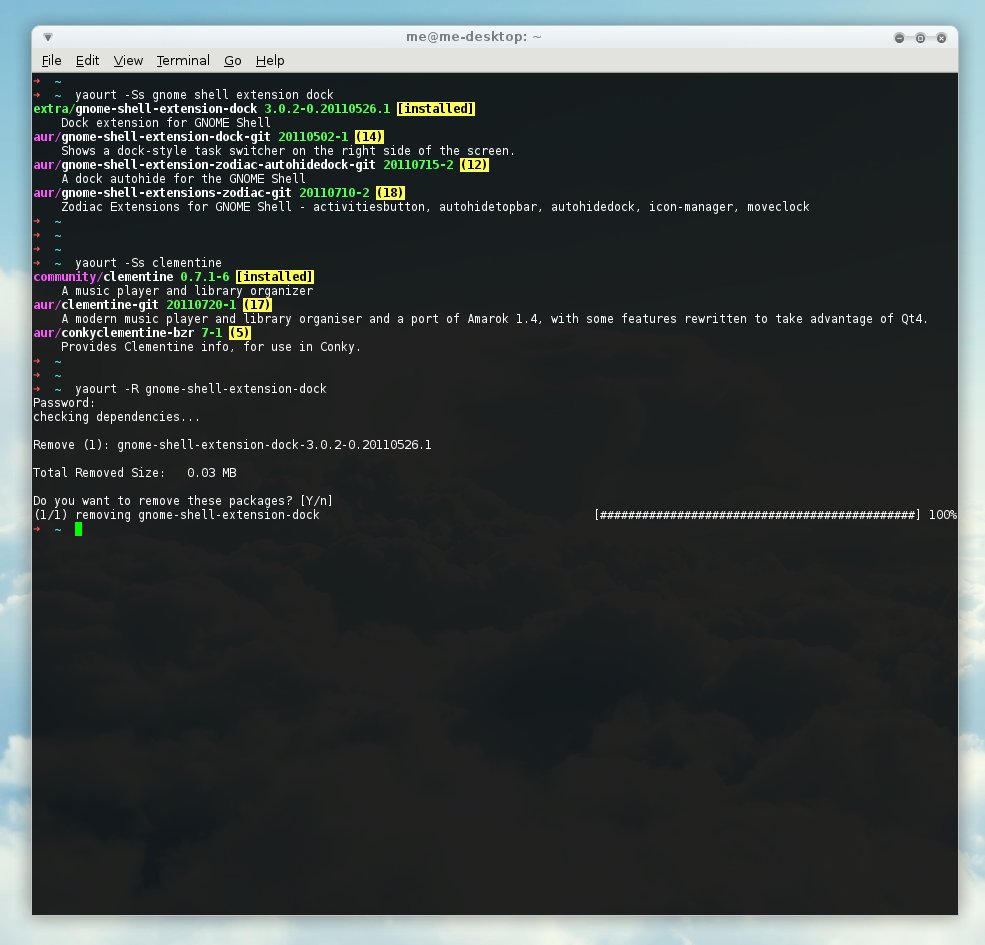
yaourt für Archlinux (Arch User Repository)
Ich benutze yaourt als AUR-Paketmanager bei Archlinux, in meinem ”Warum Arch…“-Artikel hatte ich darüber schonmal geschrieben.
vim als Editor & zum Programmieren
Vim ist ein sehr anpassungsfähiger Terminal-Editor, der bei richtiger Konfiguration auch and umfangreiche IDEs herankommen kann. Der Nachteil ist, dass etwas Einarbeitung notwendig ist, damit man die Stärken von vim erkennt. Empfehlen kann ich als Einstieg den Artikel vim HowTo aus dem Suckup.de-Blog von Lars und den Artikel Überblick: vim-Plug-ins aus dem Blog von DSIW. Meine eigene vim-Konfiguration und die von mir verwendeten Plugins findet man auf github im dotfiles bzw. vim Repository.
git als Versionsverwaltung für Projekte
Besonders bei der Programmierung, aber auch bei anderen textbasierten Projekten hilft git als Versionsverwaltungstool ungemein. Als Einstieg eignet sich beispielsweise githowto.com. Da die Community von git stetig wächst, gibt es aber auch sonst genügend Anlaufstellen im Netz, um die einigen git-Kenntnisse zu verbessern. Einfach mal die Suchmaschine des Vertrauens fragen! Auch ist es selbstverständlich am produktivsten, git durch learning by doing zu erlernen, indem man z.B. mit einem eigenen Git-Projekt auf github.com arbeitet.
Systemtools
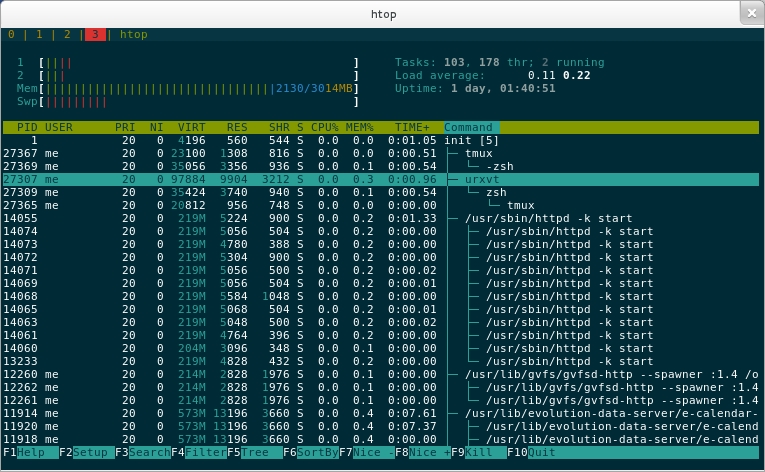
htop
Viele werden das Tool top kennen, das die laufenden Prozesse, sowie deren Auslastung im System anzeigt. htop ist im Prinzip das selbe, aber besser! htop bietet weitere Optionen per Tastaturkürzel an, wie z.B. die Unterschiedliche Sortierung nach bestimmten Kriterien.
iostat
iostat liefert ausführliche Informationen über CPU- und Festplattenauslastung.
Powertop (2)
Powertop bietet einige Tipps und Tweaks, um den Energieverbrauch unter Linux zu reduzieren. Besonders Laptop-Nutzer sollten dieses Tool auf der Liste haben. Die stable-Version von Powertop ist bereits recht alt, die Beta von Powertop 2 funktioniert bei mir jedoch reibungslos und hat sich auch in Sachen Übersichtlichkeit verbessert.
lsof
lsof listet die geöffneten Dateien aller Prozesse auf, kann aber auch verwendet werden, um offene Netzwerkverbindungen anzuzeigen. Beispielsweise zeigt der nachfolgende Befehl die offenen Verbindungen des Benutzers http (der Benutzer des Apache Webservers unter Archlinux) an:
$ sudo lsof -a -i -u http
pmap
pmap listet bei Angabe der Prozess-ID die Belegung des Arbeitsspeichers der jeweiligen Task auf. Besonders hilfreich ist das, wenn Prozesse Amok laufen und viel zu viel Speicher belegen.
Resourcenhunger von Prozessen begrenzen
Manche Prozesse haben das Bedürfniss, grundlos möglichst viele Ressourcen im System zu belegen. Flash und Java fallen mir in dieser Hinsicht häufiger negativ auf. Mit CPULimit lässt sich der CPU-Konsum solcher Prozesse glücklicherweise in die Schranken weisen. Auch beim I/O-intensiven Prozessen, z.B. dem Kopieren von Dateien geht das System manchmal in die Knie. Hier kann ionice helfen (Artikel dazu).
Auch kann es helfen, sich den Fortschritt beim Kopieren von Daten ausgeben zu lassen, um zu erkennen, ob der Prozess überhaupt noch reagiert. Dafür eignet sich beispielsweise pv. Ich setze gerne pycp/pymv statt cp/mv beim Kopieren/Verschieben größerer Dateien ein, denn das zeigt mir den Fortschritt direkt beim Kopierprozess:

Dateitools
Bilder: imagemagick, exif und jhead
Mit imagemagick steht ein ganzes Paket an Befehlen zur Verfügung, um Bilder per Kommandozeile zu bearbeiten. Gerade wenn man häufig Bilder in andere Formate umwandeln muss, bietet es sich hier an, die Website und die man-Pages von imagemagick anzuschauen und entsprechende Scripts zur Automatisierung solche Prozesse zu schreiben.
Exif kann Metadaten von JPEG-Bildern auslesen und auf der Konsole ausgeben. Zusammen mit jhead kann man es beispielsweise dazu verwenden, Fotos automatisiert umzubennen.
PDF-Dateien: pdfjam & pdftk
Wer wie ich in einer von Windows beherrschten Welt unbeirrrt Linux als Hauptsystem einsetzt, hat bei Worddokumenten das Problem, dass diese auf jedem System verschieden aussehen können. Glücklicherweise kann mit Dateien im PDF-Format nicht viel schief gehen, weshalb das mein beforzugtes Format ist, wenn ich Dokumente an andere Personen schicke. Das Bearbeiten oder Zusammenstellen von PDFs geht oft über die Kommandozeile am schnellsten. Ich benutze dabei pdfjam und pdftk, wobei sich pdfjam sehr gut eignet, um aus Bilddateien eine PDF zu bauen:
$ pdfjam *.jpg --outfile test.pdf
Das oben genannte imagemagick kann solche Dinge zwar auch, allerdings war bei mir Dateigröße und Qualität nie so zufriedenstellend wie bei pdfjam. pdftk ist ein recht umfangreiches Toolkit für typische Anwendungsfälle mit PDFs. (weitere Infos gibt’s auf der Homepage)
Löschen / Wiederherstellung
extundelete kann gelöschte Dateien von ext3 und ext4-Partitionen wiederherstellen. Den entsprechenden Gegenpart bildet shred, ein Tool mit dem Daten beim Löschen mehrfach überschrieben werden können und somit nur sehr schwer wiederherstellbar sind. Menschen mit noch größerem Hang zu Paranoia, sollten vermutlich secure-delete verwenden.
Multimedia
abcde
A better CD Encoder, kurz abcde ist eine Script-/Toolsammlung, die dazu benutzt werden kann, um auf simple Art und Weise Audio-CDs zu encodieren und taggen. Über die Konfigurationsdatei kann das Toolset recht gut angepasst werden. (meine .abcde.conf)
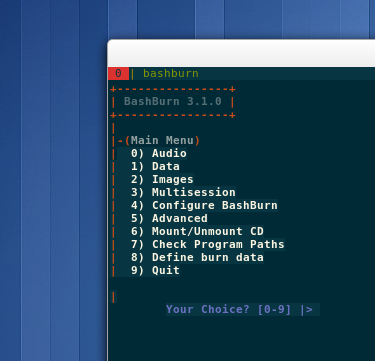
bashburn
bashburn ist ein simples & übersichtliches Brennprogramm für die Shell.
moc und mocp
moc (bzw. den mocp Player, einen guten Überblick gibt es im ArchWiki) benutze ich als simplen Audioplayer. Moc besteht aus einem Client (mocp), mit dem man den Player steuert, und einem Daemon, der im Hintergrund läuft. Dadurch ist es auch leicht möglich, die Playlist von anderen Rechnern aus per ssh zu verändern, da der Clientprozess weitgehend unabhängig vom Daemon ist.
Internet
(open)ssh + scp + sshfs
Es gehört zwar schon fast zur Standardausstattung, dennoch will ich ssh, scp (Dateien über ssh kopieren) und sshfs (Dateisysteme von entfernten Rechnern lokal mounten) hier nicht unerwähnt lassen. Wenn man mit mehreren Rechnern zu tun hat, bietet openssh eine gute Möglichkeit, auf sichere Weise auf entfernte Systeme zuzugreifen.
wget
Auch der Befehl wget sollte den meisten ein Begriff sein. Wget ist ein gutes Download-Tool, das auch in Shell-Script oft sehr gut zu gebrauchen ist.
mutt
mutt ist ein Mailclient, den ich wegen seiner Übersichtlichkeit und der simplen Handhabung schätze. Es gilt das Motto: “All mail clients suck. This one just sucks less.” - ganz so schlimm ist es aber doch nicht! ;)
tyrs (Homepage) ist ein feiner Microblogging-Client für Twitter und Identica, den man sehr gut nebenher im Hintergrund laufen lassen kann! Er basiert auf ncurse.
Irssi ist ein sehr anpassungsfähiger IRC-Client der Zukunft!
finch
Finch ist quasi Pidgin (Instant Meeaging Client) für die Konsole: Es handelt sich um ein Frontend für libpurple. Hilfreich ist, sich vor der Benutzung die Tastaturkürzel mit man finch anzuschauen.
Netzwerkanalyse: tcpdump, nmap
Mit Tcpdump lässt sich - ählich wie mit dem GUI-Tool Wireshark der Netzwerkverkehr ausgeben und analysieren. Dank der Konsole kann man hier die Ergebnisse auf einfach Weise filtern. Beispielsweise könnte man den Verkehr auf Port 80 (HTTP Protokoll) überwachen mit:
$ tcpdump -i eth0 'port 80'
Mit nmap steht auf der Konsole ein guter Portscanner zur Verfügung.
Kleine Helfer
bc
Die Linux Shell eignet sich leider nicht sonderlich gut als Taschenrechner. Diese Lücke schließt das Tool bc, mit dem man gängige Rechnungen sehr gut auch mit der Kommandozeile lösen kann.
bashmount
bashmount ist ein kleines mount-Verwaltungs Tool, das gemoutete Laufwerke sowie Informationen zu ihnen anzeigt. Das ist ganz nützlich, wenn man mit vielen verschiedenen Laufenwerken zu tun hat, um schnell einen Überblick zu bekommen.
watch
watch startet einen festgelegten Befehl im Terminal und führt diesen alle x Sekunden erneut aus. Damit lassen sich also sehr einfach Dinge überwachen, ohne extra Bashscripts mit for-schleifen anlegen zu müssen.
autojump
Einer der häufigsten Befehle die man auf der Kommandozeile eintippt, dürfte der cd-Befehl zum Wechseln von Verzeichnissen sein. Oft arbeitet man aber dennoch in den gleichen Unterverzeichnissen. Autojump ist eine super Sache, denn das Tool merkt sich die benutzen Verzeichnisse beim cd-Befehl. (jumpstat zeigt die gespeicherten Pfade an) Die Verzeichnisse erreicht man anschließend direkt ein einziges Schlüsselwort, das in dem Pfad vorkommt. Beispiel: Um neue Beiträge für dieses Blog zu schreiben, muss ich häufig in den Ordner /srv/http/jekyll/_posts wechseln. Nachdem ich das ein paar Mal getan habe, kennt autojump diesen Pfad und ich kann künftig einfach per
in diesen Ordner springen.
logger
Will man für eigene Scripts Logs nach /var/log schreiben, so ist das mit dem Befehl logger sehr einfach möglich. Durch ein simples
logger "Script xy war erfolgreich."
Wird z.B. eine passende Meldung mit der Nennung des aktuellen Benutzers an die /var/log/messages.log angehängt.
w3m
Bei w3m handelt es sich um einen sehr simplen Webbrowser, mit dem man sich z.B. den Text einer Website auf der Konsole ausgeben lassen kann. Beispiel:
$ w3m -dump istwulffnochimamt.de | head -3
Ist Wulff noch im Amt?
Ja.
Damit lassen sich aber natürlich auch sehr viel sinnvollere Dinge anstellen. Eine interessante Idee habe ich z.B. bei Natenom´s Blog gefunden, nämlich die Umsetzung von Wörterbuchabfragen über die Konsole mittels w3m. Dafür habe ich folgende Funktionen in meine ~/.zshrc (benutzt man Bash als Shell wäre es die ~/.bashrc) eingetragen:
function dict() {
w3m -dump "http://pocket.dict.cc?s=\"$*\"" | sed -r -e '/^([ ]{5,}.*)$/d' -e '1,2d' -e '/^$/d' -e '/^\[/d'
}
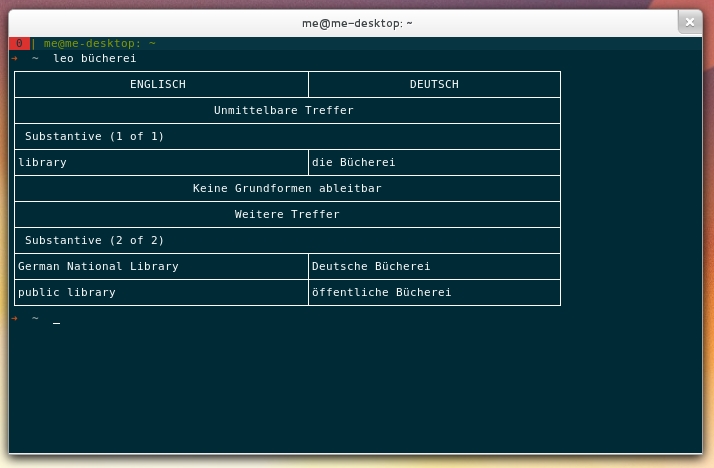
function leo() {
w3m -dump "http://pda.leo.org/?search=\"$*\"" | sed -n -e :a -e '1,9!{P;N;D;};N;ba' | sed -e '1,14d'
}
function leofr(){
w3m -dump "http://pda.leo.org/?lp=frde&search=\"$*\"" | sed -n -e :a -e '1,9!{P;N;D;};N;ba' | sed -e '1,14d'
}
Somit kann ich nun komfortabel und schnell nach Begriffen suchen, ohne extra die jeweilige Seite im Browser ansteuern zu müssen:
Eigene Aliase und Funktionen sind eine weitere gute Möglichkeit, produktiver mit der Shell zu arbeiten. (=> meine .zshrc)
sed
Da bei der Wörterbuch-Funktion von oben auch der Befehl sed benutzt wird, will ich auch diesen noch empfehlen. Es handelt sich dabei um einen Stream Editor, mit dem man z.B. den Text der Standardaußgabe verändern kann. Das Tools ist sehr mächtig, setzt aber etwas Einarbeitung voraus. Eine ausführliche Einführung gibt es z.B. bei grymoire.com, außerdem kann ich die “Sed-Onliners explained”-Serie und die Beispiele bei sed.sourceforge.net (auch dort gibt es eine interessante SED 1-Liner-Zusammenstellung) empfehlen.
Eure Lieblingstools?
Wie eingangs schon geschrieben, enthält dieser Artikel nur die von mir (mehr oder weniger) regelmäßig verwendeten Tools. Über eure Kommentare und Ergänzungen bin ich deshalb gespannt! Welche CLI-Anwendungen setzt ihr ein und welche Produktivitäts-Tipps habt ihr noch für den Terminal-Bereich?
 Michael Larabel von Phoronix macht wenig Hoffnung, dass Unterstützung für Microsofts exFAT-Dateisystem im Linux-Kernel 3.3 landet. Extended File Allocation Table (exFAT) wurde von Microsoft speziell für Flash-Speicher-Geräte geschaffen, auf denen FAT32 oder NTFS nicht ideal ist. Die Linux-Unterstützung hat sich seit 2009 auch nicht wirklich verbessert.
Michael Larabel von Phoronix macht wenig Hoffnung, dass Unterstützung für Microsofts exFAT-Dateisystem im Linux-Kernel 3.3 landet. Extended File Allocation Table (exFAT) wurde von Microsoft speziell für Flash-Speicher-Geräte geschaffen, auf denen FAT32 oder NTFS nicht ideal ist. Die Linux-Unterstützung hat sich seit 2009 auch nicht wirklich verbessert.