Um den Netzwerktraffic unter Linux zu analysieren, gibt es zahlreiche
Werkzeuge wie ethstatus, iptraf oder
iftop. Allerdings zeigen die
meisten Programme nur von und zu welcher IP der Datenverkehr durch die
Leitung geschickt wird oder wie viel gerade fließt. Möchte man dagegen
wissen, welcher Prozess den meisten Netzerwerkverkehr gerade im Moment
verursacht, tappt man bei den genannten im Dunkeln. Das Licht schafft
hier das kleine Kommandozeilenwerkzeug Nethogs.
Allerdings gibt es vorab erwähnt auch ein paar kleinere Feature-Lücken:
So kann keine Sortierung nach Programmnamen stattfinden, Nethogs muss
immer mit Root-Rechten ausgeführt werden, zeigt nur den aktuellen
Netzwerkverkehr und lässt UDP unter den Tisch fallen (relevant zum
Beispiel für BitTorrent).
Installation
Das Progamm findet sich eigentlich in jedem Repositorium einer
Linux-Distribution, zum Beispiel
Ubuntu oder Arch
Linux.
Notfalls kann man aber auch den Quellcode selbst
kompilieren.
Verwendung
Grundsätzlich lässt sich Nethogs mit dem gleichnamigen
Kommandozeilen-Befehl ausführen. Jedoch sind dazu Root-Rechte notwendig.
1
$ sudo nethogs
Standardmäßig lauscht Nethogs an eth0. Verwendet man allerdings WLAN
übergibt man – für die erste WLAN-Schnittstelle – wlan0 als Parameter.
1
$ sudo nethogs wlan0
Sollte das immer noch nicht zu Erfolg führen, gibt der folgende Befehl
alle lokalen Netzwerkschnittstellen aus.
1
$ ifconfig
Die gewünschte Schnittstelle dann Nethogs entsprechend als Parameter
übergeben. Danach präsentiert sich Nethogs als ncurses-Oberfläche wie im
Screenshot.
So tabellenartig sieht Nethogs aus.
Die einzelnen Spalten sind eigentlich selbsterklärend. Zudem kann man
über Tastenkürzel Nethogs ein wenig anpassen; kurz die meiner Meinung
nach wichtigsten Optionen:
M: Zwischen den Einheiten KB/s, KB, B oder MB umschalten
R: Sortierung nach empfangenen Daten (received)
S: Sortierung nach gesendeten Daten (send)
Q: Programm schließen (Alternative zu Strg + C)
Die (kleine) Liste aller Optionen finden sich entweder in der manpage
oder auf Deutsch im
Ubuntuusers-Wiki.
Fazit
Nethogs ist ein kleines Werkzeug, das einfach nur macht, was es soll –
nämlich den aktuellen Netzwerkverkehr auf die einzelnen Prozesse
aufgliedern. Die bestehenden „Problemchen“ wie fehlende
UDP-Unterstützung oder Sortiertung allein nach Datentraffic werden ggf.
in einer nächsten Version ausgebügelt.
Ohloh erinnert mich an ein modernes freshmeat, auch wenn das inzwischen freecode heißen mag. Es listet Softwareprojekte mit ihren Metadaten, baut aus ihrem Quellcode nette Statistiken und zieht Schlussfolgerungen über den Zustand des Projektes.
Das funktioniert nicht immer fehlerfrei, aber die Fehler sind verständlich. So denkt Ohloh, dass izulu ein neues Projekt sei, weil der Code auf Github eben erst vor drei Monaten eingecheckt wurde und vorher fast 5 Jahre in Archiven auf sourceforge herumlag, mit denen es natürlich nichts anfangen kann.
Bei Serendipity stoppte die Analyse auf einem Stand von vor mehreren Jahren, wahrscheinlich kam es mit dem abgeschalteten - aber nicht aus der Repoliste entfernten - berlios-svn nicht zurecht. Dem abgeholfen denkt es, dass s9y zu 30% aus XML-Dateien bestehen würden, weil die XML-Dateien in additional_plugins eben entsprechend groß sind. Und ausschließen kann man sie nicht alle, dafür sind sie zu viele (mehr als 1000 Zeichen verbietet das Disallow-Tool). Edit: Ich habe da nochmal drüber nachgedacht und jetzt einfach das Repo rausgeschmissen, sodass nur s9y selbst analysiert wird. Ermöglicht einen besseren Vergleich mit Wordpress.
Der Sprung um 1 Millionen LoC Ende 2011 ist wohl eine Fehlberechnung, weil seitdem git und svn parallel betrieben werden
Aber zumindest werden jetzt die Serendipity-Statistiken überhaupt wieder berechnet, und aus einem vermeintlich toten Projekt ist ein angeblich sehr aktives geworden, was inzwischen auch wirklich stimmt. Und ich glaube, den 2.0-Branch ignoriert er, das wird nach dem Merge nochmal ein hübscher Sprung, zumindest bei den Commits.
Die Projekte so präsentiert zu sehen ist hübsch, und sicher nicht unnütz, falls sich ab und an Nutzer tatsächlich damit ein Bild einer bestimmten Software machen, oder eher Entwickler Projekte in einem bestimmten Feld suchen.
Für mich spaßiger sind die Entwicklerstatistiken. Als Entwickler kann ich meine Commits claimen, und Ohloh baut dann für mich ein paar Graphen und Fakten. So sei ich am erfahrensten in PHP, was mit meinem Selbstbild kollidiert, aber inzwischen wahrscheinlich schlicht stimmt, auch wenn ein gewisser Teil meines PHPs s9y-spezifisch sein dürfte.
Dann noch ein paar Badges dazu und schon hat die Seite es geschafft, dass ich mein Profil dort ein bisschen ausgefüllt habe. Und nebenbei fehlende Projekte in das Register eingetragen habe, was den Wert der Seite erhöht - saubere Manipulation mithilfe der eigenen Eitelkeit, oder nennen es wir Interesse; gutes Handwerk.
Ich finde es gut, eine zusätzliche und moderne Softwarepräsentationsseite gefunden zu haben. Es ist nun sicher nicht so, dass ich die Seite täglich besuchen werde, aber ab und an mal vorbeischauen oder mich von dort auf die eigentliche Projektwebseite leiten zu lassen, das kann ich mir schon vorstellen. Und als Gegengewicht für Github erfüllt es auch eine sinnvolle Funktion, sodass dieses neben dem Hosten der Projekte selbst nicht zwingend auch Hauptanlaufpunkt für Statistiken der Projekte und Selbstrepräsentation der Entwickler sein muss.
Seit der automatischen Upgrade-Funktion von Piwik geht das Update auf eine neue Piwik-Version bekanntlich schnell und unkompliziert. Ich habe bereits die eine oder andere Version über die Funktion aktualisiert und seither noch nie ein Problem gehabt – doch einmal ist ja bekanntlich immer das erste Mal:
Failed to load HTML file: Please check your server configuration. You may want to whitelist “*.html” files from the “plugins” directory. The HTTP status code is 404 for URL “plugins/ZenMode/angularjs/quick-access/quick-access.html“
Diese Meldung spuckt mir das Webinterface nach einem erfolgreichen Upgrade entgegen. Und sie hat nicht ganz unrecht – wenn ich die Datei im Browser direkt öffnen möchte, so erhalte ich eine Zugriffsverletzung…
Um die Meldung wegzubekommen (eine Einschränkung in der Funktionalität konnte ich bisweilen nicht feststellen), müssen die Berechtigungen auf 3 Ordner von 750 auf 755 geändert werden:
Hierbei sollte auch nur die Berechtigung der Ordner und nicht der Dateien angepasst werden, da dass Erlauben zum Ausführen für Alle mir bereits etwas Bauchschmerzen bereitet.
OpenOffice.org war eine quelloffene Bürosoftware, welche im Jahr 2000 aus dem Quellcode des kommerziellen Office-Programms StarOffice hervorgegangen ist. Teil von OpenOffice.org waren die Anwendungen Writer (Textverarbeitung), Calc (Tabellenkalkulation), Impress (Präsentationen), Draw (Zeichnen), Base (Datenbanken) sowie Math (Formel-Editor).
Im September 2010 haben zahlreiche Entwickler der Office-Suite OpenOffice.org dem Projekt – wegen Meinungsverschiedenheiten mit der Firma Oracle – den Rücken gekehrt und das LibreOffice-Projekt gegründet, welches von der Stiftung The Document Foundation getragen wird. Grundlage für LibreOffice war der Quellcode von OpenOffice.org.
Daraufhin hat sich Oracle im Juni 2011 komplett aus dem OpenOffice.org-Projekt zurückgezogen und die Entwicklung sowie die Markenrechte von OpenOffice.org in die Hände der Apache Software Foundation gelegt, welche das Office-Paket von OpenOffice.org in Apache OpenOffice umbenannte.
Co-Existenz zwischen Apache OpenOffice und LibreOffice
Seitdem (Stand: Juni 2014) herrscht eine Co-Existenz zwischen den beiden kostenlosen Office-Programmen, was vor allem bei EDV-Laien nach wie vor zu Verwirrungen führt.
Nachdem OpenOffice.org jahrelang zur Standardinstallation der meisten Linux-Distributionen gehörte, wird heutzutage LibreOffice vorinstalliert. Bei den meisten Distributionen ist OpenOffice gar nicht mehr in den offiziellen Repositories vorhanden und somit im Linux-Umfeld fast schon etwas von der Bildfläche verschwunden.
Apache OpenOffice: Totgesagte leben länger
Obwohl die Entwicklung bei LibreOffice (kurz LibO) – aufgrund der vielen Entwickler – sehr zügig vorangeht, sollte man Apache OpenOffice (kurz AOO) keineswegs abschreiben. Erst kürzlich wurde wieder eine neue, verbesserte OpenOffice-Version veröffentlicht.
Ausserdem erfreut sich OpenOffice unter Windows-Anwendern immer noch grosser Beliebtheit, da die Marke OpenOffice traditionell für eine kostenlose aber ebenbürtige MS-Office-Alternative steht. Des Weiteren dürfen die Entwickler der Apache Software Foundation bei der Entwicklung von Apache OpenOffice auf die Unterstützung des IT-Giganten IBM zählen.
IBM hat in Version 4.0 von OpenOffice beispielsweise eine Seitenleiste integriert, mit welcher man Zugriff auf die wichtigsten Funktionen der Textverarbeitung, der Tabellenkalkulation sowie des Zeichenprogramms erhält.
Zum Entwicklerteam von LibreOffice gehören nicht nur ehemalige OpenOffice.org-Entwickler, sondern auch zahlreiche bekannte Unternehmen aus dem Open-Source-Umfeld wie z.B. Red Hat, Univention, SUSE und Google. Auch Canonical, die Firma hinter dem beliebten Linux-Betriebssystem Ubuntu, zählt zu den Unterstützern von LibreOffice.
Kompatibilität zwischen Apache OpenOffice, LibreOffice und MS-Office
Wie schon OpenOffice.org verwenden auch Apache OpenOffice und LibreOffice das OpenDocument-Format (kurz: ODF) als Standard-Dateiformat. Dieses entspricht der internationalen ISO-Norm ISO/IEC 26300.
Mit diesem Dokumenten-Standard bleibt gewährleistet, dass ODF-Dateien mit beiden freien Officepaketen erstellt, gelesen und verändert werden können, egal ob diese ursprünglich mit Apache OpenOffice oder mit LibreOffice erstellt wurden.
Im Hinblick auf die verbreiteten Microsoft-Formate (doc, docx, xls, xlsx, ppt, pptx, usw.) sind beide Open-Source-Projekte bestrebt, eine gute Kompatibilität zu gewährleisten. Mit jedem grösseren Update wird die Darstellung dieser Formate wieder ein Stück verbessert.
Zu erwähnen ist, dass es für die Entwickler von Apache und The Document Foundation schwierig ist, eine 100 %ige Kompatibilität mit MS-Formaten zu gewährleisten, da Microsoft die Spezifikationen seiner eigenen Formate absichtlich nicht vollständig der Öffentlichkeit freigibt, um seine Monopolstellung im Software-Bereich zu bewahren. Diese traurige Tatsache hindert viele Unternehmen daran, auf freie Software umzusteigen.
Aussehen
Die Optik von Apache OpenOffice und LibreOffice ähnelt visuell sehr der 2003er-Version von MS-Office. Aber auch Umsteiger anderer MS-Office-Versionen dürften sich mit ein bisschen Lernbereitschaft mit den freien MS-Office-Alternativen rasch zurechtfinden.
Screenshots der Linux-Version von Apache OpenOffice 4.1 (zum Vergrössern anklicken)
Screenshots der Linux-Version von LibreOffice 4.1 (zum Vergrössern anklicken)
Die Namen der einzelnen Programmmodule sind bei Apache OpenOffice und LibreOffice dieselben geblieben; doch unterscheiden sich die Programmsymbole der beiden Office-Suiten weitgehend voneinander.
Auffällig ist, dass Apache für OpenOffice dieselben Programmicons verwendet, wie das „Vorgänger“-Projekt OpenOffice.org. The Document Foundation hat die Icons von LibreOffice stattdessen ganz dem Logo der eigenen Stiftung angepasst.
Kosten / Lizenz
Für den normalen Endanwender dürfte die Lizenz des Quellcodes der beiden Office-Suiten keine grosse Rolle spielen. Schliesslich ist die Benutzung von Apache OpenOffice und LibreOffice für die meisten Menschen eine Kostenfrage. Beide Office-Pakete sind und bleiben der Öffentlichkeit weiterhin sowohl in Binärform für GNU/Linux, Windows und Mac OS X als auch im Quelltext kostenlos zugänglich.
Anders sieht es bei Software-Entwicklern aus. Apache OpenOffice und LibreOffice stehen beide unter zwei verschiedenen freien Software-Lizenzen. Während Apache das OpenOffice-Projekt unter die hauseigene Apache-Lizenz v2.0 stellte, hat The Document Foundation das LibreOffice-Projekt dreifachlizensiert. LibreOffice steht nicht nur unter der General Public License v3+ (GPL), sondern auch wahlweise unter der Lesser General Public License v3+ (LGPL) und der Mozilla Public License v2.0.
Die Apache Lizenz v2.0 ist mit der (Lesser) General Public License v3 kompatibel, andersrum aber nicht. Als Folge daraus können Änderungen am Quellcode von Apache OpenOffice vom LibreOffice-Team in dessen Sourcecode übernommen werden, umgekehrt jedoch nicht.
Dies ist ein entscheidender Nachteil von Apache OpenOffice in Sachen Lizenzierung. LibreOffice kann sich sozusagen „legal“ am Code von OpenOffice bedienen, da dies die liberale Apache Lizenz zulässt.
Die von der Firma IBM in Apache OpenOffice 4.0 integrierte – oben erwähnte – Seitenleiste konnte von den LibreOffice-Entwicklern aufgrund dessen in LibreOffice 4.2 eingefügt werden. Die Seitenleiste ist in LibreOffice übrigens zwar standardmässig deaktiviert, kann aber im Menüpunkt Ansicht -> Seitenleiste dauerhaft aktiviert werden.
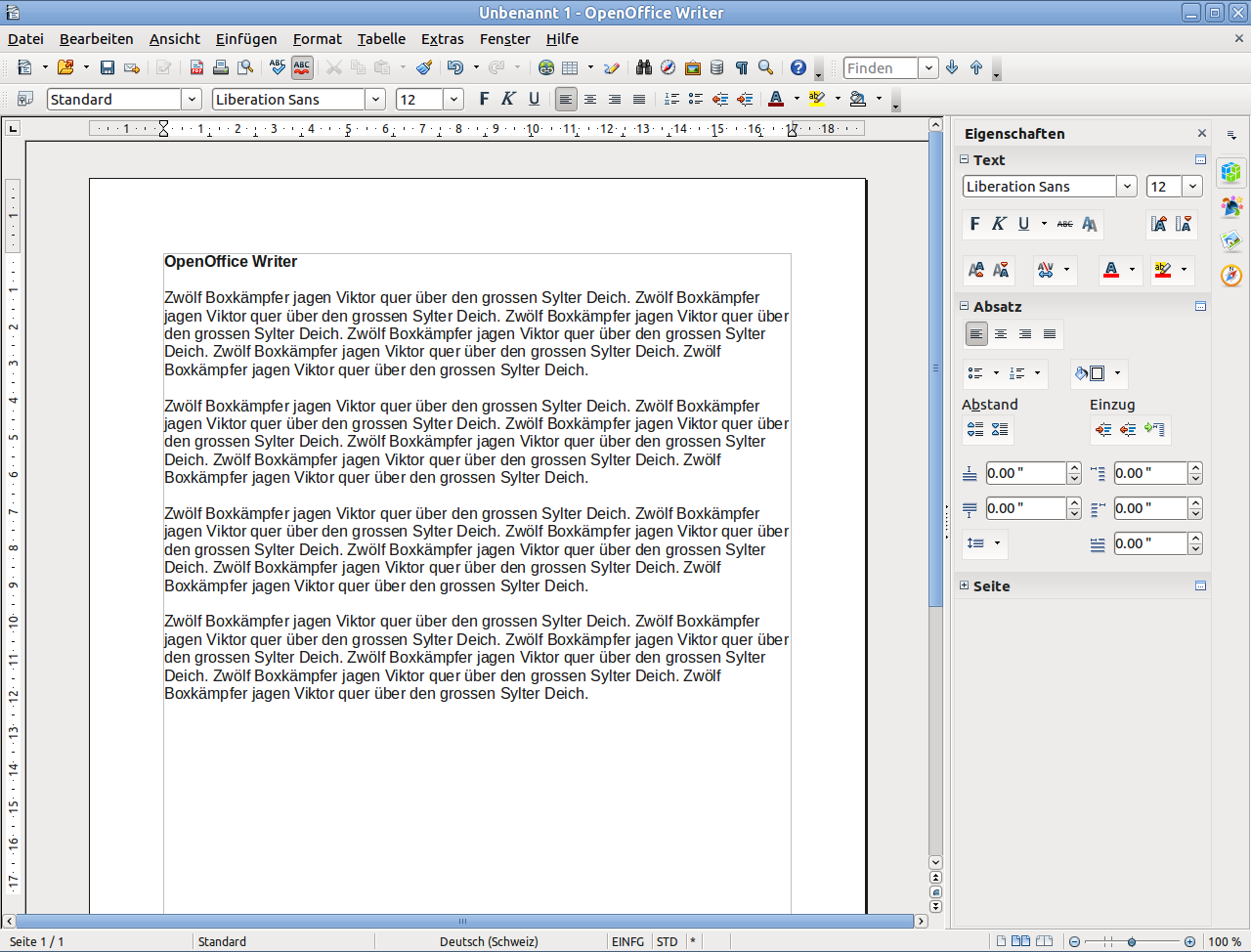
Apache OpenOffice Writer 4.1 unter Ubuntu Linux mit Seitenleiste (siehe rechts vom Bild)
Fazit
Für Otto-Normal-Benutzer spielt es grundsätzlich keine Rolle, ob man sich für Apache OpenOffice oder LibreOffice entscheidet. Beide MS-Office-Alternativen sind kostenlos für alle verbreiteten Betriebssysteme herunterladbar. Bei der Entwicklung von Apache OpenOffice legen die Entwickler hohen Wert auf Stabilität und Zuverlässigkeit. Bei LibreOffice liegt der Fokus bei der Entwicklung vor allem auf der Integration neuer Funktionen und Verbesserungen. Dies ist zumindest mein persönlicher Eindruck.
Tipp für ältere, leistungsschwache Computer
Sowohl Apache OpenOffice als auch LibreOffice eignen sich problemlos auch für ältere Computer – sofern genügend CPU-Leistung und Arbeitsspeicher vorhanden ist. Wer jedoch zuhause einen – aus heutiger Sicht – leistungsschwachen PC stehen hat und für diesen ein leichtgewichtiges Schreibprogramm sowie eine ressourcensparende Tabellenkalkulation sucht, findet vielleicht auch in Abiword und Gnumeric eine Alternative. Beide sind ebenfalls Open-Source und kostenlos.
Puzzle sind nicht nur gut für die Wand sondern auch im Spielbereich eine tolle Sache.
Bei dem indie Spiel Spirits geht es wie beim puzzeln darum kleine Rätsel mithilfe von verschiedenen Objekten zu lösen.
Die Deutschen Entwickler von Spaces of Play verfolgen dabei ein Interessantes Spielprinzip.
Quelle – Bildschirmfoto von Spirits
Inhalt
Wem beim puzzeln Freude aufkommt wird sich bei Spirits sicher wohl fühlen da hier jedes Level ein kleines Puzzle darstellt.
In dem Spiel muss der Spieler die Elemente des Herbstes nutzen um die kleinen Geister zum Ziel zu befördern.
Der Wind spielt dabei eine wichtige Rolle da dieser zusammen mit anderen Aktionen zum überwinden von Hindernissen benutzt wird.
Um eine Kante zu überwinden können Brücken aus Laub gebaut werden jedoch wird bei jeder Aktion ein Geist nicht zum Ziel kommen.
Weiter kann der Spieler Aktionen wie dass erschaffen von Windwolken, graben von Tunneln oder dass anhalten des Windes an bestimmen stellen nutzen.
In höheren Level müssen neben der bestimmten Anzahl von Geistern auch andere Aufgaben wie dass einsammeln von Pflanzen erledigt werden.
Grafik
Die grafische Gestaltung von Spirits ist rundum gelungen, den Spieler erwartet eine Welt voller kräftiger Farben die an den Herbst erinnern.
Bei den Animationen wurde sauber gearbeitet sodass hier flüssige Bewegungen dargestellt werden.
Quelle – Bildschirmfoto von Spirits
Infos und Details
Preislich liegt Spirits mit 7.49 Euro in einem guten Bereich der auch einen Spontan kauf nicht ausschließt.
Um dass Spiel zu Spielen kann der Spieler fast jedes Gerät nutzen da Versionen für die Plattformen Linux, Mac, iOS, Android und Windows verfügbar sind.
Erhältlich ist Spirits auch in dem Humble Store inklusive DRM-Freier Version.
Über die Option Online Highscore in den Einstellungen kann der Spieler sich mit anderen vergleichen und seinen Platz auf der Liste im Menü einsehen.
Der Soundtrack ist angenehm und nervt den Spieler beim lösen von den Aufgaben nicht.
Die Systemanforderungen sind recht niedrig gehalten womit dass Spiel auch auf Laptops problemlos laufen sollte.
Linux Systemanforderungen
-Betriebssystem: Linux Ubuntu 12.04
-Arbeitsspeicher: 2 GB RAM
-Grafik: 256 MB Video RAM
-Festplattenspeicher: 200 MB frei
Quelle – Bildschirmfoto von Spirits
Bewertung
Kategorie
Wertung
Grafik
9/10
Gestaltung
8/10
Inhalt
7/10
Gesamt
24/30
Fazit
Mir hat dass Spiel sehr gefallen und für zwischendurch ist es wirklich gut geeignet.
Manchmal versinkt man in dem Spiel und bekommt die Zeit nicht mehr mit sodass die ein oder andere Stunde schnell vergangen ist.
Ich kann dass Spiel gut Gewissens weiterempfehlen, besonders den Puzzle Liebhabern.
Kleine Änderung für Nutzer der Aurora-Versionen von Firefox: Diese werden ab Version 32 nicht mehr täglich, sondern nur noch wöchentlich zum Update aufgefordert.
Es ist nur eine kleine Änderung der Standard-Konfiguration (app.update.promptWaitTime in about:config) der Aurora-Version von Firefox: Diese Einstellung legt fest, wie viele Sekunden nach der Anzeige, dass ein Update verfügbar ist, das Fenster erscheinen soll, welches zum Update und Neustart des Browsers auffordert.
Bislang lag die Standardeinstellung bei 86400 Sekunden und damit 24 Stunden, diese wurde nun für Aurora auf 604800 Sekunden und damit sieben Tage geändert. Aurora-Versionen sind die Firefox-Versionen, die zwischen den Nightly- und Betaversionen liegen und diejenigen, welche Mozilla Webentwicklern empfiehlt. Diese sollen durch diese Änderung, wenn sie ihren Browser länger durchgehend offen haben, nicht so häufig durch die Update-Aufforderung gestört werden. Daran, dass es tägliche Updates für die Aurora-Versionen gibt, ändert sich nichts.
Open Source sei Danke, gibt es seit 2012 einen Fork von Cube 2: Sauerbraten welcher auf den Namen Tesseract hört und dem Genre der Shooter zuordnen lässt. Ziel der Abspaltung ist es dabei modernere Rendertechniken wie dynamisches Licht und andere Dinge zu nutzen. Das wirkt sich sehr positiv auf das Aussehen der Level aus. Das Spiel als solches ist sehr schnell, so das man durchaus ein paar brauchbare Reflexe mitbringen sollte. Eine weitere Besonderheit von Tesseract ist der integrierte Editormodus, mit welchem man in der First Person Ansicht alleine oder kooperativ die Level bauen kann.
Eine Tesseract-Map
Bezogen werden kann Tesseract auf der offiziellen Webseite. Das Spiel ist für Mac OS X, Linux und Windows verfügbar. Der Quelltext ist in einer Subversion-Instanz zu finden. Lizenziert ist das ganze dabei unter der zlib-Lizenz.
Dateien können unter unixoide Betriebssysteme mit „find“ nach vielen Kriterien gesucht werden.
Shell :: Manual find
Suche nach Alter, Name, Benutzer, Typ und Größe sind standardmäßig vorhanden, aber wie werden Dateien in einem bestimmten Zeitraum gefunden?
Kleiner Trick, um die Datei Suche zeitlich einzugrenzen kurz notiert …
Zeitliche Suchkriterien werden relativ zur aktuellen Zeit angegeben. Im Vergleich zu einer bestehende Datei können neuere Dateien mit der Option „-newerXY“ gesucht werden.
Angenommen ein Server hatte ein Zeitfenster zur Wartung am 4.2 von 2 bis 4 Uhr und wir möchten Wissen, welche Änderungen im Dateisystem vorgenommenen wurden.
Die geänderten Dateien in diesem Zeitraum können mit zwei Hilfsdateien durch find aufgelistet werden. Eine Datei mit dem älterem und eine mit neuerem Zeitstempel können mit „touch“ erstellt werden.
Gist ist ein schneller Weg, um Code-Beispiele / Konfigurationen / etc. mit anderen zu teilen oder für sich selber aufzubewahren. Jedes “gist” wird dabei als eigenes git-Repository angelegt, so werden diese automatisch versioniert und andere können davon einen Fork erstellen.
Leider gibt es keine Tags für die erstellten “gists”, so dass man sich ein System überlegen muss, wie man die entsprechenden Code-Beispiele wiederfindet z.B.:
– entsprechend aussagekräftige Dateinamen verwenden
– den Type der Datei immer korrekt angeben
– Tags in der Beschreibung hinzufügen #Tag1, #Tag2
– Beschreibung kurz halten
1.) meine “gists”
gist.suckup.de: Diese Webseite habe ich erstellt, um einen schnellen Überblick über meine gists zu erhalten, außerdem habe ich einige Code-Playground und andere Infos hinzugefügt.
2.) Gists organisieren und sammeln
www.gistboxapp.com: Auf dieser Webseite kann man den gists richtige Tags zuordnen und diese somit besser organisieren. Jedoch kann man diese Tags nicht via github / api abrufen, so dass diese nicht in z.B. der IDE angezeigt werden. Außerdem bietet die Webseite eine Chome-Addon, mit welchem man sehr einfach Code-Beispiele von anderen Webseiten als “gist” abspeichern kann.
2.) IDE-Integration
Alle großen IDEs und Texteditoren haben git / gists bereits integriert oder bieten zumindest Plugins, um z.B. selektieren Quelltext direkt als gist abzuspeichern oder gists im Quelltext einzufügen.
– PhpStorm / IntelliJ (bereits integriert)
– Eclpise (Plugin: “EGit”)
– Sublime Text (Plugin: “gist”)
– vim (Plugin: “gist-vim”)
Ich habe schon vor einiger Zeit über die “.bashrc” berichtet und hier die Installation meiner dotfiles [~/.*] vorgestellt.
Heute möchte ich an einigen Bildern zeigen wie die Bash aussieht nachdem man die bereits erwähnten dotfiles installiert und wie man diese nach seinen Wünschen anpasst.
1.) der Code
.bashrc: Dies ist die Konfigurationsdatei der Bash, diese wird bei jedem Aufruf einer interaktiven Shell ausgeführt. In meiner .bashrc stehen zunächst einmal ein paar Informationen, wovon ich hier nur die entsprechenden Links nennen möchte, welche man sich einmal anschauen sollte:
.bash_profile: Diese Datei hat die selbe Aufgabe wie die .bashrc, wird jedoch “eigentlich” nur für Login-Shells aufgerufen. In diesem Fall wird die Datei jedoch auch für interaktive Shells verwende, da wir diese in der .bashrc inkludiert haben.
for file in ~/.{path,colors,icons,exports,aliases,bash_complete,functions,extra,bash_prompt};do [ -r "$file"]&&[ -f "$file"]&&source"$file"
done
unset file
In dieser Datei werden wiederum andere Shell-Konfigurationen geladen (siehe vorheriges Code-Beispiel), welche auch von anderen Shells (z.B.: der zsh) genutzt werden können.
Desweiteren werden einige Einstellungen in einer zweiten for-Schleife ausgeführt. Andere Einstellungen sind näher beschrieben bzw. nur für nicht root-User geeignet und werden daher einzeln ausgeführt.
.bash_prompt: Wie wir im vorherigem Code-Ausschnitt sehen konnten, wird diese Datei zum Schluss geladen, so dass wir zuvor definierte Funktionen und Variablen verwenden können.
# Local or SSH session?
local remote=""
[ -n "$SSH_CLIENT" ] || [ -n "$SSH_TTY" ] && remote=1
Wir prüfen, ob es sich hier um ein lokales Terminal oder um eine SSH Verbindung handelt, so dass wir den Hostnamen nur anzeigen, wenn dieser auch benötigt wird.
# set the user-color
local user_color=$COLOR_LIGHT_GREEN # user's color
[ $UID -eq "0" ] && user_color=$COLOR_RED # root's color
Root-User bekommen in der Prompt einen Roten-Usernamen angezeigt.
PS: die User-ID (UID) ist in der passwd zu finden: “cat /etc/passwd”
# set the user
local user="\u"
Die Zeichenkette “\u” wird beim Aufruf der Bash-Prompt in den entsprechenden Usernamen umgewandelt.
PS: hier gibt es eine Übersicht über weiter Zeichenketten, welche von der Bash-Prompt verarbeitet werden können z.B. die Uhrzeit
# set the hostname inside SSH session
local host=""
[ -n "$remote" ] && host="\[$COLOR_LIGHT_GREEN\]${ICON_FOR_AT}\h"
Wie bereits erwähnt zeigen wir den Hostnamen (“\h”) nur an, wenn es sich um eine Remote-Verbindung handelt.
if [[ -n $remote ]] && [[ $COLORTERM = gnome-* && $TERM = xterm ]] && infocmp gnome-256color >/dev/null 2>&1; then
export TERM='gnome-256color'
elif infocmp xterm-256color >/dev/null 2>&1; then
export TERM='xterm-256color'
fi
256 Farben in der lokalen Shell verwenden.
# INFO: Text (commands) inside \[...\] does not impact line length calculation which fixes stange bug when looking through the history
# $? is a status of last command, should be processed every time prompt prints
Da der Bash-Prompt bestemmte Zeichen nicht mag und wir davon einige in der bereits inkludierten “.colors“-Datei verwendet haben, müssen wir diese Variablen nun hier escapen.
Der Prompt wird in der Variable PS1 (“echo $PS1″) gespeichert und nach jedem Befehl auf der Kommandozeile neu aufgerufen / ausgeführt, daher rufen wir in der Variable wiederum Funktionen auf, so dass diese Funktionen ebenfalls erneut ausgeführt werden.
PS: “$?” muss als erstes ausgeführt werden, da dieser Befehl den Rückgabewert des letzten Kommandos zurückliefert
2.) Beispiele
- Root-User wird rot gekennzeichnet
- “✗” anzeigen, wenn der letzte Befehl nicht korrekte funktioniert hat
- Anzeigen des Hostnamens nur bei Remoteverbindungen
- Repository-Branch (git, svn) anzeigen
- Repository-Status anzeigen (! anfügen, wenn etwas nicht eingecheckt ist)
Vor einiger Zeit habe ich schonmal ueber Stereogramme (bzw.
Stereoskopie) geschrieben, aber ich wusste bis heute nicht, wie ich sowas selber
bauen kann.
Nun bin ich ueber eine Anleitung gestolpert, wie sowas geht und
moechte euch diese in etwas ausfuehrlicher nicht vorenthalten. Zumal
die Anleitung dort teilweise schon veraltet ist.
Meine Grundideen:
Stereogramme (SRIDS/SIS) aus verschiedenen Dingen (mit Gimp)
Animiertes Stereogramm aus einer drehenden Veganblume (mit Blender)
Noch kurz etwas allgemein zu Stereogrammen:
Ein Stereogramm (oder besser: Autostereogramm) ist ein
Einzelbild-Stereogramm, welches aus einem 2D-Bild durch optische
Taeuschung dem Gehirn ein 3D-Bild vorgaukeln kann.
Mehr dazu und wie genau das funktioniert, die Geschichte dazu usw.
befindet sich in der engl. Wikipedia.
Update (2014-07-26): Ich wurde per Mail gefragt, warum
ich darueber eigtl. schreibe. Nun, mein Vater hatte so ein Magic 3D-Buch,
dass ich als Kind sehr mochte, zumal ich es am Anfang nicht
hinbekommen hatte, daraus 3D-Bilder zu sehen. Und ich fand das schon
immer sehr faszinierend, wusste aber halt bisher nicht, wie sowas
selbst gemacht werden kann. Daher hier nun die Anleitung ;)
Stereogramm mit Gimp
Mit der Anleitung, die ich gefunden habe, kam ich erst mal gar
nicht klar. Allerdings habe ich dann ein besseres Tutorial gefunden
und mir wurde einiges viel klarer ;)
Dort wird beschrieben, wie sich ein Stereogramm zusammensetzt:
Stereograms essentially contain two images to create the 3D effect.
The first image is the Depth Map or Range Image [..].
The second image is the texture or pattern image [..].
Depth maps (Range Images) are made up of black, white, and gray
colors. The computer software takes white and brings it to the front,
black is sent to the back, and shades of gray fall in-between the two.
As you can guess, the lighter shades of gray appear closer than darker
shades of gray.
Textures or Pattern Images, can be any texture. However, it is
recommended you use a texture that is very random, as the stereogram
software will distort the texture to hide the depth map within it.
[The stereogram software] will also create textures
for you.
D.h. wir brauchen:
eine "depth map", d.h. ein Graustufenbild und
eine Textur oder Muster, in welcher das Graustufenbild "versteckt"
wird.
Das Graustufenbild besteht nur aus Schwarz, Weiss und allen Grautoenen
dazwischen. Schwarz befindet sich beim Endresultat im Hintergrund,
Weiss im Vordergrund und demnach die Grautoene dazwischen.
Die Software (in meinem Fall stereograph) kann Texturen selbst
erstellen, das werde ich aber gleich erklaeren.
Fuer den Anfang reicht also erstmal ein normales
Bildbearbeitungsprogramm wie Gimp, wobei es hier aber auch Vor-
und Nachteile gibt:
Vorteile:
aus 2D wird 3D (d.h. selbst ein sehr einfaches Programm wie
Paint kann dazu benutzt werden, ein Graustufenbild zu erstellen)
keine grossen Vorkenntnisse benoetigt
Nachteile:
komplexere Modelle nur schwierig zu erstellen
Depth Map auch nur rudimentaer
Nichtsdestotrotz will ich hier mal zeigen, wie das mit Gimp (oder
alternativ Inkscape, Krita, MyPaint, ...) geht.
Wir wollen nun solch ein SRIDS erstellen, und bauen zuerst mal ein
Graustufenbild mit Gimp (Meine Version: 2.8.10).
Dazu oeffnen wir Gimp, druecken Strg+N (fuer "Neu"), waehlen
640x480 aus der Vorlage aus, legen als Farbraum "Graustufen" und
als Fuellung "Vordergrundfarbe" (schwarz) fest.
Dann habe ich mit meinem Grafiktablett mit dem Stift-Tool (N) etwas
geschrieben (Farbe: #b5b5b5, Pinsel: 2. Hardness 050, Groesse: 20) ..
.. und dann noch eine Spirale mit dem Farbverlaufs-Tool (L)
hinzugefuegt (Deckkraft: 10.0, Farbverlauf: VG nach HG (RGB), Form:
Spirale (rechtsdrehend)) ..
.. und als sirds-dm.png exportiert (Umschalt+Strg+E).
Fertig ist unser erstes Graustufenbild :)
Nun wollen wir daraus ja ein SIRDS bauen, also installieren wir
erstmal die Software stereograph:
Und yeah, fertig ist unser erstes Stereogramm! \o/
Mit den Optionen von stereograph kann natuerlich noch rumgespielt
werden, bsp. kann durch ein angehaengtes -C -v das SIRDS mit
zufaelligen Farbpunkten erstellt werden (default: Grayscale) und es
werden alle Schritte ausgegeben (Verbose mode).
SIS
Ein Single Image Stereogram (SIS) ist ein Autostereogramm,
welches statt zufaelligen (Farb-)punkten Texturen/Muster oder sogar
Bilder verwendet. Die Bandbreite an Moeglichkeiten ist hier natuerlich
sehr gross. Eine gute Auswahl an Moeglichkeiten bieten die
Stereogramme von Gary W. Priester (der auch einige
Stereogrammbuecher kreiert hat), die mich sehr dazu inspiriert
haben, so viel mit den Moeglichkeiten, die ich habe, herumzuspielen.
Cool finde ich z.B. das Stereogramm mit den Muenzen, in dem das
Graustufenbild auf die Textur gemappt wurde, so dass es den Anschein
hat, als waeren die 3D-Objekte wirklich Muenzen.
Hier also Anleitungen, solch ein Muster mit stereograph zu
verwenden.
Muster in Gimp erstellen
Das ist recht einfach:
Die Groesse der Textur ist bei sich
wiederholenden Mustern erstmal egal, d.h. wir verwenden wieder die
Vorlage 640x480 (Strg+N fuer neues Bild). Der Rest der Einstellungen
kann bei den Standardwerten bleiben.
Dann waehlen wir das Fuellen-Tool aus (Umschalt+B), klicken bei
Fuellart auf Muster, waehlen ein Muster (wie z.B. Sky) aus und
klicken damit ins Bild.
Nun nur noch als textur.png abspeichern (Umschalt+Strg+E).
Fertig ist die Textur :)
Die Textur koennen wir nun zusammen mit dem Graustufenbild von oben
mit dem folgenden Befehl in ein Stereogramm verwandeln:
Die richtige Breite (-w 100) wird uebrigens in der Manpage von
stereograph (man 1 stereograph) gut erklaert:
As a hand rule, 100 should work nice for
stereograms of 640*480 up to 800*600 pixels. Use 110 to 120 for
bigger ones and higher screen resolutions (>=1280*960).
Muster mit ImageMagick erstellen
Damit nicht Gimp bemueht werden muss, um ein Muster bzw. eine Textur zu
erstellen, wollte ich ImageMagick nutzen, um solch ein zufaelliges
Muster in der Shell zu generieren (Quelle):
Allerdings stellte ich dabei schnell fest, dass das nicht wirklich
schoen ist (eher noch mehr Kopfweh verursachender) und daher z.B. diese
Methode zu bevorzugen ist (Quelle):
Es gibt auf der Seite noch ziemlich viele Moeglichkeiten, also
einfach mal damit herumspielen ;)
Veganblume als SIS mit Blender
Wie ein Graustufenbild bzw. eine Depth Map mit Blender erstellt werden
kann, war mir am Anfang ueberhaupt nicht
klar. Der erste Versuch war lediglich: Veganblume in Blender laden,
etwas drehen (Rotate oder R), Kamera verschieben (Translate oder
G und Umschalt+F) und rendern (F12). Und dann daraus ein
Stereogramm bauen. Allerdings ist das nicht der richtige Weg, wie sich
bei der weiteren Recherche herrausstellte. Das Geheimnis liegt in der
Tiefe ;)
Dabei habe ich zwei Wege gefunden, eine Depth Map zu erstellen. Einmal
mit Map Value und einmal mit ColorRamp.
Ich habe mich fuer die erste Variante entschieden, weil sie etwas
simpler zu erstellen ist.
Wenn euch die Textanleitung hier zu kompliziert erscheint, guckt euch
auf jeden Fall die Video-Anleitung an! Ich wollte es nur
zusaetzlich noch in Textform haben, falls das Video irgendwann mal
nicht mehr da ist.
Um die Veganblume gut verschieben/bewegen zu koennen, aendern wir
noch die Mitte des Objekts: mit einem Linksklick ca. auf die Mitte
der Blume klicken und dann "Object" - "Transform" - "Origin to 3D
Cursor" auswaehlen.
Nun verschieben wir die Kamera, sodass sie frontal auf die
Veganblume "blickt" (mit Translate oder G und Umschalt+F um sie
zu positionieren). Wie das gerenderte Bild nachher von Sicht der
Kamera aus aussieht, kann mit Numpad 0 oder "View" - "Camera"
nachgeschaut werden.
Nun fehlt nur noch die Positionierung des Objekts, was wir ein
bisschen an zwei Achsen drehen (mit Rotate oder R).
Mit den Einstellungen zufrieden? Dann koennen wir nun die Depth Map
in Angriff nehmen ;) Dazu oben in Blender neben der Hilfe den
Screen "Composting" auswaehlen und in diesem Fenster "Use Nodes" und
"Backdrop" aktivieren.
Um dort ein Bild hinzubekommen, muessen wir erstmal die Szene
rendern (mit F12 oder "Render" - "Render Image") und einen "Viewer"
erstellen: Dazu im Node Editor (das obere, groessere Fenster) auf
"Add" - "Output" - "Viewer" klicken und die neue Node ablegen. Nun
nur noch den Ausgang "Image" bei der ersten Node (Render Layers) mit
der neuen Node (Eingang "Image") verbinden. Nun sollte im Hintergrund
das Renderergebnis zu sehen sein.
Nun erstellen wir die Depth Map. Dazu erstellen wir eine neue Node:
"Add" - "Vector" - "Map Value". Nun muessen wir noch die Nodes
richtig verbinden: Bei "Render Layers" sollte der "Z"-Ausgang zu
"Value"-Eingang bei "Map Value" gehen und der "Image"-Ausgang zum
"Image"-Eingang bei "Composite" sowie der "Value"-Ausgang bei "Map
Value" zum "Image"-Eingang von "Viewer" gehen.
Der Backdrop sollte nun einfach nur weiss sein. Bevor wir aber mit
den Werten von "Map Value" herumspielen, invertieren wir noch das
Bild: "Add" - "Color" - "Invert" und verbinden den "Value"-Ausgang
von "Map Value" mit dem "Color"-Eingang von "Invert" und den
"Color"-Ausgang von "Invert" mit dem "Image"-Eingang von "Viewer".
Nun nur noch mit den Werten von "Map Value" herumspielen und wir
sind fast fertig. Halbwegs zufrieden war ich mit "-3.600" bei
"Offset" und "0.400" bei "Size".
Damit nun auch das gerenderte Bild so aussieht wie der Backdrop,
muessen wir noch den "Color"-Ausgang von "Invert" mit dem
"Image"-Eingang von "Composite" verbinden.
Um ein detailreiches Bild zu erhalten, waehlen wir bei dem rechten
"Properties"-Fenster unter "Render" als "Resolution" bei X "1920px",
bei Y "1080px" und darunter "100%" aus und klicken auf "Render" bzw.
F12.
Zuletzt waehlen wir noch linksunten im "UV/Image Editor"-Fenster
"Image" - "Save as Image" oder F3 aus und speichern das Bild als
veganblume.png ab.
Um sich die ganze Anleitung oben zu sparen, koennt ihr euch hier auch
einfach meine fertige Blend-Datei runterladen.
Um eine Depth Map zu erzeugen, einfach auf "Render" klicken oder F12
druecken.
So, fast fertig, es fehlt nur noch das Stereogramm. Das erstellen wir
als SIS (das SIRDS spar ich mir jetzt) mit der Textur textur.png von
oben:
Die Schritte nach dem oeffnen, um eine Animation zu erstellen:
In Blender oben neben der Hilfe den Screen wieder auf "Default"
setzen und Numpad 0 oder "View" - "Camera" auswaehlen.
Nun zentrieren wir die Veganblume wieder auf allen Achsen, sodass
die Kamera auf ein gerade gerichtetes Objekt blickt. Dazu mit
"Rotate" oder R mit den Views "Front", "Right" und "Top" (oder
Numpad 1/Numpad 3/Numpad 7) das Objekt gerade ausrichten.
Da unsere Animation nur eine Sekunde bzw. 24 Frames lang sein soll,
stellen wir unten in der Timeline "End" auf 24.
Nun setzen wir den ersten Keyframe, indem wir i druecken und in
dem Menue "Rotation" auswaehlen. D.h. die Aufnahme beginnt nun in
Frame 0 und beachtet nur die Rotation des Objekts.
Die Veganblume soll sich in diesem Beispiel einfach nur um die
Z-Achse drehen, d.h. wir waehlen den naechsten Frame aus (12) und
drehen die Veganblume um 180 Grad und druecken dazu nacheinander:
r, z, 180, Enter. Und setzen wieder einen Keyframe: i und dann
"Rotation".
Um zu verhindern, dass sich die Veganblume einfach in die gleiche
Richtung zurueckdreht, setzen wir noch einen Keyframe bei Frame 18.
Also: Frame 18 auswaehlen, Objekt um 90 Grad drehen (r, z, 90,
Enter) und Keyframe setzen (i, "Rotation").
Zu guter Letzt setzen drehen wir wieder bei Frame 24 die Veganblume
wieder um 90 Grad und setzen einen Keyframe. Fertig ist die
Animation :)
Nun werdet ihr beim Starten der Animation feststellen, dass das Objekt
sich nicht wirklich in der Mitte befindet, aber das ist mir im Moment
egal ;)
Dank schon vorhandenem "Map Value"-Kram im "Composting"-Screen,
koennen wir die Szene nun einfach als Animation rendern. Dazu
Ctrl+F12 druecken oder "Render" - "Render Animation" auswaehlen.
Die finale Blend-Datei koennt ihr wieder (wenn ihr die
Anleitung nicht befolgen wollt) hier herunterladen.
Nach einiger Zeit sollten nun 24 Bilder (0001.png - 0024.png) in
/tmp vorhanden sein, die nun an einen besseren Ort verschoben werden
koennen.
Nun muessen wir nur noch jedes einzelne Bild in ein Stereogramm
umwandeln. Das geht z.B. mit folgendem Befehl:
$ for i in 00*.png ; do echo $i ; stereograph -b $i -t textur.png -w 120 -f png -o "s$i" ; done
Um nicht einfach nur die Bilder mit einem Bildprogramm durchgehen zu
muessen, erstellen wir nun aus den Einzelbildern ein Gif und
zusaetzlich noch ein Webm.
Am Besten ist eine kleine Anzahl an Bildern (so wie in diesem
Beispiel), da der folgende Befehl mit vielen Bildern lange dauert,
viel CPU-Last erzeugt und den Ram/Swap ausreizt.
Mit diesem Befehl koennen wir aber relativ einfach ein Gif erzeugen,
was sich immer wieder wiederholt und pro Bild quasi 100 ms "wartet"
(Quelle):
$ convert $(for a in s00*.png ; do printf -- "-delay 10 %s " $a ; done) -loop 0 veganblume.gif
Achtung: das Ergebnis kann recht gross sein, vor allem, wenn die
Ausgangsbilder schon eine grosse Aufloesung haben. Bei mir ist das Gif
nun 29 MB gross ...
Und im Uebrigen ist das ganze hin und her (also 3D-Szene aus
Blender als 2D-Bilder umwandeln und dann per optischer Taeuschung
wieder in 3D) etwas unnoetig, aber warum einfach, wenn es auch
kompliziert geht? ;)
So, und weil es cool ist und Webm schon so ein bisschen Zukunft
ist, wandeln wir nun die Bilder auch noch in eine webm-Datei um
(Quelle):
Erst installieren wir zwei dafuer benoetigte Pakete:
# pacman -S mjpegtools libvpx
Dann wandeln wir die Einzelbilder in ein "YUV4MPEG" um:
In einer anderen Quelle habe ich noch einen Befehl gefunden, um die
Bilder in eine AVI-Datei umzuwandeln, aber das spare ich mir nun.
Noch eine Idee ...
... war, mit Hilfe der Stereogramme ein Spiel zu bauen :)
Und zwar ein moeglichst einfaches Spiel, wobei jedes einzelne Bild in
ein Stereogramm umgewandelt und ausgegeben wird.
So entsteht aus einem 2D-Game ein 3D-Game, welches aber wahrscheinlich
Kopfschmerzen erzeugt ;)
Aber natuerlich gibt bzw. gab es sowas schon: Magic Carpet
(Quelle, letzter Absatz) ;)
Ich wollte das natuerlich ausprobieren, und habe es zwar zum Laufen
bekommen, konnte aber leider nicht den SIRDS-Modus ausprobieren.
Nichtsdestotrotz hier aber ein kleiner Exkurs, wie ein so
altes Spiel zum Laufen gebracht werden kann.
Exkurs: DOSBox
Zuerst muessen ein paar Pakete installiert werden:
Nachdem uns CD Projekt Red mit einer Linux Version des 2011 erschienenen Spieles The Witcher 2 beschert hat wird für den dritten Teil nun gleich eine Version für Linux mit-angekündigt.
Dass Spiel wird voraussichtlich am 24.5.2015 erscheinen jedoch kann auf Steam bereits vorbestellt
werden.
The Witcher 3: Wild Hunt kostet aktuell in der Vorbestellung 46.99 Euro und wird bei Veröffentlichung voraussichtlich 59.99 Euro kosten.
Wild Hunt spielt im Imperium von Nilfgaard in dem unter anderem Dörfer über Nacht zerstört werden sollen.
Die bereits bekannten Informationen zu der Geschichte rund um Gerald von Riva lesen sich nicht schlecht und klingen interessant.
Ich persönlich freue mich schon auf dass Spielen in einem hoffentlich Nativ laufendem Spiel.
Das nächste Jahr hat damit bereits einen ersten Höhepunkt für Spieler unter Linux bekommen.
Im Ubuntu-Repositorium bin ich auf das Kommandozeilen Programm „highlighting“ gestoßen. Gleich vorweg: Meine Bedürfnisse für Syntax-Highlighting erfüllt es vollkommen. Ich will damit vor allem längere Code-Passagen auf dieser Website lesbarer machen, weswegen die Ausgabe in diesem Artikel in HTML erfolgt. LaTex ist aber beispielsweise auch möglich.
Beispielanwendung
Nach der Installation aus dem Repositorium (denke das sollte jeder selbst hinbekommen), ist highlighting über die Kommandozeile zu bedienen. Ein Beispiel:
-f: kein Header oder Footer (Voraussetzung für beiden nachfolgenden Optionen)
--inline-css: bei HTML keine seperate CSS-Datei, sondern Formatierung „direkt an Ort und Stelle“
--enclose-pre: keine vollständige HTML-Datei mit body und header, sondern nur die <pre>-Tags
-S: „Sprache“ der Quelle festlegen; hier html
-i: Eingabedatei für Syntaxhighlighting
-o: Ausgabedatei
Ich nutze hier ausnahmsweise CSS inline, da ein generiertes externes CSS-Stylesheet nur die aktuell verwendeten Regeln auswirft. Eine Option, um ein komplettes Stylesheet für einen Stil ausgeben zu lassen, habe ich nicht gefunden. Damit wir der Hauptnutzen von externem CSS meiner Meinung nach ad absurdum geführt, nämlich das Caching. Denn wenn für jede neuen Codeblock ein eigenes Stylsheet geladen werden muss, kann man dies gleich inline schreiben. Das spart nur HTTP-Requests – die fehlende Trennung von Inhalt und Design ignoriere ich hier jetzt einmal.
Themes
Das Aussehen der Ausgabe kann man über vorgegeben Themes verändern.
$ highlight -w
Gibt eine Liste mit allen installierten Themes aus. Wie die einzelnen Themes aussehen, sieht man auf zwei (unvollständigen) Wiki-Seiten: Seite 1, Seite 2
Meine Favoriten sind die Stile „acid“, „bright“, und „zmrok“. Das Standardtheme ist aber auch nicht schlecht. Auf dieser Website werde ich in Zukunft wohl „zmrok“ verwenden.
Skript zum Ausprobieren
Da die Wikiseite wie oben geschrieben unvollständig ist, hab ich mir mal ein kleines Shell-Skript geschrieben. Dieses probiert anhand einiger Dateien im Ordner „org“ die unterschiedlichen Themes für verschiedenen Programmiersprachen aus. Dabei ist für jede Programmiersprache eine eigenen Beispieldatei im „org-Ordner“. Entsprechend der Dateiendung wird ein Ordner angelegt. Mit den ausgegeben HTML-Dateien ist dann ein Vergleichen der Themes relativ gut möglich.
Das Archiv enthält schon einen Durchlauf des Skripts unter Ubuntu 12.04. Möchte man es auf seinem eigenen Rechner ausführen, reicht ein einfaches
$ bash test_highlighting.sh
im selben Ordner. Wer möchte, kann davor alle Ordner außer „org“ löschen.
Beispiel: JS-Code, Theme „zmork“
Zum Abschluss noch ein Beispiel für das meiner Meinung nach schönste Theme „zmork“
1 functionfibonacci(n) { 2 var i =1, j =0, k, t; 3 for(k =1; k Math.abs(n); k++) { 4 t = i + j; 5 i = j; 6 j = t; 7 } 8 if(n 0&& n %2===0) j = -j; 9 return j; 10 }
Standardmäßig speichert nginx in seinen Access-Logs leider auch die IP-Adressen der Besucher, was rechtlich gesehen in Deutschland umstritten ist und was ich persönlich auch gar nicht möchte. Glücklicherweise kann man auch nginx relativ schnell beibringen, die Access-Logs ohne IP zu speichern. Dazu legt man sich ein eigenes Logging-Format fest, zum Beispiel in der Datei /etc/nginx/conf.d/logs.conf:
Das Format kann an dieser Stelle natürlich an die eigenen Wünsche angepasst werden. Ich habe mich am standardmäßigen Format orientiert.
Anschließend muss das neue Log-Format noch für den Access-Log definiert werden. Dafür im vHost in /etc/nginx/sites-available die access_log Zeile folgendermaßen erweitern:
Nach der Anpassung sehen die Access-Logs jetzt so aus:
[07/Jun/2014:16:05:13 +0200] "GET /2013/07/erfahrungen-mit-dem-google-play-support-1993/ HTTP/1.0" 200 33643 "http://www.tuxdroid.de/2013/07/erfahrungen-mit-dem-google-play-support-1993/#comment-28644" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.102 Safari/537.36"
Wer gar keine Access-Logs haben möchte, der kann diese natürlich ganz leicht deaktivieren. Einfach im entsprechenden vHost in /etc/nginx/sites-available die access_log Zeile in folgendes ändern:
access_log off;
Um das neue Log-Format zu nutzen muss nginx einmal neugestartet werden:
Im Ubuntu-Repositorium bin ich auf das Kommandozeilen Programm
„highlighting“
gestoßen. Gleich vorweg: Meine Bedürfnisse für Syntax-Highlighting
erfüllt es vollkommen. Ich will damit vor allem längere Code-Passagen
auf dieser Website lesbarer machen, weswegen die Ausgabe in diesem
Artikel in HTML erfolgt. LaTex ist aber beispielsweise auch möglich.
Beispielanwendung
Nach der Installation aus dem Repositorium (denke das sollte jeder
selbst hinbekommen), ist highlighting über die Kommandozeile zu
bedienen. Ein Beispiel:
-f: kein Header oder Footer (Voraussetzung für beiden nachfolgenden
Optionen)
--inline-css: bei HTML keine seperate CSS-Datei, sondern
Formatierung „direkt an Ort und Stelle“
--enclose-pre: keine vollständige HTML-Datei mit body und header,
sondern nur die <pre>-Tags
-S: „Sprache“ der Quelle festlegen; hier html
-i: Eingabedatei für Syntaxhighlighting
-o: Ausgabedatei
Ich nutze hier ausnahmsweise CSS inline, da ein generiertes externes
CSS-Stylesheet nur die aktuell verwendeten Regeln auswirft. Eine Option,
um ein komplettes Stylesheet für einen Stil ausgeben zu lassen, habe ich
nicht gefunden. Damit wir der Hauptnutzen von externem CSS meiner
Meinung nach ad absurdum geführt, nämlich das Caching. Denn wenn für
jede neuen Codeblock ein eigenes Stylsheet geladen werden muss, kann man
dies gleich inline schreiben. Das spart nur HTTP-Requests – die fehlende
Trennung von Inhalt und Design ignoriere ich hier jetzt einmal.
Themes
Das Aussehen der Ausgabe kann man über vorgegeben Themes verändern.
1
$ highlight -w
Gibt eine Liste mit allen installierten Themes aus. Wie die einzelnen
Themes aussehen, sieht man auf zwei (unvollständigen) Wiki-Seiten:
Seite
1,
Seite
2
Meine Favoriten sind die Stile „acid“, „bright“, und „zmrok“. Das
Standardtheme ist aber auch nicht schlecht. Auf dieser Website werde ich
in Zukunft wohl „zmrok“ verwenden.
Skript zum Ausprobieren
Da die Wikiseite wie oben geschrieben unvollständig ist, hab ich mir mal
ein kleines Shell-Skript geschrieben. Dieses probiert anhand einiger
Dateien im Ordner „org“ die unterschiedlichen Themes für verschiedenen
Programmiersprachen aus. Dabei ist für jede Programmiersprache eine
eigenen Beispieldatei im „org-Ordner“. Entsprechend der Dateiendung wird
ein Ordner angelegt. Mit den ausgegeben HTML-Dateien ist dann ein
Vergleichen der Themes relativ gut möglich.
Das Archiv enthält
schon einen Durchlauf des Skripts unter Ubuntu 12.04. Möchte man es auf
seinem eigenen Rechner ausführen, reicht ein einfaches
1
$ bash test_highlighting.sh
im selben Ordner. Wer möchte, kann davor alle Ordner außer „org“
löschen.
Beispiel: JS-Code, Theme „zmork“
Zum Abschluss noch ein Beispiel für das meiner Meinung nach schönste
Theme „zmork“
(Als Screenshot, da ich mittlerweile auf pygments setze)
Standardmäßig speichert nginx in seinen Access-Logs leider auch die IP-Adressen der Besucher, was rechtlich gesehen in Deutschland umstritten ist und was ich persönlich auch gar nicht möchte. Glücklicherweise kann man auch nginx relativ schnell beibringen, die Access-Logs ohne IP zu speichern. Dazu legt man sich ein eigenes Logging-Format fest, zum Beispiel in der Datei /etc/nginx/conf.d/logs.conf:
Das Format kann an dieser Stelle natürlich an die eigenen Wünsche angepasst werden. Ich habe mich am standardmäßigen Format orientiert.
Anschließend muss das neue Log-Format noch für den Access-Log definiert werden. Dafür im vHost in /etc/nginx/sites-available die access_log Zeile folgendermaßen erweitern:
Nach der Anpassung sehen die Access-Logs jetzt so aus:
[07/Jun/2014:16:05:13 +0200] "GET /2013/07/erfahrungen-mit-dem-google-play-support-1993/ HTTP/1.0" 200 33643 "http://www.tuxdroid.de/2013/07/erfahrungen-mit-dem-google-play-support-1993/#comment-28644" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.102 Safari/537.36"
Wer gar keine Access-Logs haben möchte, der kann diese natürlich ganz leicht deaktivieren. Einfach im entsprechenden vHost in /etc/nginx/sites-available die access_log Zeile in folgendes ändern:
access_log off;
Um das neue Log-Format zu nutzen muss nginx einmal neugestartet werden:
Warum automatische Revisionen sinnvoll sein können habe ich gerade wiedereinmal erfahren müssen.
Beim schreiben eines Artikels für meinen Blog hat sich dass Programm Abiword aufgehängt.
Ich hatte kurz zuvor die Daten per Tastatureingabe kopiert, da es Text ist sollte der Programmabsturz kein Problem sein.
Nachdem ich nun Abiword nochmal öffnete und die Datei mit dem zuvor kopiertem überschrieben hatte stellte fest dass nur die ältere Version aus dem Zwischenspeicher kopiert worden ist.
Dass ist nicht dass erste mal dass durch einen Fehler in Abiword komplett oder teilweise Artikel verloren gehen.
Ich bin also derzeit auf der suche nach einem Schreibprogramm welches Revisionen automatisch anlegt.
Es sollte in den Standartquellen der meisten Betriebssysteme und am besten Open Source sein.
Dazu bräuchte ich eine Rechtschreibprüfung wie hunspell.
Wer eine Idee dazu hat kann sich gerne bei mir melden.
MPD(engl. für »Music Player Daemon«) ist ein Freier Musikserver für Linux bzw. Unix-Artige Systeme, der unter anderem erlaubt, innerhalb des Netzwerks Playlists zu erstellen, die Musikdateien zu »Taggen«, danach zu suchen, usw.. Einen Musikplayer hierfür, den ncmpcpp, habe ich hier schon vorgestellt.
Hier soll es erst mal um die Standardkonfiguration gehen, sprich Adresse innerhalb des Netzwerks, Ports, Standardverzeichnisse und den entsprechenden User.
MPDs Standardverzeichnisse sind wie folgt(in Debian-Artigen Systemen):
Konfiguration: /etc/mpd.conf
Basisverzeichnis: /var/lib/mpd/
Musik: /var/lib/mpd/music
Playlists: /var/lib/mpd/playlists
Tag Cache: /var/lib/mpd/tag_cache
„Standards“: /var/lib/mpd/state (Hier wird eine Playlist angelegt, die Standardmäßig genutzt werden kann.)
Konfigurieren der Adresse
Der MPD ist normalerweise unter localhost:6600 erreichbar. Dies kann nützlich sein, wenn man ihn nur Lokal nutzen möchte, hindert aber gerne aussenstehende Rechner daran, eine Verbindung aufzubauen(Kommt auf die genutzte Firewall an..). Wenn man den MPD also im ganzen Netzwerk erreichen möchte, sollte man ihm eine Statische IP zuweisen, welche er belegen kann.
Dies wird in der Konfigurationsdatei, /etc/mpd.conf, niedergeschrieben. Ich habe hier Lokal den Adressbereich 10.0.0. reserviert, und nutze deshalb die Adresse 10.0.0.3:
bind_to_address "10.0.0.3"
port "6600"
Der Unix-Socket für den MPD wird folgendermaßen niedergelegt:
bind_to_address "/var/run/mpd/socket"
Wenn wir jetzt also den MPD neustarten, welches wir über „service mpd restart“, oder optional, /etc/init.d/mpd restart, tun können.
Jetzt ist der Daemon schonmal erreichbar. Permalink
Neue Webseiten werden heutzutage oft via SASS erstellt, aber was macht man mit alten Projekten? Kann man auch hier SASS einsetzten? – Ja! Das schöne an “SCSS”-Dateien ist das diese 100% mit CSS kompatibel sind, so dass man die entsprechende Dateiendung umbenennen kann und neue / kleine Anpassungen in der SASS-Syntax schreiben kann. Wer jedoch eine ganze CSS-Datei auf den SCSS-Style anpassen möchte kann z.B. den “sass-convert”-Befehl auf der Kommandozeile verwenden.
Es folgt eine kleine manuelle Optimierung, dabei gilt: Umso besser die ursprüngliche CSS-Datei aufgebaut war, desto besser kann diese konvertiert werden.
Gerade hatte ich mein WordPress-Plugin zur Anonymisierung von IP-Adressen zu WordPress-Kommentaren fertiggestellt, da ist mir aufgefallen, dass es entgegen meines bisherigen Kenntnisstands doch schon ein solches Plugin gibt:
Es arbeitet genauso wie meine Version und ist unter einer freien Lizenz veröffentlicht. Sobald ein Kommentar von WordPress verarbeitet wird, wird die echte IP-Adresse des Kommentar-Autors durch „127.0.0.1″ ersetzt. Das Anonymisieren der IP-Adresse ist in Deutschland übrigens Pflicht nach geltendem Datenschutzrecht (sofern es keinen „bedeutenden Grund” dafür gibt) – Das Plugin dürfte eigentlich auf keinem Blog fehlen!
Nach deutschem Recht dürfen Webserver keine IP-Adressen abspeichern – Es sei denn, es ist z.B. aus geschäftlichen oder technischen Gründen zwingend notwendig. (=> TMG §15)
Das gilt sowohl für die Kommentarfunktion z.B. in WordPress als auch für die Logfiles, die von Apache angelegt werden. Die meisten Apachen sind leider falsch eingestellt und werden den Datenschutzgesetzen damit nicht gerecht. Mit ein paar Zeilen Konfiguration kann man die Logfiles seines Webservers aber anonymisieren oder sogar ganz abschalten.
Logfiles anonymisieren
Eine Möglichkeit ist das anonymisieren von Logfiles. Dabei werden weiterhin Einträge in die Dateien geschrieben – doch mit entfernter IP-Adresse. Unter Ubuntu 14.04 wechselt man in das Konfiguraionsverzeichnis /etc/apache2/conf-available/ und öffnet die Datei „other-vhosts-access-log.conf„, um die Logeinstellungen für vHosts zu ändern. Eine neue Zeile wird hinzugefügt:
Wer ganz auf den Accesslog verzichten kann, kann diesen auch ausschalten und Ressourcen sparen. Dazu wird in /etc/apache2/conf-available/other-vhosts-access-log.conf einfach die Zeile „CustomLog …” mit einem vorangestellten „#”-Zeichen auskommentiert. Dasselbe gilt für den Errorlog: Hier muss in /etc/apache/apache2.conf die Einstellung „ErrorLog” auskommentiert werden.
Wie immer nach einer Konfigurationsänderung ist ein Neuladen der Konfigurationsdateien nötig, damit die neuen Einstellungen aktiv werden:
Irgendwie bin ich openSUSE ja verfallen, denn alles funktioniert, wie ich es mir wünsche. Wenn es doch mal etwas hakt, dann knuspere ich etwas, bis alles (wieder) funktioniert.
Eines jedoch ärgert mich immer wieder: Die Programm-Verwaltung.
Zwar habe ich mich nun schon daran gewöhnt, dass ich für neue Programme / Aufgaben immer wieder eine Suchmaschine befrage, jedoch ist es diese Notwendigkeit, welche mich stört. Das erinnert mich an Windows-Zeiten, zu welchen ich auf ähnliche Suchspiele angewiesen war.
Nun mag man einwerfen, dass es ja Seiten wie die folgenden gibt, jedoch sind diese entweder vollkommen unübersichtlich (viele Pakete für die selbe Software) oder für alle möglichen Distributionen und Desktops ausgelegt.
Hier denke ich mit etwas Wehmut an Ubuntu zurück, welches eine schön aufgeräumte Programmverwaltung nebst Bewertung enthielt. Quelle: http://de.wikipedia.org/wiki/Ubuntu
Ein Klick zum Installieren, ein weiterer zum entfernen, wenn es doch nicht gefällt.
Unter openSUSE benutze ich nach wie vor das Terminal mit dem Befehl sudo zypper install – oder – sudo zypper remove -u
Die Paketverwaltung unter Yast ist mir einfach zu unübersichtlich und überladen. Wenigstens sind Kategorien dazu gekommen Permalink
Irgendwie bin ich openSUSE ja verfallen, denn alles funktioniert, wie ich es mir wünsche. Wenn es doch mal etwas hakt, dann knuspere ich etwas, bis alles (wieder) funktioniert.
Eines jedoch ärgert mich immer wieder: Die Programm-Verwaltung.
Zwar habe ich mich nun schon daran gewöhnt, dass ich für neue Programme / Aufgaben immer wieder eine Suchmaschine befrage, jedoch ist es diese Notwendigkeit, welche mich stört. Das erinnert mich an Windows-Zeiten, zu welchen ich auf ähnliche Suchspiele angewiesen war.
Nun mag man einwerfen, dass es ja Seiten wie die folgenden gibt, jedoch sind diese entweder vollkommen unübersichtlich (viele Pakete für die selbe Software) oder für alle möglichen Distributionen und Desktops ausgelegt.
Hier denke ich mit etwas Wehmut an Ubuntu zurück, welches eine schön aufgeräumte Programmverwaltung nebst Bewertung enthielt. Quelle: http://de.wikipedia.org/wiki/Ubuntu
Ein Klick zum Installieren, ein weiterer zum entfernen, wenn es doch nicht gefällt.
Unter openSUSE benutze ich nach wie vor das Terminal mit dem Befehl sudo zypper install – oder – sudo zypper remove -u
Die Paketverwaltung unter Yast ist mir einfach zu unübersichtlich und überladen. Wenigstens sind Kategorien dazu gekommen
Es gab 2011 mit Bretzn einen Versuch, eine schöne Software-Verwaltung zu erstellen, aber das Projekt ist wohl im Sand verlaufen.
Die 1-Klick Lösung von software.opensuse.org ist ein guter Anfang, aber es fehlt einfach eine Webseite mit Filterfunktion für die Distribution, Bewertungen, Screenshots und Kommentar-Funktion… oder ich habe sie schlicht noch nicht gefunden und meine Software-Suche mache ich mir unnötig schwer (für Tipps in den Kommentaren bin ich dankbar)