Historisches
OpenOffice.org war eine quelloffene Bürosoftware, welche im Jahr 2000 aus dem Quellcode des kommerziellen Office-Programms StarOffice hervorgegangen ist. Teil von OpenOffice.org waren die Anwendungen Writer (Textverarbeitung), Calc (Tabellenkalkulation), Impress (Präsentationen), Draw (Zeichnen), Base (Datenbanken) sowie Math (Formel-Editor).
Im September 2010 haben zahlreiche Entwickler der Office-Suite OpenOffice.org dem Projekt – wegen Meinungsverschiedenheiten mit der Firma Oracle – den Rücken gekehrt und das LibreOffice-Projekt gegründet, welches von der Stiftung The Document Foundation getragen wird. Grundlage für LibreOffice war der Quellcode von OpenOffice.org.
Daraufhin hat sich Oracle im Juni 2011 komplett aus dem OpenOffice.org-Projekt zurückgezogen und die Entwicklung sowie die Markenrechte von OpenOffice.org in die Hände der Apache Software Foundation gelegt, welche das Office-Paket von OpenOffice.org in Apache OpenOffice umbenannte.
Co-Existenz zwischen Apache OpenOffice und LibreOffice
Seitdem (Stand: Juni 2014) herrscht eine Co-Existenz zwischen den beiden kostenlosen Office-Programmen, was vor allem bei EDV-Laien nach wie vor zu Verwirrungen führt.
Nachdem OpenOffice.org jahrelang zur Standardinstallation der meisten Linux-Distributionen gehörte, wird heutzutage LibreOffice vorinstalliert. Bei den meisten Distributionen ist OpenOffice gar nicht mehr in den offiziellen Repositories vorhanden und somit im Linux-Umfeld fast schon etwas von der Bildfläche verschwunden.


Apache OpenOffice: Totgesagte leben länger
Obwohl die Entwicklung bei LibreOffice (kurz LibO) – aufgrund der vielen Entwickler – sehr zügig vorangeht, sollte man Apache OpenOffice (kurz AOO) keineswegs abschreiben. Erst kürzlich wurde wieder eine neue, verbesserte OpenOffice-Version veröffentlicht.
Ausserdem erfreut sich OpenOffice unter Windows-Anwendern immer noch grosser Beliebtheit, da die Marke OpenOffice traditionell für eine kostenlose aber ebenbürtige MS-Office-Alternative steht. Des Weiteren dürfen die Entwickler der Apache Software Foundation bei der Entwicklung von Apache OpenOffice auf die Unterstützung des IT-Giganten IBM zählen.
IBM hat in Version 4.0 von OpenOffice beispielsweise eine Seitenleiste integriert, mit welcher man Zugriff auf die wichtigsten Funktionen der Textverarbeitung, der Tabellenkalkulation sowie des Zeichenprogramms erhält.
Zum Entwicklerteam von LibreOffice gehören nicht nur ehemalige OpenOffice.org-Entwickler, sondern auch zahlreiche bekannte Unternehmen aus dem Open-Source-Umfeld wie z.B. Red Hat, Univention, SUSE und Google. Auch Canonical, die Firma hinter dem beliebten Linux-Betriebssystem Ubuntu, zählt zu den Unterstützern von LibreOffice.
Kompatibilität zwischen Apache OpenOffice, LibreOffice und MS-Office
Wie schon OpenOffice.org verwenden auch Apache OpenOffice und LibreOffice das OpenDocument-Format (kurz: ODF) als Standard-Dateiformat. Dieses entspricht der internationalen ISO-Norm ISO/IEC 26300.
Mit diesem Dokumenten-Standard bleibt gewährleistet, dass ODF-Dateien mit beiden freien Officepaketen erstellt, gelesen und verändert werden können, egal ob diese ursprünglich mit Apache OpenOffice oder mit LibreOffice erstellt wurden.
Im Hinblick auf die verbreiteten Microsoft-Formate (doc, docx, xls, xlsx, ppt, pptx, usw.) sind beide Open-Source-Projekte bestrebt, eine gute Kompatibilität zu gewährleisten. Mit jedem grösseren Update wird die Darstellung dieser Formate wieder ein Stück verbessert.
Zu erwähnen ist, dass es für die Entwickler von Apache und The Document Foundation schwierig ist, eine 100 %ige Kompatibilität mit MS-Formaten zu gewährleisten, da Microsoft die Spezifikationen seiner eigenen Formate absichtlich nicht vollständig der Öffentlichkeit freigibt, um seine Monopolstellung im Software-Bereich zu bewahren. Diese traurige Tatsache hindert viele Unternehmen daran, auf freie Software umzusteigen.
Aussehen
Die Optik von Apache OpenOffice und LibreOffice ähnelt visuell sehr der 2003er-Version von MS-Office. Aber auch Umsteiger anderer MS-Office-Versionen dürften sich mit ein bisschen Lernbereitschaft mit den freien MS-Office-Alternativen rasch zurechtfinden.
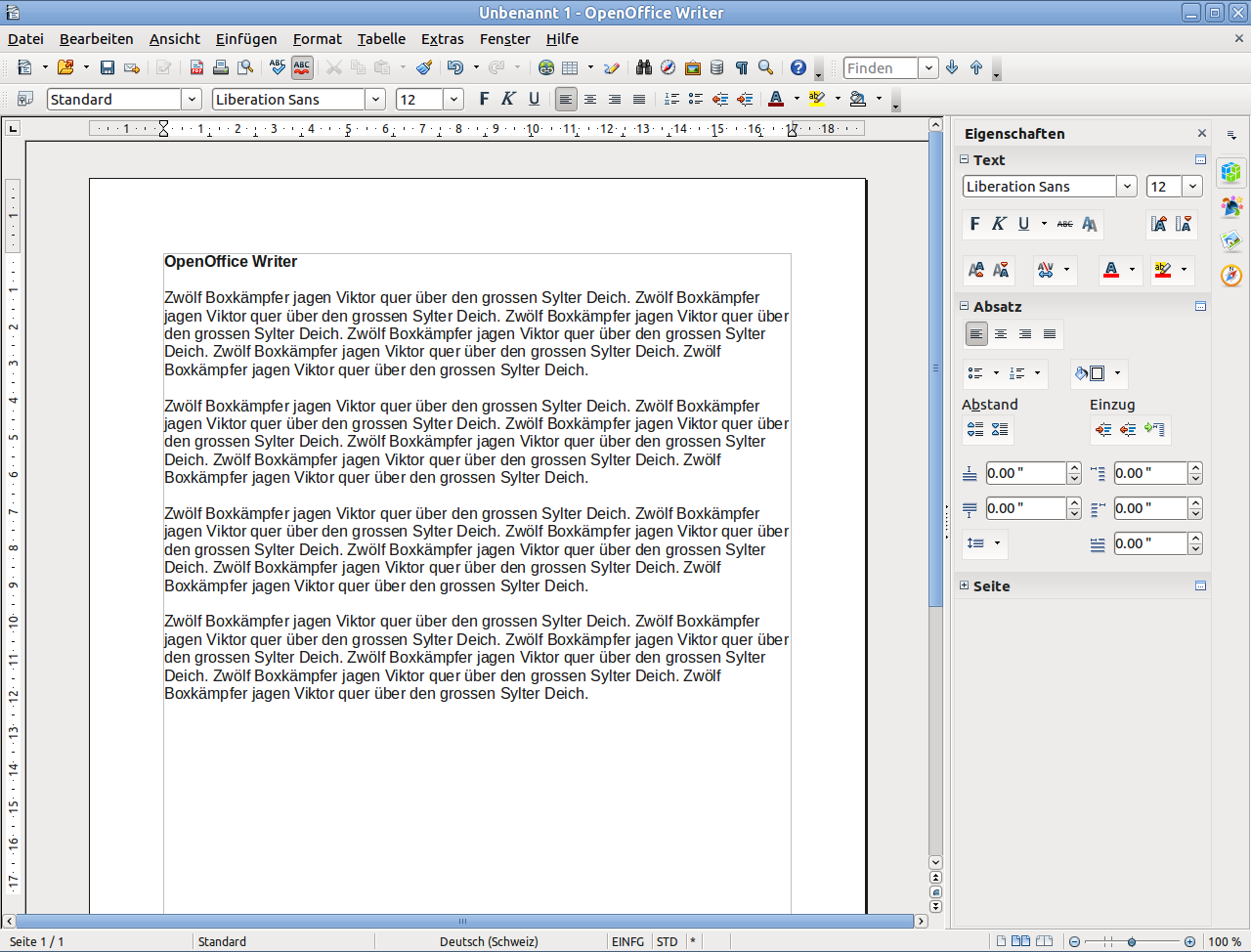
Screenshots der Linux-Version von Apache OpenOffice 4.1 (zum Vergrössern anklicken)

Screenshots der Linux-Version von LibreOffice 4.1 (zum Vergrössern anklicken)
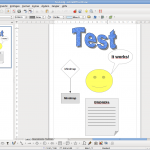
Die Namen der einzelnen Programmmodule sind bei Apache OpenOffice und LibreOffice dieselben geblieben; doch unterscheiden sich die Programmsymbole der beiden Office-Suiten weitgehend voneinander.

Auffällig ist, dass Apache für OpenOffice dieselben Programmicons verwendet, wie das „Vorgänger“-Projekt OpenOffice.org. The Document Foundation hat die Icons von LibreOffice stattdessen ganz dem Logo der eigenen Stiftung angepasst.
Kosten / Lizenz
Für den normalen Endanwender dürfte die Lizenz des Quellcodes der beiden Office-Suiten keine grosse Rolle spielen. Schliesslich ist die Benutzung von Apache OpenOffice und LibreOffice für die meisten Menschen eine Kostenfrage. Beide Office-Pakete sind und bleiben der Öffentlichkeit weiterhin sowohl in Binärform für GNU/Linux, Windows und Mac OS X als auch im Quelltext kostenlos zugänglich.
Anders sieht es bei Software-Entwicklern aus. Apache OpenOffice und LibreOffice stehen beide unter zwei verschiedenen freien Software-Lizenzen. Während Apache das OpenOffice-Projekt unter die hauseigene Apache-Lizenz v2.0 stellte, hat The Document Foundation das LibreOffice-Projekt dreifachlizensiert. LibreOffice steht nicht nur unter der General Public License v3+ (GPL), sondern auch wahlweise unter der Lesser General Public License v3+ (LGPL) und der Mozilla Public License v2.0.
Die Apache Lizenz v2.0 ist mit der (Lesser) General Public License v3 kompatibel, andersrum aber nicht. Als Folge daraus können Änderungen am Quellcode von Apache OpenOffice vom LibreOffice-Team in dessen Sourcecode übernommen werden, umgekehrt jedoch nicht.
Dies ist ein entscheidender Nachteil von Apache OpenOffice in Sachen Lizenzierung. LibreOffice kann sich sozusagen „legal“ am Code von OpenOffice bedienen, da dies die liberale Apache Lizenz zulässt.
Die von der Firma IBM in Apache OpenOffice 4.0 integrierte – oben erwähnte – Seitenleiste konnte von den LibreOffice-Entwicklern aufgrund dessen in LibreOffice 4.2 eingefügt werden. Die Seitenleiste ist in LibreOffice übrigens zwar standardmässig deaktiviert, kann aber im Menüpunkt Ansicht -> Seitenleiste dauerhaft aktiviert werden.
Apache OpenOffice Writer 4.1 unter Ubuntu Linux mit Seitenleiste (siehe rechts vom Bild)
Fazit
Für Otto-Normal-Benutzer spielt es grundsätzlich keine Rolle, ob man sich für Apache OpenOffice oder LibreOffice entscheidet. Beide MS-Office-Alternativen sind kostenlos für alle verbreiteten Betriebssysteme herunterladbar. Bei der Entwicklung von Apache OpenOffice legen die Entwickler hohen Wert auf Stabilität und Zuverlässigkeit. Bei LibreOffice liegt der Fokus bei der Entwicklung vor allem auf der Integration neuer Funktionen und Verbesserungen. Dies ist zumindest mein persönlicher Eindruck.
Tipp für ältere, leistungsschwache Computer
Sowohl Apache OpenOffice als auch LibreOffice eignen sich problemlos auch für ältere Computer – sofern genügend CPU-Leistung und Arbeitsspeicher vorhanden ist. Wer jedoch zuhause einen – aus heutiger Sicht – leistungsschwachen PC stehen hat und für diesen ein leichtgewichtiges Schreibprogramm sowie eine ressourcensparende Tabellenkalkulation sucht, findet vielleicht auch in Abiword und Gnumeric eine Alternative. Beide sind ebenfalls Open-Source und kostenlos.