Das High Efficiency Image File Format (HEIF) ist ein relativ neues Dateiformat für Bilder und Bildsequenzen. Es ist durch die Moving Picture Experts Group (MPEG) standardisiert und wird seit 2017 vor allem von Apple eingesetzt. Die resultierenden *.heif– bzw. *.heic-Dateien ermöglichen bei gleicher Bildqualität kleinere Dateigrößen. Die Kennung *.heic weist auf die Kombination von HEIF mit dem Video-Codec Efficiency Video Coding (HEVC) hin.
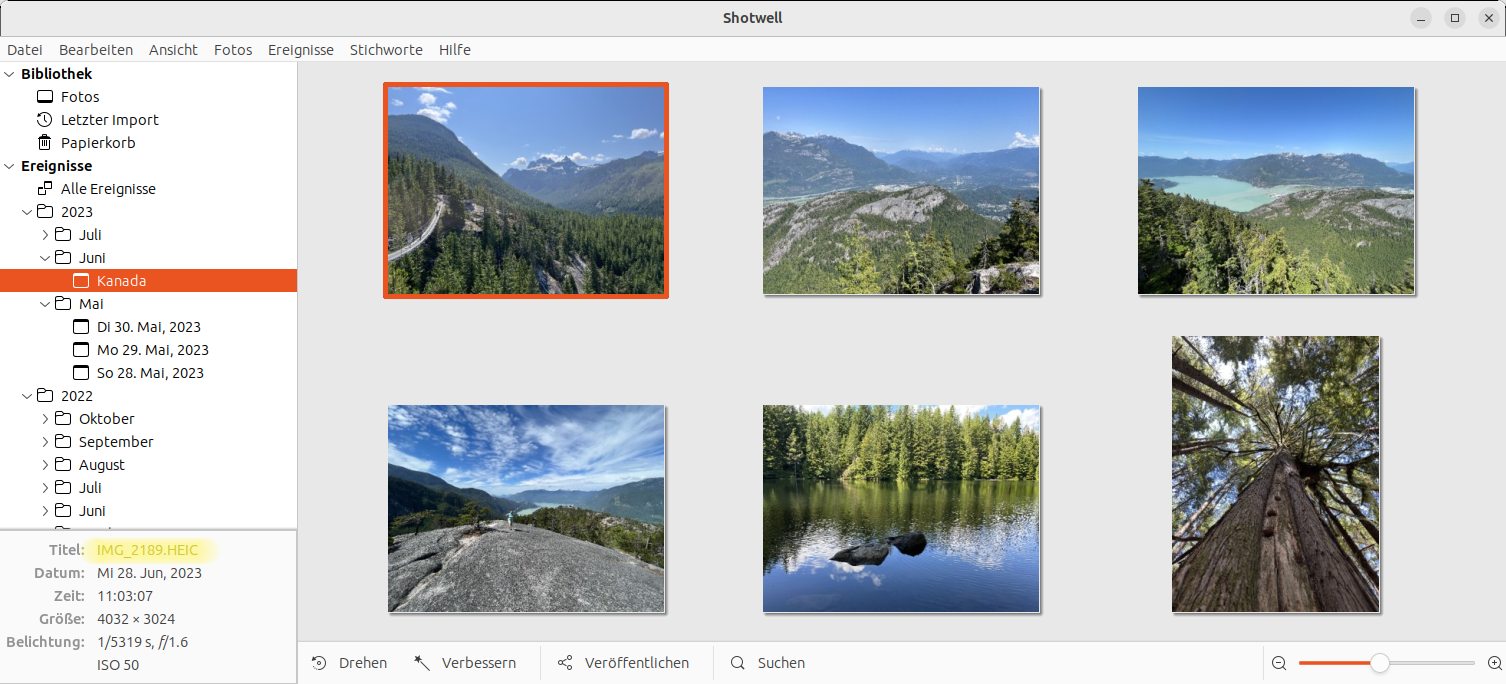
Kürzlich wollte ich ein paar mit dem iPhone aufgenommene Bilder unter Linux mit Shotwell verarbeiten. Dabei bin ich, leider beinahe erwartungsgemäß, auf Probleme gestoßen. Einige ließen sich lösen, aber nicht alle.
Ubuntu
Es beginnt damit, dass das weit verbreitete Foto-Management-Programm Shotwell erst seit April 2023 (Version 0.32) kompatibel mit dem HEIF-Format ist. Ubuntu bis einschließlich Version 23.04 liefert Shotwell aber in der Version 0.30 aus.
Um Version 0.32 zu installieren, müssen Sie zuerst ein Private Package Archive (PPA) aktivieren. Außerdem müssen
Sie die Bibliotheken libheif1 und heif-gdk-pixbuf installieren. (Diese Pakete gelten nicht als Abhängigkeiten und werden daher nicht automatisch installiert.)
sudo add-apt-repository ppa:ubuntuhandbook1/shotwell
sudo apt update
sudo apt install shotwell libheif1 heif-gdk-pixbuf
Sind diese Hürden einmal überwunden, funktioniert der Import von HEIC-Dateien in Shotwell problemlos, wenn auch sehr langsam.
Fedora
Unter Fedora 38 sieht die Lage nicht viel besser aus. Shotwell steht zwar in der aktuellen Version 0.32 wahlweise als Flatpak- oder als RPM-Paket zur Verfügung, scheitert aber in beiden Varianten beim Import von HEIC-Dateien. Schuld sind wiederum fehlende Bibliotheken.
Bei der Flatpak-Variante lässt sich dieses Problem aktuell nicht lösen, weil Shotwell die Bibliotheken aus Framework-Flatpaks liest, auf die Sie als Anwender keinen Einfluss haben. (Habe ich schon einmal erwähnt, dass ich weder von Snaps noch von Flatpaks viel halte?)
Die RPM-Version von Shotwell wird HEIF-kompatibel, wenn Sie die Paketquellen RPM Fusion Free und Nonfree aktivieren (siehe https://rpmfusion.org/Configuration) und das dort enthaltene Paket libheif-freeworld installieren:
sudo flatpak remove shotwell
sudo dnf install shotwell libheif-freeworld
Unter Fedora scheiterte Shotwell jetzt aber am Auslesen der EXIF-Daten. Damit fehlen Informationen, wann die Fotos aufgenommen wurden. Eine Lösung zu diesem Problem habe ich nicht gefunden. Die Sache ist ein wenig unbegreiflich, weil der Import unter Ubuntu mit EXIF-Daten funktioniert.
Nautilus und Gimp
Nicht nur Shotwell zickt, wenn es auf HEIC-Dateien stößt, ähnliche Probleme haben auch Gimp, Nautilus und Co. Bei Gimp besteht die Lösung darin, das Paket gimp-heif-plugin zu installieren.
Nautilus unter Debian/Ubuntu setzt den heif-thumbnailer voraus, der aber ebenfalls nicht automatisch installiert wird. Unter Fedora müssen Sie stattdessen die libheif-tools installieren.
heic-convert
Eine Notlösung besteht darin, HEIC-Dateien vorweg in das JPEG-Dateien umzuwandeln. Dabei hilft das Kommando heif-convert aus dem Paket libheif-tools (Fedora) bzw. libheif-examples (Ubuntu). Das folgende Kommando durchläuft alle *.HEIC-Dateien im aktuellen Verzeichnis und erzeugt JPEG-Dateien in hoher Qualität. Die resultierenden Dateien sind leider wesentlich größer als die HEIC-Originale.
for f in *.HEIC; do heif-convert -q 95 --with-exif $f $f.jpg; done
Fazit
Wenn sich immer wieder einmal jemand wundert, warum aus Linux am Desktop nichts wird — hier ist die Antwort: Aufgrund vieler Kleinigkeiten versagt Linux im praktischen Betrieb und treibt seine Anwender zur Verzweiflung. Und den schwarzen Peter jetzt Apple zuzuschieben, das partout HEIF/HEVC einsetzt, ist nicht ganz fair: Diese Dateiformate kommen nun seit sechs (!) Jahren zum Einsatz, nicht erst seit gestern.
Und tatsächlich sind unter Linux eigentlich alle Puzzle-Stücke schon da. Aber ohne stundenlange Internet-Recherche lassen sie sich nicht zusammenfügen. (Ein verblüffendes Gegenbeispiel ist übrigens KDE Neon, ansonsten eigentlich nicht meine Lieblingsdistribution: Dort werden HEIC-Dateien auf Anhieb im KDE-Dateimanager korrekt angezeigt. Auch Digikam kommt mit den Dateien sofort zurecht. Leider auch nur fast: Digikam scheitert, im Portrait-Modus aufgenommene Bilder richtig zu drehen, obwohl die EXIF-Daten eigentlich da wären.)
Quellen/Links
- https://de.wikipedia.org/wiki/High_Efficiency_Image_File_Format
- https://de.wikipedia.org/wiki/High_Efficiency_Video_Coding
- https://www.omglinux.com/shotwell-updates-supports-avif-heic-images
- https://discussion.fedoraproject.org/t/trouble-opening-heic-image-format-on-fedora-36/78193
- https://devicetests.com/opening-converting-heif-pictures-ubuntu-guide

 Das System lässt sich nicht nur mit Plug-ins erweitern, sondern auch mit Ansible automatisieren, zum Erzeugen von QR Labels nutzen oder dem Abbilden der Netzwerktopologie.
Das System lässt sich nicht nur mit Plug-ins erweitern, sondern auch mit Ansible automatisieren, zum Erzeugen von QR Labels nutzen oder dem Abbilden der Netzwerktopologie. 
{kind=link}