Seit einiger Zeit gibt es ein neues Konzept für das Bereitstellen und Verwalten von PGP Keys (vor allem Public Keys): Keybase nennt sich der neue Dienst, der sich im Moment noch in der Alpha-Phase befindet und nur über eine Einladung eines Mitglieds zugänglich ist.
Micha Stöcker hat gestern einige Einladungen verteilt, sodass ich mir auch einen Account bei Keybase anlegen konnte und die Chance hatte, mir das ganze mal selbst anzusehen. Was Keybase genau ist und was ich davon halte, erfahrt ihr in diesem Beitrag.
Die Idee
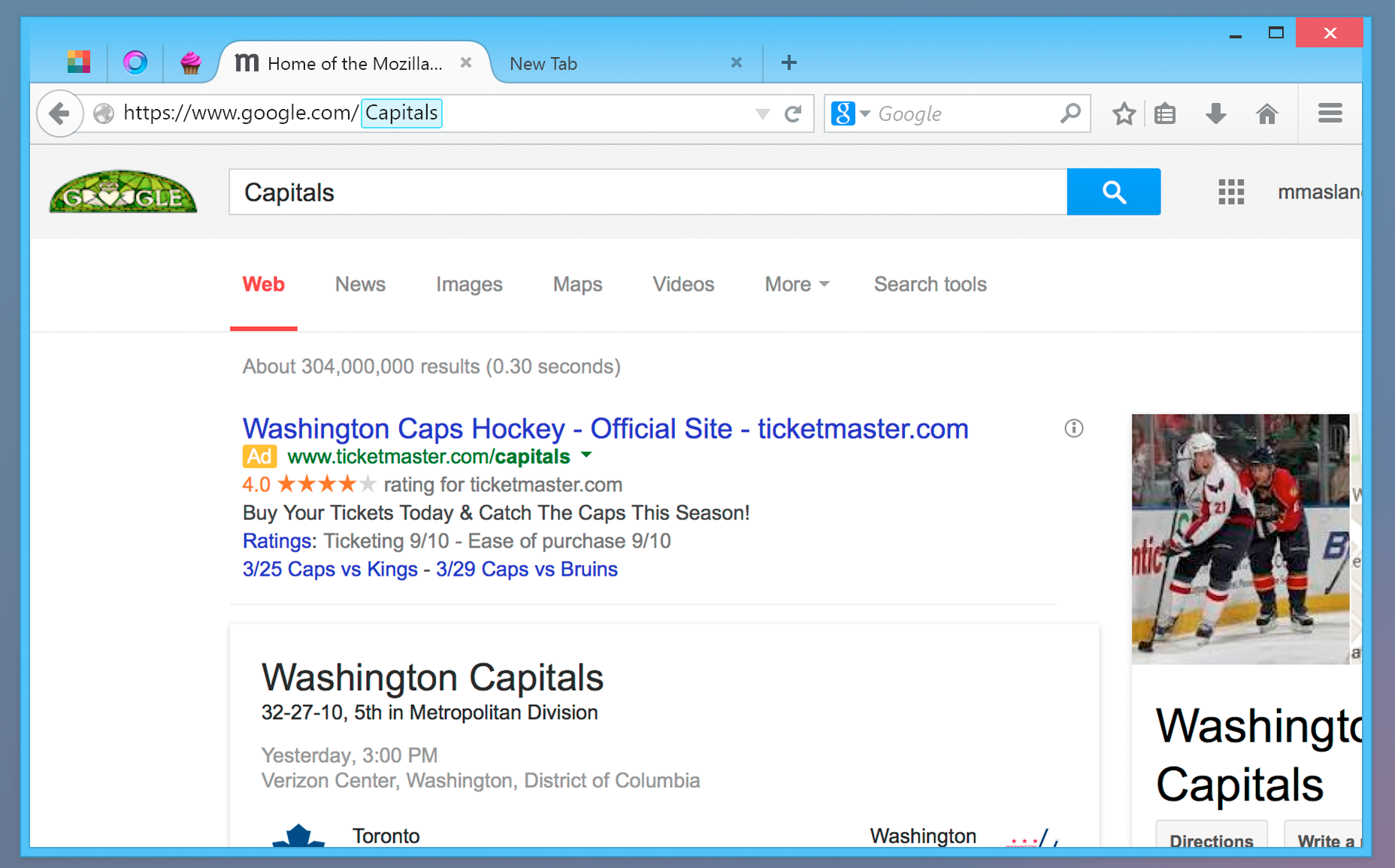
Was macht Keybase so speziell? Hinter Keybase.io steht der Gedanke, PGP Public Keys zu verifizieren. Woher will ein fremder Wissen, dass er gerade den echten Public Key einer Person herunterlädt und nicht den Key einer gefakten Identität bzw. einen manipulierten Schlüssel? Zur Absicherung gibt es bereits Verfahren, wie z.B. Keys über SSL herunterzuladen (Schutz vor Manipulation) oder Public Keys eines anderen zu signieren, sodass Dritten die Identität bestätigt wird. Heise bietet so einen Service z.B. auch an: Man besucht das Verlagsgebäude und legt dann Personalausweis und Public Key vor. Heise bestätigt dann, dass die beiden Identitäten übereinstimmen und unterzeichnet den Public Key. Menschen, die Heise vertrauen, können dann auch sicher sein, dass die Identität und der Public Key von Person x zusammengehören und echt sind.
Dieses Verfahren ist zwar relativ zuverlässig, wenn Public Keys von vertrauenswürdigen Instanzen signiert werden, sind deshalb aber nicht weniger kompliziert. PGP ist für “Normalos” komplex genug – man muss sich ja nur mal ansehen, wer denn PGP wirklich nutzt … ;). Um die Verifizierung von PGP Keys zu vereinfachen, versucht Keybase einen anderen Weg zu gehen: Grundsätzlich hat Keybase in etwa dieselbe Funktion wie der Heise Verlag im vorherigen Beispiel: Es funktioniert als CA (Certificate Authority) und bestätigt Public Keys.

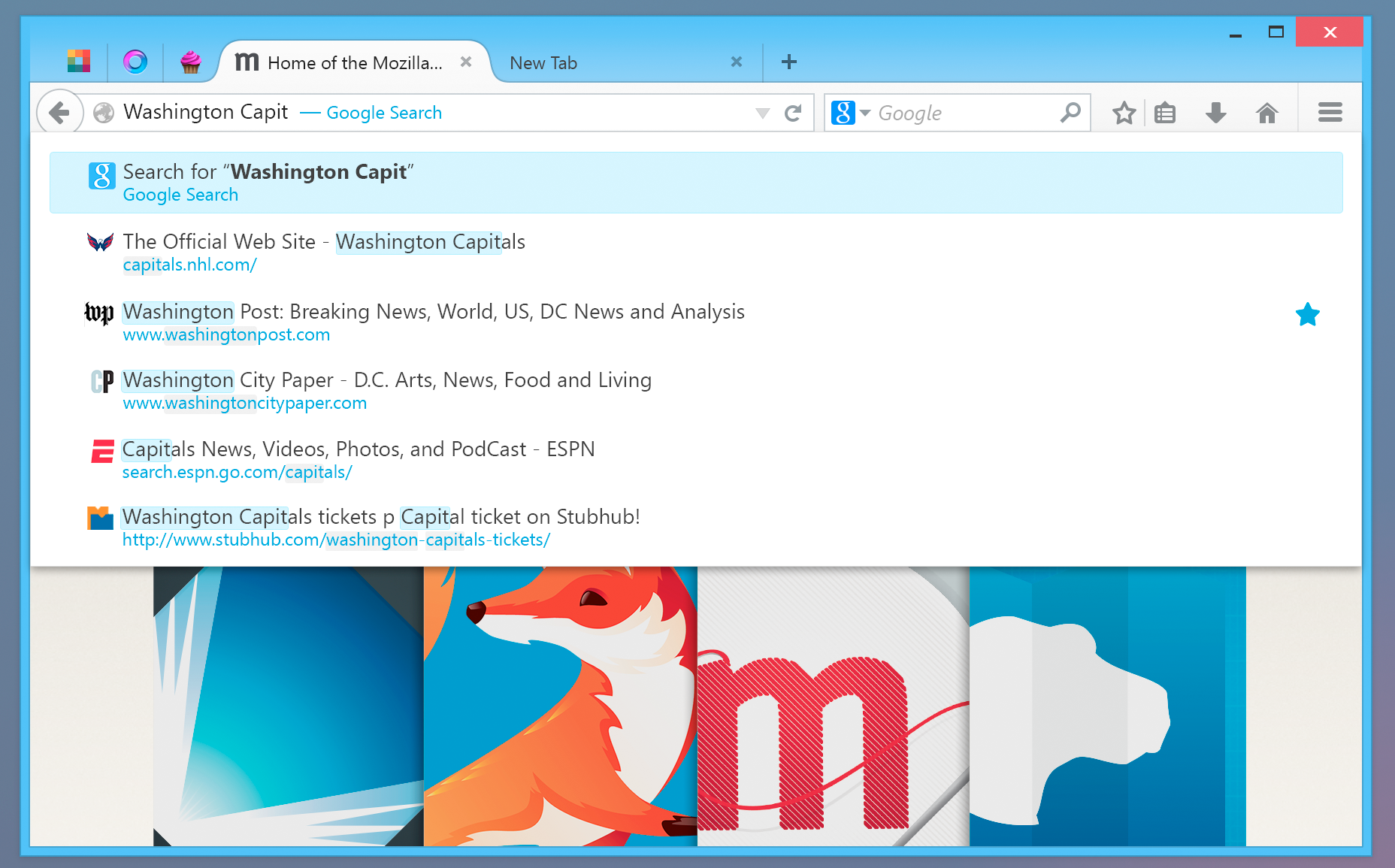
Keybase ID Suche
Die Bestätigung und Verifizierung des Schlüssels erfolgt aber nicht über den Personalausweis, sondern über bereits bestehende Identitäten im Internet: Über GitHub, Twitter, über die eigene Website, über die bereits vorhandenen und vom Hoster abgesegneten DNS Daten. Weitere Identitätsnachweise sollen kommen. So sind beispielsweise auch Verbindungen mit Facebook, Google und anderen Nutzerkonten denkbar. In der Praxis funktioniert das Verfahren so: Ich gebe in Keybase z.B. an, meine Keybase Identität (und damit meinen hochgeladenen Public Key) über GitHub verifizieren zu wollen. Über den Keybase Command Line Client gebe ich den Befehl
keybase prove github ThomasLeister
ein. Mir wird dann Text / Code ausgegeben, den ich öffentlich als GitHub Gist speichern muss. Keybase kann diesen Text dann auslesen, erkennt mich wieder und leitet daraus ab, dass mir der GitHub Account mit dem Benutzernamen “ThomasLeister” gehören muss. Damit ist bestätigt, dass mir dieser eine GitHub Account gehört und die GitHub Identität wird in die bestätigten Identitäten aufgenommen.
Wer sich meinen Public Key nun von Keybase herunterladen will, kann sehen, dass ich derselbe Thomas Leister bin, der auch als “ThomasLeister” auf GitHub unterwegs ist. Wenn noch weitere Identitäten hinzukommen, wächst somit die Sicherheit, den richtigen Public Key herunterzuladen und nicht eine gefälschte Version. Mit jedem Account, den ich mit Keybase verbinde, festigt sich meine Identität auf Keybase.
Ein Angriffsszenario
Wenn nun jemand einen falschen Public Key unter meinem Namen veröffentlichen wollte, müsste er auch einen gefälschten Keybase Account anlegen und über diesen den falschen Key publizieren. Soweit kein Problem. Das ist möglich. Jetzt kommt aber das entscheidende: Er muss andere Identitäten vorweisen und den Keybase Account “assuren”. Zu dem gefälschten Keybase Account müssten dann auch noch weitere gefälschte Accounts für GitHub, Twitter etc hinzukommen. Nehmen wir an, auch diesen Aufwand macht sich der Angreifer noch.
Ein Dritter kommt nun hinzu. Er kennt mich z.B. über Github und will nun meinen Public Key von Keybase.io herunterladen. Er findet zwei Identitäten – beide gültig für mich. Aber welche ist nun die echte, und welche die gefälschte? Ganz einfach: Es muss nur jeweils das Profil besuchen und vergleichen, welches Profil mit dem GitHub Account verbunden ist, den er kennt. Wenn er auch ausschließen will, dass mein GitHub Account gehackt wurde, kann er zusätzlich auch die Verbindung mit dem DNS oder mit einer Domain prüfen. Die Wahrscheinlichkeit, dass alle verbundenen Accounts gehacked wurden, ist sehr gering.
Die Person sucht sich also die Keybase Identität aus, die am besten zu dem passt, was bereits über mich bekannt ist und umgeht damit den Fälschungsversuch eines Angreifers.
Wer sich meinen Public Key von Keybase.io herunterlädt, kann also ziemlich sicher sein, dass er den richtigen, echten Key downloadet. [Zu meinem Profil]

Mein Keybase.io Profil
Dezentralität als Sicherheitsmaßnahme
Weil man aber niemals nur auf ein Pferd setzen wollte, bleibt mein Key natürlich auch auf den anderen Keyservern verfügbar. Auf diese Weise könnt ihr den Key von vielen, vielen Servern beziehen und müsst nicht nur einem einzelnen voll vertrauen. Ihr habt die Möglichkeit, die Keys, die ihr von verschiedenen Servern heruntergeladen habt, zu vergleichen und evtl. Unstimmigkeiten oder Manipulationsversuche festzustellen.
Weitere Möglichkeiten mit Keybase.io
Der Dienst hat noch eine weitere Funktion, die vor allem für jene gedacht ist, die normalerweise kein PGP nutzen und trotzdem mal eben eine PGP verschlüsselte Nachricht an jemanden schicken wollen. Über ein Webinterface kann ein Text und der dazugehörige Empfänger ausgewählt werden. Dann wird der Text mit dem Public Key des angegebenen Empfängers verschlüsselt und angezeigt, sodass er z.B. bequem in eine normale, unverschlüsselte E-Mail gepackt werden kann.
Anwendung könnte das z.B. finden, wenn meine nicht so technisch versierten Eltern mir sensible Daten via E-Mail zukommen lassen wollen. Sie haben auf ihren Rechnern kein PGP eingerichtet, trotzdem wäre PGP Verschlüsselung in diesem Fall eine tolle Sache. Ich schicke ihnen dann einfach einen Link auf mein Keybase Profil, wo sie die Identität anhand der verbundenen Konten nochmals überprüfen können. Sie können mir danach ganz einfach und schnell einen verschlüsselten Text zuzuschicken. Dazu brauchen sie nur den Klartext in das Feld einzugeben, “Verschlüsseln” anzuklicken und den umgewandelten Text wieder in die E-Mail einzufügen.
“Haaaaaaaaalt!!!” Werden jetzt die ersten schreien. “Du kannst doch nicht einfach den Klartext auf einer Website eingeben?! Das ist unsicher!”. Ja, das ist nicht komplett sicher. Schließlich könnte Keybase die Daten in Klartext theoretisch vor dem verschlüsseln abfangen und abspeichern. Theoretisch. In der Praxis funktioniert die Verschlüsselung komplett im Browser. Ich habe das nachgeprüft und konnte keine kritischen Anfragen an den Server feststellen. Natürlich (!) ist auch das keine 100%-ige Sicherheit, schließlich könnte Keybase ja in Ausnahmefällen und zu Missbrauchszwecken veränderten Code ausliefern, der dann dennoch Klartext an die Server schickt. Natürlich. Das halte ich aber für eher unwahrscheinlich. Angesichts des überschaubaren Risikos ist diese Funktion eine bequeme Sache, wenn man mal schnell was verschlüsseln muss und kein PGP auf dem Rechner installiert hat.
Wer öfter verschlüsselt, sollte sich PGP installieren. Wobei: Dann bitte nicht unter Microsoft Windows und Mac OS, schließlich sind das Ami-Produkte, die serienmäßig Backdoors für die NSA implementiert haben ;)
Ihr seht: Die vollständige Sicherheit gibt es nicht. Man braucht sich auch nicht über ein Webinterface aufzuregen und dann munter nebenbei PGP unter Windows XP benutzen. Ich denke ihr merkt, worauf ich hinaus will? ;)
Mein Fazit
Keybase.io ist schön gemacht und bringt wieder ein bisschen mehr Sicherheit in das Reich von PGP. Eine moderne, einfach gehaltene Oberfläche und ein herausragender Konsolenclient, der übrigens unter einer Open Source Lizenz steht, sprechen für den neuen Dienst im Web. Man muss nur aufpassen, dass man die PGP Verifizierung nicht komplett auf Keybase.io verlagert. Es ist immer gut, mehrere Möglichkeiten für einen Schlüsseldownload anzubieten und nicht nur einen, der dann im unpassendsten Moment nicht verfügbar ist. Dazu kommt ja schließlich auch noch das Risiko, dass Keybase.io selbst gehackt werden könnte oder durch Sicherheitsprobleme in Schieflage kommt. Die clientseitige Verschlüsselung über den Browser finde ich eine gute Idee – auch wenn sich manchen Sicherheitsexperten diesbezüglich die Haare aufstellen und auch ich mir der Risiken bewusst bin. Dennoch sollte man so objektiv an die Sache herangehen können und Risiken abwägen. Wenn man Windows XP oder andere Software im Einsatz hat, von der bekannt ist, dass sie Hintertüren für Geheimdienste hat … oder Software wie Java oder Flash nutzt, die ständig schwere Lücken haben… dann sollte man sich auch nicht über ein browserbasiertes Kryptosystem aufregen, das zum derzeitigen Kenntnisstand einzig und allein via JS auf dem Client läuft und keinen Klartext an die Server sendet.
Bleibt noch die Frage, wie sich Keybase.io einmal finanziert? Werbung einblenden? Wohl kaum. Aktuell gibt es keine besseren Spione im Web. Sponsoren? Schon eher. Vielleicht werden in Zukunft aber auch Premium Accounts angeboten. Wer weiß…
Wer noch weitere Lektüre zu Keybase.io beziehen will, kann sich auch mal den Beitrag von Michael Seemann ansehen, in dem er auch auf die Argumente gegen Keybase eingeht.
Leider habe ich selbst noch keine verfügbaren Einladungen. Sollte ich einmal welche ausstellen können, sage ich natürlich Bescheid ;)
Was ist eure Meinung zu Keybase.io? Wollt ihr das auch testen? Seht ihr weitere Risiken?