Wie du UNIX V5 ganz einfach auf einem PDP-11 Emulator ausprobieren kannst. Eine kurze Führung durch UNIX V5.
Wenn du ein freies Betriebssystem wie GNU/Linux verwendest, hast du vermutlich schon mal von Unix gehört. GNU/Linux sowie viele andere Betriebssysteme stammen entweder von Unix ab (FreeBSD, OpenBSD, NetBSD) oder sind stark von Unix inspiriert (GNU/Linux, GNU/Hurd). In diesem Artikel möchte ich dir die Geschichte von UNIX V5 näherbringen und dir zeigen, wie du es heute auf deinem Computer ausprobieren kannst.
Die besondere Bedeutung von UNIX V5
Die ersten Computer haben nach dem Prinzip der Stapelverarbeitung (eng.: batch processing) funktioniert. Auf einem solchen Computer konnten Programme nur nacheinander und nicht gleichzeitig ausgeführt werden. Diese Computer waren extrem gross und teuer. Um Programme auszuführen, die zu diesem Zeitpunkt oft in der Form von tatsächlichen Stapeln mit Lochkarten kamen, benötigten diese Computer oft Stunden oder Tage.
Als Computer schneller und günstiger wurden, wurde es praktikabel mehrere Programme parallel auf einem Gerät laufen zu lassen. Dieses Konzept wurde unter dem Begriff Time-Sharing bekannt. In den 60er-Jahren arbeiteten Entwickler bei den Bell Labs, bei General Electric und dem MIT zusammen, um ein solches Time-Sharing System unter dem Namen Multics zu entwickeln. Multics selbst galt damals als ein äusserts komplexes System, bei dessen Entwicklung zahlreiche neue Ideen ausprobiert wurden.
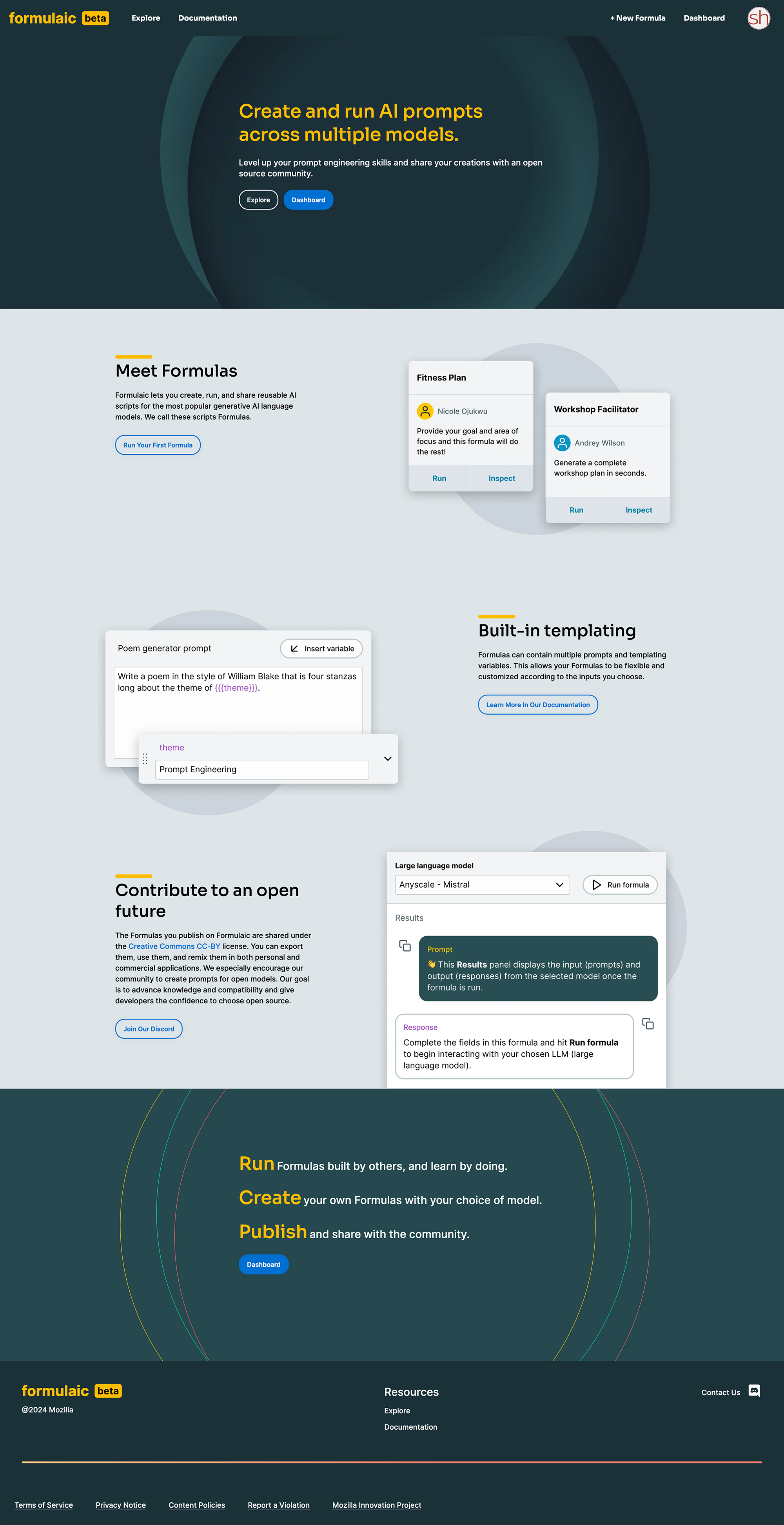
Einige ehemalige Multics Entwickler, darunter Dennis Ritchie (links im Bild) und Ken Thompson (rechts im Bild), haben in den frühen 70ern bei Bell Labs die erste Version UNIX entwickelt. Dabei haben sie bewährte Konzepte von Multics, wie das hierarchische Filesystem, wiederverwendet.
UNIX Versionen 1 - 4 haben die Bell Labs zu ihrer Zeit nie verlassen. UNIX V5 war die erste Version, die an Bildungseinrichtungen herausgegeben wurde und so an die Öffentlichkeit gelangte.
UNIX V5 auf SimH ausprobieren
UNIX V5 wurde auf einer PDP-11 (im Bild) entwickelt. Eingaben wurden von einer Tastatur gelesen und Ausgaben auf eine Papierrolle gedruckt (im Bild). Das Betriebssystem selbst konnte man auf einer wechselbaren Festplatte mit etwa 2.5 MB Speicherplatz speichern.
Um UNIX V5 auszuprobieren, kannst du die Kopie einer solchen Festplatte im Internet herunterladen:
curl -LO http://simh.trailing-edge.com/kits/uv5swre.zip
unzip uv5swre.zip
Dann benötigst du einen PDP-11 Emulator. Ich verwende dazu SimH. Das Package heist zumindest bei Debian, Arch Linux und NixOS/nixpkgs simh.
Um UNIX vom unix_v5_rk.dsk Disc Image zu starten, musst du SimH noch erklären, welche PDP-11 Version du verwenden möchtest und wie die Disc anzuhängen ist. Das Image ist von einer RK Disk und das UNIX darauf läuft auf einer PDP-11/45.
Du kannst die folgenden Zeilen im SimH pdp11 Prompt eingeben oder sie in ein File (z. B. unix_v5.ini) speichern, damit du sie nicht jedes Mal eingeben musst.
set cpu 11/45
attach rk0 unix_v5_rk.dsk
boot rk0
Dann kannst du den Emulator mit pdp11 unix_v5.ini starten. Manchmal heisst das Kommando auch simh-pdp11 (z.B. in Termux auf Android).
Falls alles geklappt hat, solltest du mit den folgenden Zeilen begrüsst werden:
PDP-11 simulator V3.11-1
Disabling XQ
@
SimH fragt dich hier, welchen Kernel du starten möchtest. Der UNIX Kernel auf dem Disk Image heisst passenderweise unix. Gib unix ein und drücke die Entertaste.
Unix startet sofort und begrüsst dich mit einer Log-in-Abfrage. Der Username ist root. Ein Passwort gibt es nicht.
Wenn du jetzt ein # siehst, hat alles funktioniert. Du bist jetzt in der UNIX V5 Shell (/bin/sh).
Wenn du dich über die spärlichen Ausgaben wunderst, denk daran, dass das gängige Ausgabegerät zu dieser Zeit ein Zeilendrucker war. Noch heute geben viele Kommandos keine Rückmeldung, wenn sie erfolgreich ausgeführt wurden.
Eine kurze Führung durch UNIX V5
Die UNIX V5 Shell fühlt sich vielleicht vertraut an. Sehr wahrscheinlich hast du noch heute einen fernen Nachkömmling davon auf deinem System. Viele bekannte Kommandos waren bereits auf diesem frühen Unix verfügbar.
Nach dem Log-in befindest du dich im Root Directory (/). Wenn du hier ls ausführst, siehst du das folgende:
# ls
bin
dev
etc
lib
mnt
tmp
unix
usr
Das Unix File ist der Kernel, den wir vorhin gestartet haben.
Sieht alles ganz vertraut aus. Doch schnell stösst du auf erste Probleme:
# cd usr
cd: not found
Tatsächlich heisst das Kommando um das aktuelle Verzeichnis zu wechseln: chdir.
Der Zeileneditor
Mein Lieblingsverzeichnis ist /usr/source. Darin findest du den Source Code zu fast allen Programmen auf dem System. Ein Teil davon ist in PDP-11 Assembler und der Rest in einem uralten C Dialekt geschrieben. C wurde nämlich zusammen mit Unix entwickelt.
Um etwa den Code des ls Programms anzuschauen, könnten wir einen Befehl wie cat /usr/source/s1/ls.c verwenden. Da du aber sehr wahrscheinlich keine Papierrolle, sondern einen Bildschirm verwendest, wirst du vermutlich nur die letzten Zeilen der Datei sehen.
Für eine bessere Brauchbarkeit der Navigation im Source Code, würde ich das ed-Programm empfehlen. Dabei handelt es sich um einen zeilenbasierten Editor. Vielleicht hast du ed noch auf deinem System oder sonst zumindest sed. Mit dem ed /usr/source/s1/ls.c Befehl kannst du den ls Quellcode öffnen. Begrüsst wirst du mit einer Zahl: 7250. Das ist die Grösse von ls.c in Bytes.
Alle Kommandos in ed sind ein Buchstabe lang. Ein Kommando quittierst du, wie gewohnt, mit der Entertaste. Wenn du das = Kommando absetzt, siehst du wieder eine Zahl: 434. Das ist die Anzahl der Zeilen in der Datei.
Viele Kommandos können auf einer Zeile oder einem Bereich von Zeilen ausgeführt werden. Anfänglich befindet sich dein „Cursor“ auf der letzten Zeile. Mit 1 und der Entertaste holst du deinen Cursor auf die erste Zeile. Dann kannst du mit Enter Zeile für Zeile nach unten navigieren.
Mit /main/ kannst du nach der Signatur der Main-Funktion suchen und mit .,.+2p kannst du die aktuelle Zeile und die darauffolgenden zwei Zeilen ausgeben.
/main/
main(argc, argv)
.,.+2p
main(argc, argv)
char **argv;
{
Wie du siehst, ist das alles sehr Papier-schonend.
Wenn ed mit einer deinen Eingaben nichts anfangen kann, gibt er ein ? aus. Was genau du falsch gemacht hast, musst du dann selbst herausfinden.
Mit dem q-Kommando kannst du ed schliessen.
Ich empfehle folgendes kleines Programm zu schreiben (volle ed Sitzung):
# ed
a
main()
{
printf("\033[2J\033[H");
}
.
w /usr/source/s1/clear.c
48
!cc /usr/source/s1/clear.c
!
!cp a.out /bin/clear
!
!rm a.out
q
Und hier nur die Eingaben ohne die Ausgaben von ed:
ed
a
main()
{
printf("\033[2J\033[H");
}
.
w /usr/source/s1/clear.c
!cc /usr/source/s1/clear.c
!cp a.out /bin/clear
!rm a.out
q
Das Programm löscht den Bildschirminhalt. Du kannst es mit clear aufrufen.
Wenn du mehr über ed lernen möchtest, kannst du unter anderem die man-Page oder das Tutorial von Brian Kernighan lesen.
Spiele
UNIX V5 kommt auch mit einer kleinen Anzahl von Computerspielen. Diese findest du in /usr/games.
ttt : Ein rudimentäres Tic-Tac-Toe
wump : Ein Text-Adventure Spiel
Viel Spass beim Ausprobieren
Wenn du wissen möchtest, was es sonst noch für Programme gibt, kannst du mit ls /bin nachsehen, welche Programme auf dem System verfügbar sind. Ausserdem findest du eine Liste mit den Programmen und einer Beschreibung ihrer Funktion im UNIX PROGRAMMER'S MANUAL.
Ich wünsche dir viel Spass beim Ausprobieren und Entdecken.
Quellen:
Bild: https://www.bell-labs.com/usr/dmr/www/picture.html
GNU/Linux.ch ist ein Community-Projekt. Bei uns kannst du nicht nur mitlesen, sondern auch selbst aktiv werden. Wir freuen uns, wenn du mit uns über die Artikel in unseren Chat-Gruppen oder im Fediverse diskutierst. Auch du selbst kannst Autor werden. Reiche uns deinen Artikelvorschlag über das Formular auf unserer Webseite ein.