Nach dem ich euch im ersten Teil erklärt habe, wie ihr eine Hugo-Website mit einem vorgefertigten Theme erstellen könnt, lernt ihr hier, ein eigenes Theme zu erstellen. Grundkenntnisse in HTML sind dafür selbstverständlich Voraussetzung. Auch Erfahrung in Go kann nicht schaden - ist für diesen Beitrag aber nicht erforderlich. Hier soll es um die Erstellung eines sehr grundlegenden Themes gehen. Ich werde daher nur auf die wichtigsten Aspekte eingehen und das Thema “Design” beispielsweise ganz beiseite lassen. Dieses Theme könnt ihr nach Belieben erweitern und ändern. Ich will euch nur eine Grundlage an die Hand geben.
Die Go Templatesprache
Während die Dokumentstruktur durch HTML vorgegeben wird, wird der Programmfluss innerhalb des Themes durch Elemente aus der Go-Templatesprache gesteuert. Die Template-Elemente werden durch zwei geschweifte Klammern vom übrigen HTML-Code abgegrenzt, z.B. so:
<h1> {{ .Title }} </h1>
<div class="content">
{{ .Content }}
</div>
In diesem Beispiel werden Titel und Inhalt einer Seite an der jeweiligen Stelle im Code ausgegeben. Der fertig generierte HTML-Code für eine Seite könnte dann z.B. so aussehen:
<h1> Mein erster Hugo-Beitrag </h1>
<div class="content">
Das ist mein erster Beitrag im neuen Hugo-basierten Blog.
</div>
Neben einfachen Ausgaben sind auch Programmfluss steuernde Elemente wie Bedingungen und Schleifen möglich. Eine Übersicht über alle Funktionselemente erhaltet ihr in der Hugo Dokumentation unter https://gohugo.io/templates/functions/ . Eine Übersicht aller standardmäßig verfügbaren Variablen (wie z.B. “Title”, oder “Content”) findet ihr hier: https://gohugo.io/templates/variables/
Aufbau des Beispiel-Themes
Navigiert in euer Projektverzeichnis für eure neue Website, die ihr zuvor via
hugo new site ./
erstellt habt. Führt dort das Kommando zum Erstellen eines neuen Theme-Grundgerüsts aus:
hugo new theme meintheme
Im themes/ Verzeichnis findet ihr jetzt ein neues Verzeichnis “meintheme”. Ändert die Hauptkonfiguration in config.toml so, dass euer neues Theme verwendet wird:
theme = "meintheme"
Wenn ihr jetzt den integrierten Webserver via hugo serve startet und die Seite im Browser (http://localhost:1313) ladet, solltet ihr nur eine weiße Seite sehen. Wir werden das neue Theme jetzt Stück für Stück aufbauen und fangen mit dem Header an.
Der Header enthält alle Seitenelemente, die für jede Einzelseite strukturell gleich sind. Also <html>, <head> bis hin zum <body> Tag. Ein fertiger Header kann beispielsweise so aussehen:
<!doctype html>
<html>
<head>
<title> {{ if .IsHome }} {{ .Site.Title }} {{ else }} {{ .Title }} {{ end }} </title>
<meta charset="utf-8">
</head>
<body>
Übernehmt den Inhalt im Theme-Verzeichnis unter themes/meintheme/layouts/partials/header.html. Im “partials” Verzeichnis werden kleine Code-Snippets gesammelt, welche später durch {{ partial ... }}-Anweisungen in andere Template-Dateien geladen werden können. Das Template kann man auf diese Weise sehr gut strukturieren und einzelne Elemente wiederverwenden.
Das dazu passende Gegenstück zum Header-Partial bildet der Footer in themes/meintheme/layouts/partials/footer.html:
</body>
</html>
Die Code-Schnipsel für Header und Footer sind erstellt und können jetzt in beliebige, andere Template-Dateien geladen werden. Für das Blog-Theme soll es zwei Seiten-Typen geben: Übersichtsseiten und Einzelseiten. Übersichtsseiten werden in themes/meintheme/layouts/_default/list.html definiert, Einzelseiten in themes/meintheme/layouts/_default/single.html. Lasst uns mit der Übersichtsseite anfangen, sodass wir erste Inhalte auf der Startseite ausgeben können:
list.html:
<!-- Header -->
{{ partial "header.html" . }}
<!-- Content -->
<!-- Footer -->
{{ partial "footer.html" . }}
Löscht jetzt die Datei “themes/meintheme/layouts/index.html”. Sie sorgt für eine gesonderte Darstellung der Startseite. Da wir hier aber eine Übersicht laden wollen, und keine speziell angepasste Seite, muss sie entfernt werden, um das gewünschte Ergebnis zu erhalten. Aktuell ist die Seite noch sehr leer: Außer dem Seitentitel in der Titelzeile des Browser-Tabs ist noch nichts zu sehen.
Inhalte für die Übersichtsseite
Um die Website mit etwas Inhalt zu füllen, kümmern wir uns im nächsten Schritt um die Übersichtsseite. Hier sollen Ausschnitte aus den letzten Blogposts angezeigt werden. Inhalt der themes/meintheme/layouts/_default/list.html:
<!-- Header -->
{{ partial "header.html" . }}
<!-- Loop through all posts -->
{{ range .Pages }}
<h2>{{ .Title }}</h2>
<p>
<small>{{ .Date.Format "02.01.2006" }}</small>
</p>
{{ .Summary }}
<p>
<a class="readmore" href="{{ .RelPermalink }}">Weiterlesen</a>
</p>
{{ end }}
<!-- End loop -->
<!-- Footer -->
{{ partial "footer.html" . }}
Jetzt ist es Zeit für einen ersten Test: Startet den Hugo Webserver via hugo -D serve und seht euch die Seite im Webbrowser an. Alle existierenden Posts sollten nun untereinander in Ausschnitten aufgelistet sein.
Um überhaupt etwas zu sehen, muss an dieser Stelle schon mindestens ein Blogpost erstellt worden sein!
Einzelseiten definieren
Die “Weiterlesen”-Links auf der Übersichtsseite führen noch ins leere. Darum kümmern wir uns jetzt. Es soll zwei Typen von Einzelseiten geben: Beitragsseiten für Blogeinträge (“articles”) und normale Seiten z.B. für Impressum, Kontakt etc. (“pages”). Durch diese Unterscheidung kann man die verschiedenen Inhaltetypen unterschiedlich gestalten. Bei normalen Seiten kann man z.B. das Datum und ggf. später Kommentare ausblenden lassen, während man bei Beitragsseiten nach dem Seiteninhalt noch “Share”-Buttons einblendet. Hugo unterscheidet standardmäßig nicht zwischen diesen beiden Seitentypen. Das macht aber nichts - wir können die Unterscheidung selbst nachbilden. Dazu wird ein neues Seitenattribut “Type” eingeführt, welches definiert, ob ein Inhalt vom Typ “article” oder “page” ist. Das Attribut wird in den Kopf jeder Markdown-Inhaltsseite aufgenommen, z.B. so:
+++
date = "2017-01-17T09:28:11+01:00"
title = "Hallo Welt!"
draft = true
type = "article"
+++
Nun aber zur Template-Programmierung. Für Einzelseiten wird immer die Datei themes/meintheme/layouts/_default/single.html geladen. Innerhalb dieser Datei soll eine Überprüfung stattfinden, um welchen Seitentyp es sich handelt, um dann das jeweils passende “Partial” - also ein Sub-Template - zu laden. Der Inhalt der single.html soll wie folgt aussehen:
<!-- Header -->
{{ partial "header.html" . }}
{{ if eq .Type "page" }}
{{ partial "page.html" . }}
{{ else }}
{{ partial "article.html" . }}
{{ end }}
<!-- Footer -->
{{ partial "footer.html" . }}
Die beiden Partials “page.html” und “article.html” müssen in themes/meintheme/layouts/partials/ noch definiert werden:
article.html
<h1>{{ .Title }}</h1>
<p>
<small>{{ .Date.Format "02.01.2006" }}</small>
</p>
{{ .Content }}
<!-- Tags -->
{{ if isset .Params "tags" }}
{{ $baseURL := .Site.BaseURL }}
<ul class="tags">
{{ range .Params.tags }}
<li> <a href="{{ $baseURL }}tags/{{ . | urlize }}/">#{{ . }}</a> </li>
{{ end }}
</ul>
{{ end }}
page.html
<h1>{{ .Title }}</h1>
{{ .Content }}
Stellt sicher, dass jeder Blog-Beitrag mit type = "article" im Kopfbereich gekennzeichnet ist, sonst wird er nicht angezeigt!
Tags
Im unteren Teil der article.html befindet sich die Ausgabe der Tags, die einem Beitrag zugeordnet sind. Passende Tags können in der Kopfzeile jeder Markdown-Datei angegeben werden, z.B.
+++
date = "2017-01-17T09:28:11+01:00"
title = "Hallo Welt!"
draft = true
type = "article"
tags = [ "Begrüßung", "Allgemein" ]
+++
Wenn Tags vorhanden sind, werden sie unten auf der Seite eingeblendet. Ein Blick auf ein Tag führt zu einer Übersichtsseite mit dazu passenden Blogposts.
Normale Seiten ausblenden und Seitennavigation
Aktuell erscheinen auch normale Seiten (“pages”) wie z.B. eine Impressum-Seite in der Übersicht, wenn für sie type = "page" im Kopfbereich definiert wurde. Das können wir ändern, indem bei der Auflistung von Seitenausschnitten nur noch Inhalte vom Typ “article” berücksichtigt werden. Ändert dazu die list.html so ab:
<!-- Header -->
{{ partial "header.html" . }}
<!-- Loop through all posts -->
{{ $paginator := .Paginate (where .Data.Pages "Type" "article") }}
{{ range .Paginator.Pages }}
<h2>{{ .Title }}</h2>
<p>
<small>{{ .Date.Format "02.01.2006" }}</small>
</p>
{{ .Summary }}
<p>
<a class="readmore" href="{{ .RelPermalink }}">Weiterlesen</a>
</p>
{{ end }}
<!-- End loop -->
<!-- Navigation -->
{{ partial "page-navigation.html" . }}
<!-- Footer -->
{{ partial "footer.html" . }}
Ein “Paginator” filtert jetzt die Inhalte nach Typ und sorgt für die Einteilung in Seiten. Am unteren Ende der Seite wird via {{partial ... }} - ähnlich wie bei Header und Footer - ein kleines Snippet eingebunden, das die Navigation darstellt. Legt unter layouts/partials/ eine neue Datei “page-navigation.html” an, die folgendes enthält:
{{ if or (.Paginator.HasPrev) (.Paginator.HasNext) }}
{{ if .Paginator.HasNext }}
<a href="{{ .URL }}page/{{ .Paginator.Next.PageNumber }}">← Ältere Beiträge </a>
{{ end }}
{{ if .Paginator.HasPrev }}
<a href="{{ .URL }}page/{{ .Paginator.Prev.PageNumber }}">Neuere Beiträge →</a>
{{ end }}
{{ end }}
In der Hauptkonfiguration config.toml kann mit Paginate eingestellt werden, nach wie vielen Beitrags-Ausschnitten eine neue Seite zum Blättern angelegt werden soll:
languageCode = "de-de"
title = "Meine Hugo-Site"
baseurl = "https://meinehugoseite.tld"
theme = "meintheme"
Paginate = 5
Dem Header fehlen noch HTML-Tags zum Einbinden eines Stylesheets und des RSS-Feeds:
<!doctype html>
<html>
<head>
<title> {{ if .IsHome }} {{ .Site.Title }} {{ else }} {{ .Title }} {{ end }} </title>
<meta charset="utf-8">
<link rel="stylesheet" href="{{ .Site.BaseURL }}css/main.css">
{{ if .RSSLink }}<link href="{{ .RSSLink }}" rel="feed" type="application/rss+xml" title="{{ .Site.Title }}" />{{ end }}
</head>
<body>
Das Stylesheet kann im Theme-Ordner unter static/css/main.css angelegt werden. Der RSS-Feed wird automatisch generiert und kann unter http://localhost:1313/index.xml abgerufen werden. Standardmäßig enthält er jedoch - wie die Übersichtsseiten zuvor - auch einfache Seiten, die man nicht im Feed haben will. Wenn im RSS-Feed nur Inhalte vom Typ “article” erscheinen sollen, muss ein eigenes Template für den RSS-Feed erstellt werden:
themes/meintheme/layouts/rss.xml
<rss version="2.0" xmlns:atom="http://www.w3.org/2005/Atom">
<channel>
<title>{{ with .Title }}{{.}} on {{ end }}{{ .Site.Title }}</title>
<link>{{ .Permalink }}</link>
<description>Die neuesten Inhalte auf {{ .Site.Title }}</description>
<generator>Hugo -- gohugo.io</generator>{{ with .Site.LanguageCode }}
<language>{{.}}</language>{{end}}{{ with .Site.Author.email }}
<managingEditor>{{.}}{{ with $.Site.Author.name }} ({{.}}){{end}}</managingEditor>{{end}}{{ with .Site.Author.email }}
<webMaster>{{.}}{{ with $.Site.Author.name }} ({{.}}){{end}}</webMaster>{{end}}{{ with .Site.Copyright }}
<copyright>{{.}}</copyright>{{end}}{{ if not .Date.IsZero }}
<lastBuildDate>{{ .Date.Format "Mon, 02 Jan 2006 15:04:05 -0700" | safeHTML }}</lastBuildDate>{{ end }}
<atom:link href="{{.URL}}" rel="self" type="application/rss+xml" />
{{ range first 15 .Data.Pages }}
{{ if eq .Type "article" }}
<item>
<title>{{ .Title }}</title>
<link>{{ .Permalink }}</link>
<pubDate>{{ .Date.Format "Mon, 02 Jan 2006 15:04:05 -0700" | safeHTML }}</pubDate>
{{ with .Site.Author.email }}<author>{{.}}{{ with $.Site.Author.name }} ({{.}}){{end}}</author>{{end}}
<guid>{{ .Permalink }}</guid>
<description>{{ .Content | html }}</description>
</item>
{{ end }}
{{ end }}
</channel>
</rss>
Über die Bedingung {{ if eq .Type "article" }} werden unpassende Inhalte ausgeblendet.
Das Grundgerüst eures Themes ist damit fertig! Jetzt braucht ihr noch passendenden HTML-Code und CSS-Regeln zu schreiben, um euer Design umzusetzen. Wenn ihr euer Theme noch erweitern und zusätzliche Funktionalität oder Inhalte hinzufügen wollt, empfehle ich euch, die Hugo Dokumentation zu lesen: https://gohugo.io/templates/overview/
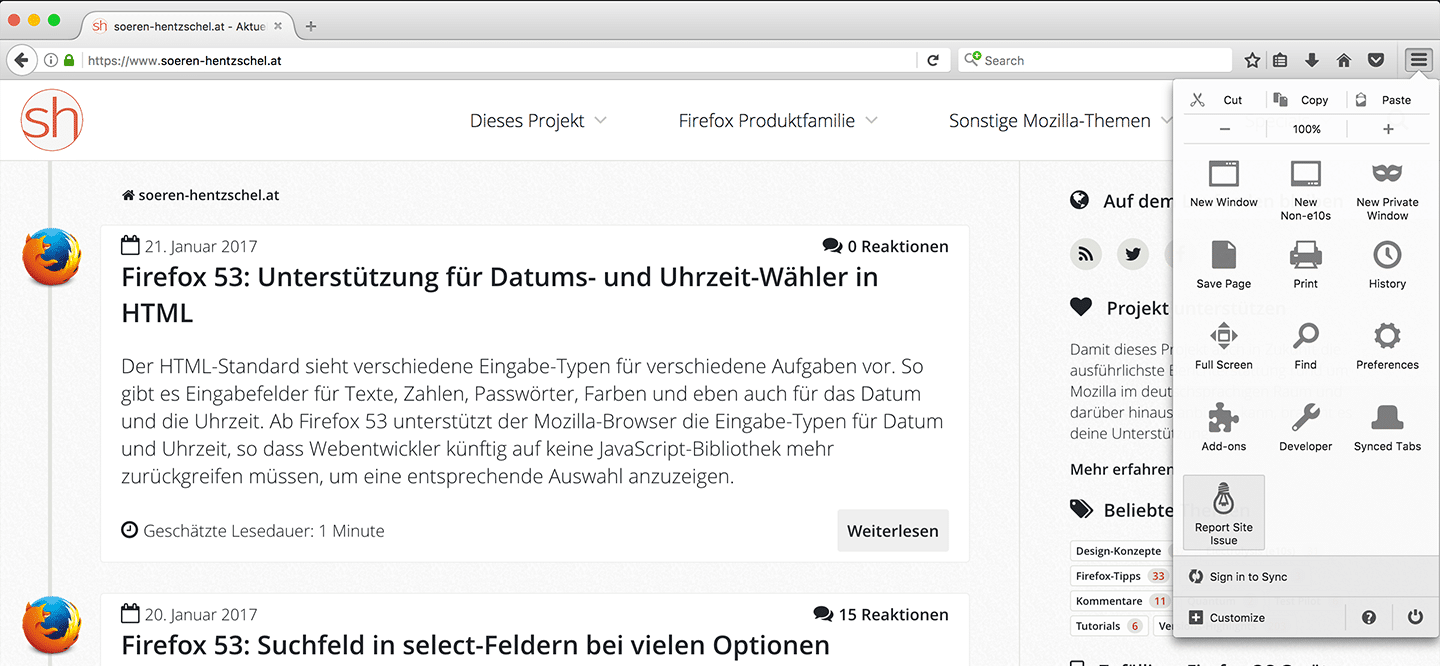
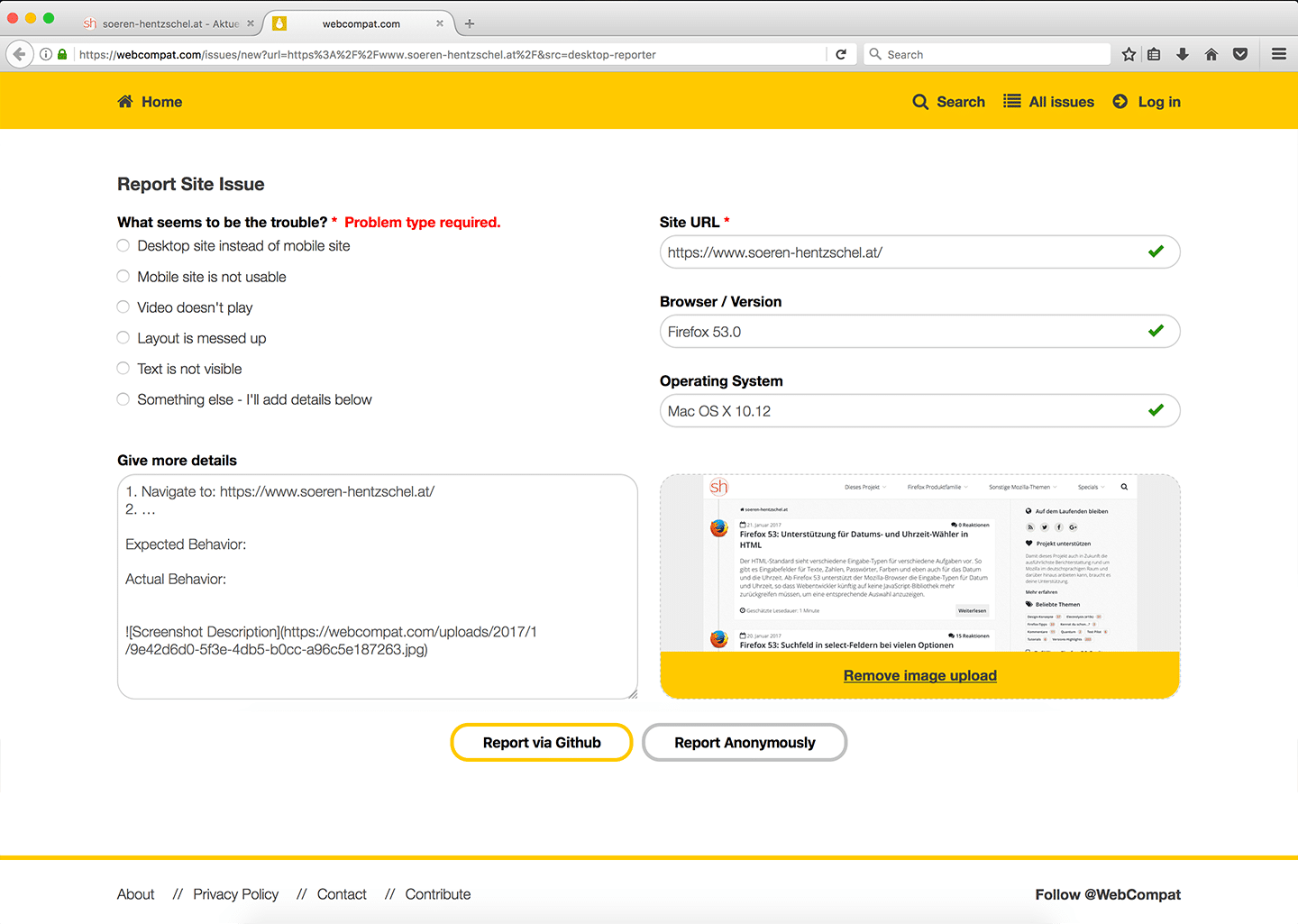
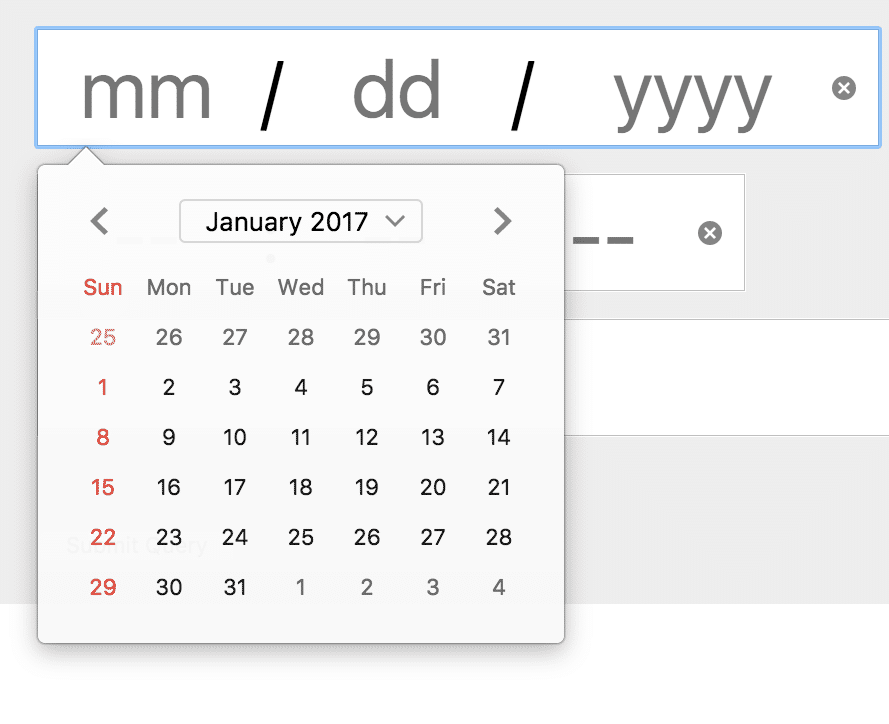
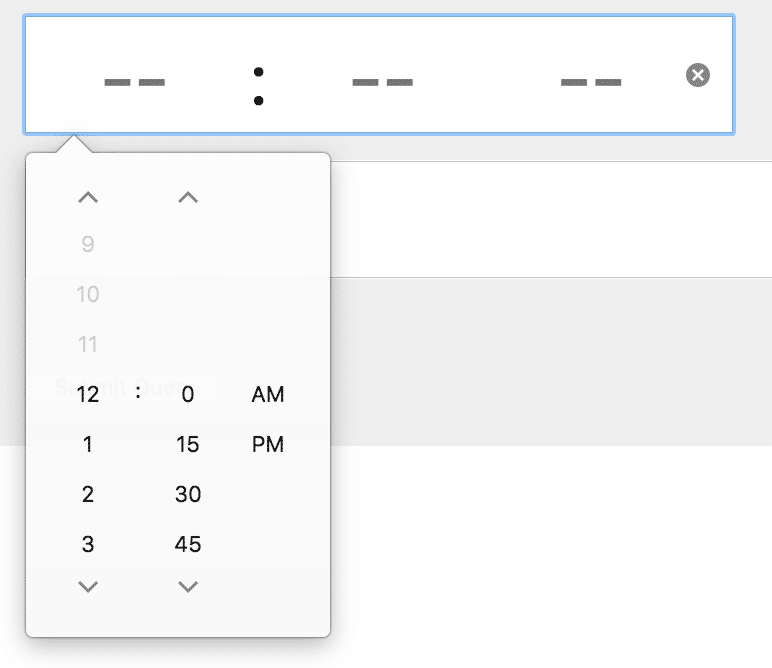





 Die Sammlung kann sich jetzt schon sehen lassen und darf dank ihrer offenen Architektur von allen erweitert werden. Dazu genügt ein Klick auf das Plus Symbol in der jeweiligen Kategorie.
Die Sammlung kann sich jetzt schon sehen lassen und darf dank ihrer offenen Architektur von allen erweitert werden. Dazu genügt ein Klick auf das Plus Symbol in der jeweiligen Kategorie.