Wer Microsoft PowerShell Core 6 unter Linux oder auch einem anderen Betriebssystemen nutzt, sendet automatisch Telemetriedaten an Microsoft. Ja genau, auch wenn Ihr kein Microsoft Windows verwendet, versucht der Konzern Daten über seine Software mittels Telemetrie von euch zu erhalten. In einem anderen Artikel habe ich euch bereits erklärt wie PowerShell Core unter Linux installiert wird. Hier möchte ich euch zeigen wie Ihr die PowerShell Core Telemetrie deaktivieren könnt.
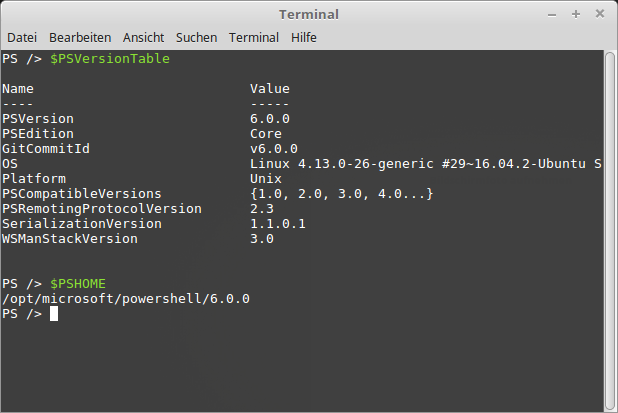
Laut Microsoft angaben sollen nur das Betriebssystem und die Version von PowerShell erhoben und gesendet werden. Diese Daten sind auch in folgenden PowerShell Variablen enthalten:
$PSVersionTable.OS
$PSVersionTable.GitCommitId
Die Daten aus der Varibale “$PSVersionTable.OS” erhaltet Ihr auch mit dem Linux Befehl “uname -srv“.
Wie deaktiviere ich die Telemetrie bei PowerShell Core?
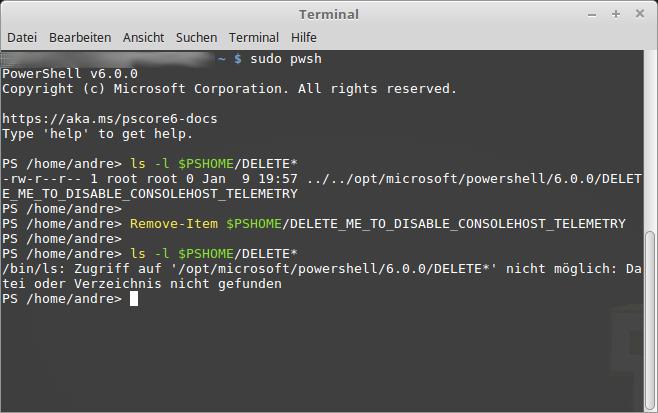
Wenn Ihr PowerShell Core (PSCore) weiterhin Nutzen möchtet, könnt Ihr die optionale Option zur Telemetrie Deaktivierung nutzen. Um dies zu erreichen, muss aus dem Installationsverzeichnis von PowerShell Core ($PSHome) die Datei mit dem Namen DELETE_ME_TO_DISABLE_CONSOLEHOST_TELEMETRY entfernt werden.
Über die Linux Konsole (Bash) PSCore Telemetrie deaktivieren:
Danach dürfte Microsoft keine Daten mehr über die PSCore Telemetry von euch erhalten.
Interessantes zur den Telemetriedaten von PowerShell Core
Eine Auswertung über die gesammelten Telemetriedaten von PowerShell Core und zum Projektstatus hat Microsoft mit seinem Tools PowerBI und Azure auf dieser Seite visualisiert.
Der Browser ist zumindest mittelfristig der zentrale Baustein für ein ausgefeiltes Konzept zum Schutz von Sicherheit und Privatsphäre. Im Internet gibt es zig Anleitungen wie man Browser absichert und welcher Browser zu empfehlen ist. Manches davon ist Marketing, aber vieles auch interessant und lesenswert. Manchmal zeigen die Begründungen aber auch argumentative Schwachstellen und es gibt Vorannahmen, die nicht hinterfragt werden. Darunter gerne: Open Source ist gut!
So konnte man kürzlich in einem sehr guten Blog zu dem Thema den ersten Teil einer Artikelserie zur Absicherung von Firefox lesen. Bereits der erste Teil ist lesenswert und die weiteren Teile werden hoffentlich auch interessant. Der Autor hat mit dem Zwischenfazit, dass sich unter all den Browsern da draußen, vor allem Firefox als Grundlage eignet, sicherlich nicht unrecht. Insbesondere die Bemerkung über die - angeblich so sicherheitsorientierten - Forks ist gut und wichtig.
Die Grundannahme lautet jedoch: Einige Browser werden von vornherein ausgeschlossen, weil sie nicht quelloffen sind. Firefox ist hingegen quelloffen und daher das geringere Übel. Eine einsehbarer Quellcode ist in dieser Argumentation ein grundlegender Baustein für Sicherheit.
Quelloffen bedeutet: Der Quellcode ist frei (also offen) von jedem einsehbar. Nach meiner Auffassung ist das eine »zwingende« Voraussetzung, denn Quelloffenheit bedeutet Transparenz – ein wichtiges Element der IT-Sicherheit, denn sie ist eng mit Vertrauen verknüpft. Proprietärer Software muss man vertrauen, dass sie sicher ist und keine Backdoors integriert hat. Bei quelloffener Software (Transparenz) kann dies (und sollte auch regelmäßig) von vielen Augen geprüft werden.
Weiter unten heißt es jedoch im Abschnitt zu Chrome - und ausdrücklich auch erwähnt - Chromium.
Chrome / Chromium: Chrome ist ein Browser von Google. Allein das genügt eigentlich schon, um einen großen Bogen um den Browser zu machen. [...] Erst Chromium ist vollständig quelloffen und unterscheidet sich von Chrome.
Hier muss man sich doch fragen: Ist Chromium denn nicht quelloffen genug? Laut Homepage ist Chromium ein quelloffenes Projekt und steht unter BSD-Lizenz. Die Unterschiede zu Chrome sind bekannt. Warum Chromium trotzdem im folgenden ausscheidet bleibt unklar. Mutmaßlich gibt die enge Anbindung an Google hier den Ausschlag.
Grundsätzlich kann man die Annahme teilen, dass ein Browser, der maßgeblich von Google entwickelt wird nicht sicher hinsichtlich des Schutzes der Privatsphäre sein kann. Hier gilt das gleiche wie für Android (siehe: Kommentar: Android - Keine sichere Alternative Teil II - Standortdaten über Bluetooth). Warum ist aber das eine Projekt vertrauenswürdig, weil es quelloffen ist - trotz dutzender fragwürdiger Entscheidungen in der jüngeren Vergangenheit (siehe: Firefox Quantum - Abstieg trotz Quantensprung?) - während das andere Projekt von seinem Open Source Status nicht profitiert?
Nun, vermutlich liegt das daran, dass so große Projekte wie Chromium oder Firefox von niemandem komplett überblickt werden können - schon gar nicht von Außenstehenden. Der offen liegende Quellcode wird dann aber zu einem reinen PR-Argument, weil eine faktische Sicherheitsüberprüfung nicht stattfindet oder stattfinden kann. Sofern man den Ergebnissen einer gängigen Suchmaschine trauen darf, hat es bisher auch kein vollständiges Audit einer aktuellen Firefox-Version gegeben, das gleiche gilt für Chromium.
Doch wo ist dann der Vorteil gegenüber proprietären Projekten ohne frei zugänglichen Quellcode? Es geht hier um Vertrauen und quelloffene Projekte verdienen diesen scheinbar - es sei denn sie stammen von Google. Das ist eine Argumentation mit schwerer Schlagseite und zeigt die Schieflage, in der sich die vernetze Open Source- und Datenschutzgemeinde machmal befindet.
Trotzdem ist Firefox ein guter Browser und hinsichtlich der Sicherheit eine gute Wahl. Lediglich die Argumentationsmuster muss die Open Source-/Datenschutz-Gemeinschaft nochmal hinterfragen. Die oben genannten Zitate sind exemplarisch, aber bei weitem nicht singulär. Nicht jede Voranahme ist richtig, wenn man sie lange genug behauptet.
Schon lange strebe ich danach mich möglichst unabhängig von Google und anderen Konzernen zu machen, die meine Daten verwerten. So nutze ich einen selbst betriebenen Mailserver, den ich mit iRedMail aufgesetzt habe, nutze Nextcloud mit Collabora Online. Ich habe zwar noch Accounts bei kommerziellen Sozialen Netzwerken, doch eigentlich nutze ich seit kurzem nur noch meinen Mastodon-Account, auf der Instanz, die ich vor einigen Wochen aufgesetzt habe. Als Suchmaschine habe ich bisher sowohl auf meinem Smartphone, als auch auf meinen Rechnern StartPage als datensparsame Google-Alternative verwendet.
Startpage verwendet auch die Google-Ergebnisse, speichert im Unterschied zu Google aber nicht die IP-Adressen der Nutzer und wertet auch nicht andere Daten des Nutzers aus. So fehlen die personalisierten Suchergebnisse, doch diese, meist ja als Werbung deutlich werdenden Ergebnisse, haben mir nie gefehlt.
Vor einigen Tagen stieß ich zum wiederholten Male auf Searx. Searx ist im Unterschied zu StartPage eine Metasuchmaschine, d.h. es werden Ergebnisse aus verschiedenen Suchmaschinen abgerufen und aufbereitet. Gemeinsam mit StartPage hat Searx, dass Datenschutz eine entscheidende Motivation ist. Ein weiterer gewichtiger Unterschied zwischen den beiden ist der, dass Searx freie Software ist und selber betrieben werden kann. Dies habe ich direkt als Ansporn genommen und habe Searx entsprechend der Installationsanleitung aufgesetzt. Die Installation unter Ubuntu ist so wirklich ein Kinderspiel. Erreichbar ist die von mir aufgesetzte Suchmaschine unter searx.site. Viel Spaß beim Testen und Nutzen!
Mozilla hat ein Update außer der Reihe für Firefox 58 veröffentlicht. Mit dem Update auf Firefox 58.0.2 behebt Mozilla eine mögliche Absturzursache der Tabs während des Druckvorgangs. Wegen Abstürzen in Zusammenhang mit dem Off Main Thread Painting (OMTP) wurden zusätzliche Grafikkarten-Treiber auf die Blockierliste gesetzt. Außerdem wurden Probleme in den Webmailern Microsoft Hotmail sowie Microsoft Outlook behoben und ein Problem mit dem Programm-Update unter Apple macOS behoben.
Bei meiner täglichen Arbeit, komme ich mit Microsoft Windows Systemen und PowerShell in Berührung. Privat beschäftige ich mich jedoch überwiegend mit Linux und Open Source Themen. Umso interessanter finde ich es, dass beide Welten immer mehr mit einem Werkzeug administriert werden sollen. Wenn es nach Microsoft geht, ist dieses Werkzeug PowerShell Core. Letzten Monat hat Microsoft dies in der Version 6.0 veröffentlicht.
PowerShell Core und Windows PowerShell?!
Ein kurzer Umriss, für alle die damit nicht so vertraut sind. PowerShell ist ein Kommandozeilen-basiertes Framework womit sich Vorgänge automatisieren und Systeme administrieren lassen. PowerShell Core (PSCore) ist als Open Source (MIT-Lizenz) für Windows, Linux sowie macOS verfügbar. PSCore ist eine Abspaltung (Fork) von Windows PowerShell.
PSCore setzt auf der CoreCLR (.NET Core Common Language Runtime), was im Gegensatz zum proprietären Windows PowerShell der CLR (Common Language Runtime) des .NET Framework und Microsoft liefert dies mit Windows als Teil des Windows Management Framework (WMF) aus.
Mit PowerShell Core kann man allerdings nur die Funktionen von .NET Core und .NET Standard nutzen. Dies liegt daran, dass im Hintergrund für statisches .NET-Methoden oder C#-Cmdlets immer auf die Runtimes von .NET Core zurückgegriffen wird. Einige PowerShell Module wie z.B. ActiveDirectory werden laut Microsoft nicht für PowerShell Core unterstützt. Dies bedeutet aber nicht, dass diese nicht lauffähig sind (Konnte ich leider nicht testen). Also Achtung, die Befehle sind nicht über alle Versionen für unterschiedliche Betriebssysteme gleich. PowerShell Core stellt nur einen Teil der Befehle und Module von Windows PowerShell zur Verfügung.
Vorteile PowerShell Core auf Linux?
Diese Frage hat mich erst etwas länger beschäftigt. Wenn man es aber aus Sicht eines reinen Windows Administrator sieht, dann kann man sich auf einem Linux Host ähnlich wie auf einem Windows Server in PowerShell bewegen und Befehl abfeuern um Informationen zu erhalten. Ein Linux Administrator hingegen wird hier (Ohne PowerShell Kenntnisse) keine Vorteile erhalten. Die Mischung macht es! Wenn man auf beiden Systemen zu Hause ist, dann können beide mit (fast) den gleichen Befehlen administriert werden. Außerdem stehen einem so .Net Standard Funktionen unter Linux zur Verfügung (z.B. “[math]::pi”).
Wie PowerShell Core auf Linux installieren?
Das Microsoft PowerShell Team stellt auf GitHub für Ubuntu, Debian *.deb und für CentOS, Red Hat Enterprise, OpenSUSE, Fedora *.rpm offizielle Pakete mit einer Installations-Anleitung zur Verfügung. Unterstützung von der Community gibt es dabei für Arch Linux, Kali Linux und andere Linux Versionen die mit *.AppImage umgehen können.
Wer direkt aus dem Microsoft repository PowerShell unter Ubuntu 17.04 installieren möchte, geht wie folgt vor:
# Import the public repository GPG keys
curl https://packages.microsoft.com/keys/microsoft.asc | sudo apt-key add -
# Register the Microsoft Ubuntu repository
curl https://packages.microsoft.com/config/ubuntu/17.04/prod.list | sudo tee /etc/apt/sources.list.d/microsoft.list
# Update the list of products
sudo apt-get update
# Install PowerShell
sudo apt-get install -y powershell
# Start PowerShell
pwsh
Weitere Informationen was bei PowerShell Core Version 6.0 neu ist, findet ihr bei Microsoft.
PSCore gut zu Wissen!
Im Gegensatz zu Windows PowerShell oder der normalen Linux Konsole gibt es ein paar Dinge bei PSCore unter Linux zu beachten.
Aliase
Einige unter Linux bekannte Befehle wie z.B. “ls”, “cat” oder”man” sind unter Windows ein Alias für entsprechende PowerShell CMDlets. Diese stehen daher nicht unter Linux oder macOS zur Verfügung, da es hier eigenständige Befehle (außerhalb von PowerShell) sind. Bei PSCore unter Linux gibt es aber auch Aliase die genutzt werden können (Aufruf über “alias”).
Case-sensitivity
Unter Linux wird zwischen Groß-/Kleinschreibung auch in Powershell Core unterschieden. Bei PSCore unter Windows ist dies nicht so.
Slash
Für Pfadangaben unter Windows werden beide Schrägstriche (Slash) akzeptiert, sowohl Slash “/” als auch Backslash “\”. Unter Linux und macOS ist dies nicht so. Hier wird nur “/” in Pfadangaben akzeptiert. Zum bilden von Pfaden sollte man in PowerShell Befehle (CMDlets) wie “Split-Path” oder “Join-Path” sowie PowerShell Umgebungsvariablen “$pwd” oder $PSScriptRoot einsetzen.
Object-Type
Unter Linux liefern Befehle wie z.B. “ls” einen String in PowerShell Core zurück (Siehe Punkt Alias). In Windows hingegen sind es Objekte die zurückgegeben werden (Get-ChildItem” alias “ls”). Generell geben die meisten PowerShell CMDlets (Betriebssystem unabhängig) ein Objekt zurück.
Persönliche Erfahrung
PowerShell Core unter Linux zu nutzen, während man vorher Windows PowerShell fast täglich anwenden, erfordert zum umdenken. Außerdem ist man durch die geringen Befehle (CMDlets) und fehlenden zusätzlichen Module teilweise stark eingeschränkt. Dies kann einem beim Linux PowerShell Skripting als Windows Administrator schnell zum Verhängnis werden.
Womit ich in letzter Zeit unter Windows PS beschäftigt habe ist Common Information Model (CMI), zum auslesen von Informationen (ähnlich der WMI (Windows Management Instrumentation)). Diese Unterstützung ist zur Zeit nicht geplant. Es könnte aber wie andere Features zukünftig, sofern die Entwickler-Community dies wünsch, implementiert werden.
Ich sehe PSCore noch nicht als Sinnvollen Ersatz für die gute alte Konsole (bash) in Verbindung mit einigen Tool unter Linux an. PSCore hat aber Potenzial für Administratoren als übergreifendes Werkzeug zu dienen, wenn diese verschiedene Betriebssysteme in einem Netzwerk betreuen müssen. Evtl. nehme ich aber dies auch nur so war, da Windows und Linux bisher immer getrennt betrachtet wurden und PowerShell mir aktuell nur unter Windows Vorteile bringt. Für Windows Administratoren bringt PowerShell Core unter Linux sicherlich Vertrautheit und den Vorteil sich nicht mit den Eigenheiten der Linux Konsole (bash) beschäftigen zu müssen.
Heute bin ich über eine kleine bash Funktionalität gestolpert. Normalerweise werden alle eingegebenen Befehle auf der Bash Shell in der Historie gespeichert und können ja über den „history“ Befehl oder über Angabe der „Zeilennummer“ mit einem Ausrufezeichen wiederholt werden.
Beispiel
$ history
826 [2018-02-08 19:25:05] date
827 [2018-02-08 19:25:22] history
828 [2018-02-08 19:37:18] top
$ !826
date
Do 8. Feb 19:44:22 CET 2018
Wenn nun aber vor dem eigentlich Befehl ein Leerzeichen mit auf er bash eingegeben wird taucht der Befehl NICHT in der history auf. Der Befehl ist auch nicht über die „Pfeil hoch“ Tasten verfügbar.
$ cal
$ history
826 [2018-02-08 19:25:05] date
827 [2018-02-08 19:25:22] history
828 [2018-02-08 19:37:18] top
829 [2018-02-08 19:44:22] date
830 [2018-02-08 19:50:23] history
Man beachte bei der Eingaben von „cal“ den Minimal größeren Abstand.
Dies kann sehr hilfreich sein wenn man aus irgendwelchen Gründen ein PW in der Kommandozeile eingeben möchte ohne das dieses in der Historie landet.
Ich habe versucht das selbe mit einer csh zu reproduzieren. Hat nicht funktioniert.
Diese Frage wurde bereits von Scott in seinem englischsprachigen Blog beantwortet. Ich gebe sie an dieser Stelle wieder, um nicht immer wieder danach suchen zu müssen.
Das Kommando lautet:
tcpdump -c 20 -s 0 -i eth1 -A host 192.168.1.1 and tcp port http
Die Parameter bedeuten:
-c 20: Beendet den Vorgang, nachdem 20 Pakete aufgezeichnet wurden.
-s 0: Die mitgeschnittenen Nutzdaten sollen ungekürzt wiedergegeben werden.
-i eth1: Zeichne nur Pakete an der Netzwerkschnittstelle eth1 auf.
-A: Gebe alle Pakete in ASCII aus.
host 192.168.1.1: Zeichne nur Pakete auf, die von Host 192.168.1.1 kommen.
and tcp port http: Zeichne nur HTTP-Pakete auf.
Ergänzt man den Befehl noch um -w DATEINAME wird die Aufzeichnung in eine Datei statt auf die Standardausgabe geschrieben.
Wer häufiger mit Git arbeitet und dort auf Merge-Konflikte stößt, hat bei größeren
Konflikten keinen sonderlich großen Spaß diese aufzulösen. Häufig bietet es
sich dabei an, ein Mergetool zu verwenden, der einem die Arbeit erleichtern soll.
Einige Mergetools existieren für die Kommandozeile, andere auch als grafische
Tools.
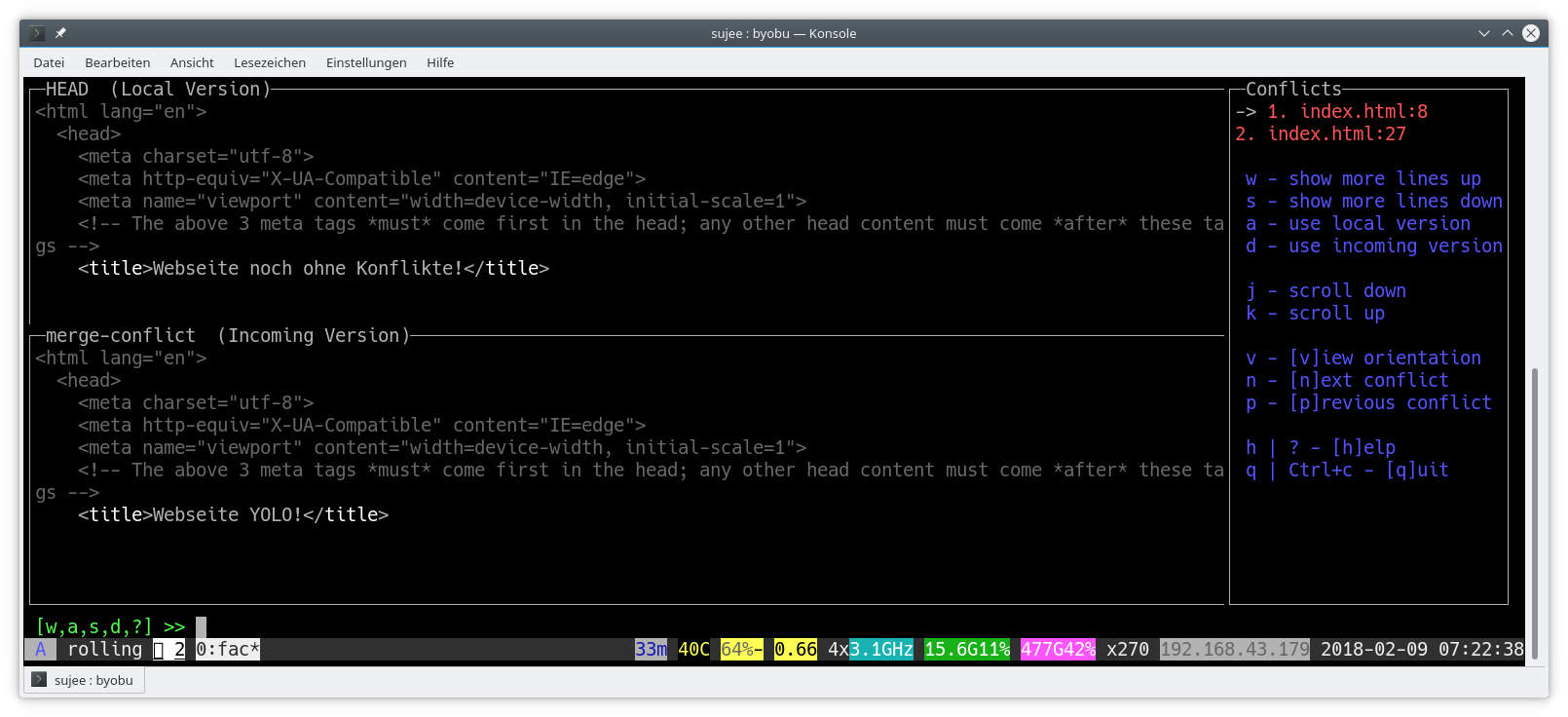
Kürzlich bin ich auf das kleine Tool „fac“ gestoßen, was
kurz für „Fix All Commits“ steht. „fac“ ist ein in Go geschriebenes CUI, also
ein Commandline User Interface, um Merge-Konflikte aufzulösen.
Das Schöne daran ist die einfache Nutzung und die übersichtliche Darstellung
im Terminal, der zunächst erstmal nur die benötigten und relevanten Zeilen anzeigt.
Zusätzliche Zeilen lassen sich allerdings mit wenigen Tastendrücken anzeigen.
Aussehen tut dies etwa so:
„fac“ ist in Go geschrieben und kann über go auch heruntergeladen werden:
$ go get github.com/mkchoi212/fac
Die Binärdatei liegt anschließend unter ~/go/bin/fac. Den Pfad sollte man dann
entweder zu seiner $PATH Variable hinzufügen oder direkt aufrufen. Leider
gibt es noch keine Unterstützung als Git Mergetool. Dazu existiert aber ein
Issue.
Natürlich gibt es auch andere Mergetools, die man verwenden kann. Mir gefällt in
diesem Fall die einfache Benutzung und die geringe Einstiegshürde, die das Tool
mit sich bringt. Verbesserungspotenzial ist da natürlich auch da, da eine schönere
Diff-Ansicht des Konfliktes begrüßenswert wäre.
Wer häufiger mit Git arbeitet und dort auf Merge-Konflikte stößt, hat bei größeren
Konflikten keinen sonderlich großen Spaß diese aufzulösen. Häufig bietet es
sich dabei an, ein Mergetool zu verwenden, der einem die Arbeit erleichtern soll.
Einige Mergetools existieren für die Kommandozeile, andere auch als grafische
Tools.
Kürzlich bin ich auf das kleine Tool „fac“ gestoßen, was
kurz für „Fix All Commits“ steht. „fac“ ist ein in Go geschriebenes CUI, also
ein Commandline User Interface, um Merge-Konflikte aufzulösen.
Das Schöne daran ist die einfache Nutzung und die übersichtliche Darstellung
im Terminal, der zunächst erstmal nur die benötigten und relevanten Zeilen anzeigt.
Zusätzliche Zeilen lassen sich allerdings mit wenigen Tastendrücken anzeigen.
Aussehen tut dies etwa so:
„fac“ ist in Go geschrieben und kann über go auch heruntergeladen werden:
$ go get github.com/mkchoi212/fac
Die Binärdatei liegt anschließend unter ~/go/bin/fac. Den Pfad sollte man dann
entweder zu seiner $PATH Variable hinzufügen oder direkt aufrufen. Leider
gibt es noch keine Unterstützung als Git Mergetool. Dazu existiert aber ein
Issue.
Natürlich gibt es auch andere Mergetools, die man verwenden kann. Mir gefällt in
diesem Fall die einfache Benutzung und die geringe Einstiegshürde, die das Tool
mit sich bringt. Verbesserungspotenzial ist da natürlich auch da, da eine schönere
Diff-Ansicht des Konfliktes begrüßenswert wäre.
Wer häufiger mit Git arbeitet und dort auf Merge-Konflikte stößt, hat bei größeren
Konflikten keinen sonderlich großen Spaß diese aufzulösen. Häufig bietet es
sich dabei an, ein Mergetool zu verwenden, der einem die Arbeit erleichtern soll.
Einige Mergetools existieren für die Kommandozeile, andere auch als grafische
Tools.
Kürzlich bin ich auf das kleine Tool „fac“ gestoßen, was
kurz für „Fix All Commits“ steht. „fac“ ist ein in Go geschriebenes CUI, also
ein Commandline User Interface, um Merge-Konflikte aufzulösen.
Das Schöne daran ist die einfache Nutzung und die übersichtliche Darstellung
im Terminal, der zunächst erstmal nur die benötigten und relevanten Zeilen anzeigt.
Zusätzliche Zeilen lassen sich allerdings mit wenigen Tastendrücken anzeigen.
Aussehen tut dies etwa so:
„fac“ ist in Go geschrieben und kann über go auch heruntergeladen werden:
$ go get github.com/mkchoi212/fac
Die Binärdatei liegt anschließend unter ~/go/bin/fac. Den Pfad sollte man dann
entweder zu seiner $PATH Variable hinzufügen oder direkt aufrufen. Leider
gibt es noch keine Unterstützung als Git Mergetool. Dazu existiert aber ein
Issue.
Natürlich gibt es auch andere Mergetools, die man verwenden kann. Mir gefällt in
diesem Fall die einfache Benutzung und die geringe Einstiegshürde, die das Tool
mit sich bringt. Verbesserungspotenzial ist da natürlich auch da, da eine schönere
Diff-Ansicht des Konfliktes begrüßenswert wäre.
Nach längerer Zeit folgt an dieser Stelle mal wieder eine Buchrezension. In
diesem Artikel wird das Buch „Machine Learning mit Python“ mit dem Untertitel
„Das Praxis-Handbuch für Data Science, Predictive Analytics und Deep Learning“
vom Autor Sebastian Raschka besprochen. Erschienen ist das Buch beim mitp Verlag.
Zu dem handelt es sich bei diesem Buch um eine Übersetzung aus dem Englischen.
Hinweis: Der mitp Verlag stellte mir für die Rezension ein Rezensionsexemplar
frei zur Verfügung. Das Buch erschien in der deutschen Übersetzung bereits
am 30. November 2016, am 22. Dezember 2017 folgt dann schon die zweite Auflage,
in dem der Fokus um TensorFlow erweitert wurde. Diese Rezension richtet sich
explizit auf die erste Auflage des Buches. Genannte Kritik-Punkte können
durchaus korrigiert bzw. verbessert worden sein.
Was steht drin?
Das Buch unterteilt sich in 13 Kapiteln, die insgesamt 424 Seiten umfassen. Das
Buch beginnt zunächst mit einem in das maschinelle Lernen, dabei wird auf die
drei verschiedenen Arten eingegangen und beispielhaft erläutert, sowie in die
Notation und Terminologie in dem Fachbereich eingegangen. Im zweiten Kapitel
folgt direkt schon die erste Übung, in der ein Lernalgorithmus programmiert
und erläutert wird, der für die Klassifizierung trainiert wird. Weiter geht
es im dritten Kapitel über die Verwendung von scikit-learn, welches die
Bibliothek ist, die in diesem Buch verwendet wird, um Machine Learning
Algorithmen zu implementieren. Die ersten Kapitel setzten noch auf vorgefertigte
Datensätze, die man nicht selbst ermitteln musste. In Kapitel 4 und 5 geht es
daher um die Datenvorverarbeitung und die Datenkomprimierung, damit man das in
den selbst geschriebenen Klassifizierern verwenden kann.
Je weiter man in dem Buch liest, desto tiefer gehen auch die Themen, so werden
in den darauf folgenden Kapiteln Hyperparameter-Abstimmung und die Kombination
verschiedener Modelle thematisiert. Das achte Kapitel führt wiederum in das
Thema des Natural Language Processings ein, wo erklärt wird, wie man
Stimmungsanalysen ableiten kann.
Das Buch führt aber auch in die Praxis ein, denn die bisherigen Kapitel
erläuterten nur an Hand von Skripten, die bei jedem Lauf von vorne aus den
Daten gelernt haben. Im neunten Kapitel wird exemplarisch gezeigt, wie man eine
Web-Anwendung implementieren kann, welches die zuvor implementierten
Algorithmen nutzt und während der Nutzung auch weiter lernt und anwendet. Die
übrigen Kapitel umfassen weiterhin eine Regressionsanalyse, Clusteranalyse, die
Verwendung neuronale Netze zur Bildererkennung, sowie neuronale Netze mit der
Bibliothek Theano.
Kritik
Das Buch ist sehr umfangreich und bietet sehr viele Informationen zu dem doch
großen Bereich des Machine Learnings. Der größte Kritik-Punkt meinerseits ist,
dass es nicht wirklich einsteigerfreundlich ist. Für viele Themen sind zwar
Beschreibungen und Erklärungen da, allerdings sind diese zumeist relativ knapp
und nicht immer ganz nachvollziehbar. Das Buch ist zwar schon relativ
umfangreich, doch könnte dies einen Tick umfangreicher sein, um vor allem
Einsteiger abzuholen. In dem Fall müssen für einige Themenbereiche nämlich noch
zusätzliche Quellen bezogen werden, um auch die Gedankengänge der Umsetzung
besser nachvollziehen zu können. Auch Erfahrung im Umgang mit Python ist sehr
vorteilhaft. Wer keine Erfahrung in beiden Gebieten mitbringt, wird mit dem
Buch eher nicht glücklich.
Hier sollte man allerdings noch beachten, dass die zweite Auflage erschienen
ist, die nicht nur scikit-learn verwendet, sondern auch tiefer in die populäre
Bibliothek TensorFlow einführt. Das Buch ist in der zweiten Auflage somit auch
noch umfassender geworden.
Unabhängig davon gilt es hervorzuheben, dass das Buch für die Zielgruppe von
Personen mit Erfahrung mit Python und den Grundzügen von Machine Learning sehr
viele Informationen und praxisrelevante Informationen vermittelt. Dass es eine
Übersetzung aus dem Englischen ist, merkt man dem Buch nicht an. Man sieht auch
sehr deutlich, dass der Autor viele Kenntnisse und Erfahrung in dem Bereich hat,
da er an vielen Stellen auf mögliche Probleme eingeht und passende Lösungen
parat hat.
Nach längerer Zeit folgt an dieser Stelle mal wieder eine Buchrezension. In
diesem Artikel wird das Buch „Machine Learning mit Python“ mit dem Untertitel
„Das Praxis-Handbuch für Data Science, Predictive Analytics und Deep Learning“
vom Autor Sebastian Raschka besprochen. Erschienen ist das Buch beim mitp Verlag.
Zu dem handelt es sich bei diesem Buch um eine Übersetzung aus dem Englischen.
Hinweis: Der mitp Verlag stellte mir für die Rezension ein Rezensionsexemplar
frei zur Verfügung. Das Buch erschien in der deutschen Übersetzung bereits
am 30. November 2016, am 22. Dezember 2017 folgt dann schon die zweite Auflage,
in dem der Fokus um TensorFlow erweitert wurde. Diese Rezension richtet sich
explizit auf die erste Auflage des Buches. Genannte Kritik-Punkte können
durchaus korrigiert bzw. verbessert worden sein.
Was steht drin?
Das Buch unterteilt sich in 13 Kapiteln, die insgesamt 424 Seiten umfassen. Das
Buch beginnt zunächst mit einem in das maschinelle Lernen, dabei wird auf die
drei verschiedenen Arten eingegangen und beispielhaft erläutert, sowie in die
Notation und Terminologie in dem Fachbereich eingegangen. Im zweiten Kapitel
folgt direkt schon die erste Übung, in der ein Lernalgorithmus programmiert
und erläutert wird, der für die Klassifizierung trainiert wird. Weiter geht
es im dritten Kapitel über die Verwendung von scikit-learn, welches die
Bibliothek ist, die in diesem Buch verwendet wird, um Machine Learning
Algorithmen zu implementieren. Die ersten Kapitel setzten noch auf vorgefertigte
Datensätze, die man nicht selbst ermitteln musste. In Kapitel 4 und 5 geht es
daher um die Datenvorverarbeitung und die Datenkomprimierung, damit man das in
den selbst geschriebenen Klassifizierern verwenden kann.
Je weiter man in dem Buch liest, desto tiefer gehen auch die Themen, so werden
in den darauf folgenden Kapiteln Hyperparameter-Abstimmung und die Kombination
verschiedener Modelle thematisiert. Das achte Kapitel führt wiederum in das
Thema des Natural Language Processings ein, wo erklärt wird, wie man
Stimmungsanalysen ableiten kann.
Das Buch führt aber auch in die Praxis ein, denn die bisherigen Kapitel
erläuterten nur an Hand von Skripten, die bei jedem Lauf von vorne aus den
Daten gelernt haben. Im neunten Kapitel wird exemplarisch gezeigt, wie man eine
Web-Anwendung implementieren kann, welches die zuvor implementierten
Algorithmen nutzt und während der Nutzung auch weiter lernt und anwendet. Die
übrigen Kapitel umfassen weiterhin eine Regressionsanalyse, Clusteranalyse, die
Verwendung neuronale Netze zur Bildererkennung, sowie neuronale Netze mit der
Bibliothek Theano.
Kritik
Das Buch ist sehr umfangreich und bietet sehr viele Informationen zu dem doch
großen Bereich des Machine Learnings. Der größte Kritik-Punkt meinerseits ist,
dass es nicht wirklich einsteigerfreundlich ist. Für viele Themen sind zwar
Beschreibungen und Erklärungen da, allerdings sind diese zumeist relativ knapp
und nicht immer ganz nachvollziehbar. Das Buch ist zwar schon relativ
umfangreich, doch könnte dies einen Tick umfangreicher sein, um vor allem
Einsteiger abzuholen. In dem Fall müssen für einige Themenbereiche nämlich noch
zusätzliche Quellen bezogen werden, um auch die Gedankengänge der Umsetzung
besser nachvollziehen zu können. Auch Erfahrung im Umgang mit Python ist sehr
vorteilhaft. Wer keine Erfahrung in beiden Gebieten mitbringt, wird mit dem
Buch eher nicht glücklich.
Hier sollte man allerdings noch beachten, dass die zweite Auflage erschienen
ist, die nicht nur scikit-learn verwendet, sondern auch tiefer in die populäre
Bibliothek TensorFlow einführt. Das Buch ist in der zweiten Auflage somit auch
noch umfassender geworden.
Unabhängig davon gilt es hervorzuheben, dass das Buch für die Zielgruppe von
Personen mit Erfahrung mit Python und den Grundzügen von Machine Learning sehr
viele Informationen und praxisrelevante Informationen vermittelt. Dass es eine
Übersetzung aus dem Englischen ist, merkt man dem Buch nicht an. Man sieht auch
sehr deutlich, dass der Autor viele Kenntnisse und Erfahrung in dem Bereich hat,
da er an vielen Stellen auf mögliche Probleme eingeht und passende Lösungen
parat hat.
Eigentlich lasse ich von Early-Access-Spielen die Finger. Eigentlich. Letztes Wochenende habe ich aber diese Regel mal wieder gebrochen und mit neben Battalion 1944 auch Tannenberg gekauft. Letzteres läuft direkt unter Linux.
Tannenberg ist an der Ostfront im Ersten Weltkrieg angesiedelt. Hauptsächlich spielt man den Modus “Maneuver”. Hier ist das Spielprinzip recht einfach. Es gibt mehrere Karten die in diverse Sektoren unterteilt sind. Zwei Teams mit insgesamt maximal 64 Spielern (bei Bedarf werden diese von Bots aufgefüllt) versuchen nun diese Sektoren zu erobern und zu halten. Klingt einfach? Ist es aber nicht.
Im Gegensatz zu anderen Shootern beißt man in der Regel nach einem Treffer ins Gras. Vor allem als Neueinsteiger kann dies richtig nerven da man während einer Runde teilweise mehr stirbt als bei einer Lanparty an einem ganzen Wochenende. Der Umgang mit den Waffen erfordert auch etwas Einarbeitungszeit. Scheinbar waren diese im Ersten Weltkrieg nicht gerade präziese und das haben die Entwickler wohl berücksichtigt. Zudem sind die Magazine oft sehr klein und das Nachladen dauert oft ewig. Wäre dies nicht schon genug Stress, kommen dann noch so nette Sachen wie Mörser- und Giftgasangriffe dazwischen. Für letzteres kann man sich zwar mit einer Gasmaske schützen, allerdings kann man sich diese oft nicht schnell genug aufsetzen. Kurz gesagt man stirbt schnell und oft und steht eigentlich immer unter Strom. Normalerweise würde ich daher die Finger von dem Spiel lassen. Aber irgendwie hat es mich am vergangenen Samstag mehrere Stunden gefesselt.
Aber trotzdem merkt man deutlich, dass es ein Early-Access-Spiel ist. Mit der Grafik lässt sich kein Preis gewinnen (vermutlich auch nicht wenn das Spiel fertig ist), trotzdem entsteht eine gute Athmosphäre. Die Vertonung hingegen finde ich sehr gelungen. Die Übersetzung der Texte zumindest die in die deutsche Sprache ist, sagen wir mal unfertig, bringt aber auch etwas Witz ins Spiel (z. B. auf einen Kontrollpunkt klicken um zu laichen). Die Hardwareanforderungen sind alles in allem nicht gerade hoch. Empfohlen werden 8 GB RAM und eine Grafikkarte mit 4 GB.
Von den Spielern wurde ich, bis auf wenige Ausnahmen, sehr positiv überrascht. Alles in allem ein freundlicher Haufen, der sich auch nicht zu schade ist einzelnen Spielern oder allgemein dem gegnerischen Team zu gratulieren. Der Versuch mancher mit zum Beispiel mit einem preußischen Dialekt zu sprechen, hat auch für einige Lacher gesorgt. Vor allem wenn diese der deutschen Sprache kein Stück mächtig sind.
Muss man nun Tannenberg unbedingt spielen? Sicher nicht. Ich bereue es aber auch nicht, knapp 18 Euro dafür bezahlt zu haben und werde am Wochenende sicher wieder ein paar Runden spielen. Wer sich für das Spiel interessiert kann sich die offizielle Seite bzw. die Seite bei Steam anschauen.
Seit längerem bin ich auf der Suche nach einem guten Desktop-Client, der sowohl Twitter als auch die freie alternative GnuSocial möglichst umfänglich unterstützt. Leider gibt es da kaum Lösungen für. Auf meinem Android-Smartphone bin ich mit Twidere sehr zufrieden. Da lag die Idee nahe zu versuchen Twidere auf meinem Desktop zu benutzen.
Dank ChromeOS ist es seit längerem mit dem Chrome-Browser möglich Android-Apps auf fast allen Plattformen im „Testmodus“ auszuführen. Genau hier setzen die beiden Erweiterungen ARChon Runtime und ARC Welder an, die diesen Prozess sehr vereinfachen. Zunächst müsst ihr allerding den Chrome Webbrowser auf eurem System installieren. Ubuntuusers hält hier wie für so viele Programme im Wiki eine ausführliche Anleitung bereit.
Wenn ihr Chrome bei euch installiert habt, dann könnt ihr zunächst der Anleitung von tricksuniversity folgen. Ich zähle hier nur die entsprechenden Schritte auf. Die Details findet ihr in der mit Screenshots ausgestatteten detaillierten Anleitung.
Hier verlassen wir die Anleitung zunächst für einen kurzen Hinweis: Beim ersten Start von ARC Welder bittet euch die Anwendung um einen Ort mit Lese- und Schreibzugriff. Hier solltet ihr einen Pfad wählen, der keine Sonderzeichen (Umlaute, Leerzeichen, Punkte) enthält. Letzteres ließ mich mehrmals ins Stocken kommen. Am besten legt ihr euch einen Unterordner arc in eurem home-Verzeichnis an (also ~/arc bzw /home/user/arc).
Abschließend müsst ihr euch noch das APK von Twidere besorgen. Ihr findet das unter den Releases auf der GitHub-Seite des Projektes. Speichert diese auf eurem Rechner und folgt den letzten Punkten der Anleitung von tricksuniversity.
Über das +-Zeichen fügt ihr die APK hinzu und wählt die Einstellung entsprechend eurer Bedürfnisse. Bei mir haben die vorgeschlagenen Standard-Einstellungen auf Anhieb funktioniert. Nun startet Twidere in einem neuen Fenster und ihr könnt es mit euren Accounts verknüpfen. Die Bedienung mit der Maus ist manchmal etwas unintuitiv, da die App für Finger-Wisch-Bedienung und nicht für die Maus entwickelt wurde. Mit etwas Gewöhnung gelingt die Bedienung allerdings immer leichter.
Im Maximierten Modus (Fenster Bildschirm-füllend) ist es manchmal schwer die Kanten gut zu treffen. Ich benutze Twidere deswegen nie ganz Maximiert. Das erleichert das Interagieren mit den Schaltflächen durchaus. Leider wird das Tastatur-Schema eurer Ubuntu-Installation nicht automatisch erkannt und verwendet. Statt dessen wird von einem US-Layout ausgegangen. Das ist etwas umständlich. Bisher habe ich hierfür noch keine Lösung gefunden.
Mein Mailserver verfügt nicht nur über eine, sondern über zwei IPv4-Adressen. Dadurch kann ich die erste Adresse fürs Management nutzen und die andere für die Kommunikation zwischen Mailservern und -clients. Im DNS ist als MX-Record ausschließlich die Mail-IP gesetzt. Das ist durchaus sinnvoll (Firewall, Flexibilität,…), führt aber insbesondere beim empfohlenen Einsatz des Sender Policy Frameworks zu einem Problem, da Postfix zwar auf der richtigen Mail-IP lauscht, aber möglicherweise über die Management-IP Mails verschickt. Als Folge failt der SPF-Check und die Mail wird entsprechend behandelt.
Nun kann man die Management-IP als erlaubte Adresse im SPF-TXT-Record setzen, so richtig schön ist das aber nicht.
Die Lösung sind die Optionen smtp_bind_address (IPv4) und smtp_bind_address6 (IPv6). In der main.cf gesetzt führen Sie dazu, dass Postfix zum Versenden diese Adressen nutzt und der SPF-Check erfolgreich verläuft.
Für IPv6 mag das sogar noch interessanter sein, da viele Provider dem Server einen /64er-Block zur Verfügung stellen und mit der Option Mails auf einer Adresse abgefertigt werden können.
Zwei Jahre sind seit dem letzten Release vergangen. Letztes Wochenende fand ich nun endlich die Zeit, mich wieder mit dem Projekt Raspi-SHT21 zu befassen. Herausgekommen ist die BETA der Version 2.
Bei mir daheim läuft die neue Version bisher stabil. Da ausführliche Tests fehlen, habe ich sie als BETA markiert. Falls ihr Fehler findet, Fragen habt oder der Meinung seid, dass noch etwas fehlt (Code, Doku, Spendenbutton), eröffnet bitte einen GitHub-Issue oder hinterlasst mir hier einen Kommentar.
In Zukunft soll das Projekt um Remote-Messstationen erweitert werden. Der Raspberry Pi dient dabei als Zentrale zur Speicherung und Visualisierung der Messdaten. Diese werden zukünftig nicht mehr nur ausschließlich vom direkt angeschlossenen SHT21-Sensor geliefert, sondern auch von weiteren Sensoren, die ihre Daten per WLAN übertragen. Sobald es etwas zu zeigen gibt, werde ich in diesem Blog darüber berichten.
E-Mail Verschlüsselung ist nach wie vor ein sehr problematischer Bereich. Gegenwärtig sind fast alle mobilen Messenger sicherer als die herkömmliche E-Mail - selbst wenn der Besitzer des Messengers Facebook, Apple oder Microsoft heißt. Die technischen Grundlagen zur Mailverschlüsselung sind über 20 Jahre alt, nur durchsetzen konnte sie sich nie. Hinzu kommt die Konkurrenz von S/MIME und PGP, wodurch Interessenten zwei unterschiedliche Systeme parallel betreiben müssen.
S/MIME und PGP sind älter als die Konkurrenz zwischen Linux und Windows und beide sind standardisiert. OpenPGP nutzt das in PGP 5 standardisierte Format, festgelegt in RFC 4880. S/MIME ist in RFC 2633 spezifiziert. Neben technischen Unterschieden ist das größte Unterscheidungsmerkmal das Schlüsselsystem. PGP basiert auf einem "Web of Trust" genannten Verfahren, bei dem vertrauenswürdige Dritte Schlüssel zertifizieren können. S/MIME basiert hingegen auf einem hierarchischen Zertifikatssystem, wie man es - etwas simplifiziert ausgedrückt - auch von den TLS-Zertifikaten (HTTPS) kennt.
Interessanterweise wird dieser Dualismus primär durch die Open Source Gemeinschaft am Leben erhalten. Normalerweise ist es eben jene Gemeinschaft, die Sonderwege proprietärer Hersteller ablehnt und auf freien Formaten beharrt (siehe z.B. die Kontroverse um OASIS und OOXML). Bei S/MIME vs. PGP muss man aber eigentlich konstatieren, dass ersteres sich längst flächendeckend durchgesetzt hat. Alle verbreiteten Betriebssysteme (Windows, macOS, Linux, iOS, Android) und alle großen Mailclients (Outlook, Apple Mail, Thunderbird, Evolution, KMail) haben S/MIME implementiert. PGP ist hingegen nur bei Linux vorinstalliert und noch nicht einmal Thunderbird unterstützt dies ohne Addon.
Maßgeblich liegt dies an der Ablehnung der Zertifikatshierarchie durch die Open Source-Gemeinschaft. Das "Web of Trust"-Verfahren passt hier halt deutlich mehr zum Gemeinschaftsgedanken. Technisch gesehen sind beide Verfahren sicher und die verbreitete Implementierung von S/MIME zeigt, dass es hier auch keine proprietären Hürden gibt oder das Protokoll zu schwer umzusetzen ist.
Dieser Sonderweg der Open Source Gemeinschaft könnte man als bedeutungslos abtun. Durch die starke Vernetzung von Datenschutz-Aktivisten und Open Source-Gemeinschaft basieren Empfehlungen zur E-Mail Verschlüsselung jedoch fast immer auf PGP - ein System, das nirgendwo vorinstalliert ist. Dies erhöht massiv die Einstiegsschwelle in das Thema Mailverschlüsselung. Ein Bereich, der durch komplexe Verfahren mit öffentlichen und privaten Zertifikaten, sowie viel manueller Tätigkeit beim Austausch, sowieso nicht leicht zu durchdringen ist.
Die große Hürde beim S/MIME Zertifikatssystem sind die, für Außenstehende, undurchsichtigen Zertifizierungsstellen und vielfältigen, teils kostenpflichtigen, Angeboten. Let'S Encrypt hat im TLS-Bereich jedoch gezeigt, dass man eine zuverlässige, transparente und kostenlose Zertifizierungsstelle erschaffen kann, die sich sehr schnell durchsetzt. Was es braucht ist ein ähnliches System für S/MIME - und die Unterstützung durch die Open Source-Gemeinschaft, die ihr gescheitertes GnuPG endlich aufgeben muss.
Die Themen der Woche vom 29. Januar bis 04. Februar 2018, diesmal im Schnelldurchlauf.
Wochengeschehen
Top-Thema: LibreOffice 6.0
Gut zwei Jahre ist letzte Major-Release von LibreOffice her. Am 31. Januar 2018 hat The Document Foundation nun die Version 6.0 der freien Bürosuite veröffentlicht. LibreOffice entstand 2011 aus einem Fork von OpenOffice und wurde in Version 3.3 erstmals veröffentlicht, da die Versionsgeschichte von OpenOffice übernommen wurde.
In der neuen Version wurde die neue, noch experimentelle Navigationsleiste “Notebookbar” verbessert und verfügt nun über zwei Layouts. Viele Dialoge wurden wie der Sonderzeichen- oder Anpassungsdialog verbessert und neue Dialoge kamen für Formulare hinzu. Bilder können erstmals komplett in jedem Winkel rotiert werden. Calc wird um die Funktionen SEARCHB, FINDB and REPLACEB erweitert, die aus dem ODF 1.2-Standard entstammen und somit konform gehen. Impress, die Präsenationsanwendung verwendet nun standardmäßig das 16:9-Format für neue Folien und wurde um 10 Vorlagen bereichert. Die Hilfeseite wird nun aus dem Internet über ein neues System geladen. Ist eine PGP-Implementation auf dem System vorhanden, können nun ODF-Dokumente mit OpenPGP signiert werden.
Diese Woche wird der Schwerpunkt mehr auf den Artikeltipps liegen. Beginnen möchte ich hier mit dem Grund, warum der Wochenrückblick so verspätet kommt: ich hatte gestern eine größere Wartung meines Mailservers. Allen die einen neuen Mailserver auf Debian einrichten wollen, kann ich die tolle Anleitung von Thomas Leister dazu nur ans Herz legen.
Ich habe bereits öfter schon mit der OpenStreetMap gearbeitet und weiß, dass man damit sehr schöne Dinge realisieren kann. Kostprobe gefällig? Deutschlands Orte der Unzugänglichkeit von Hans Hack, präsentiert von seeseekey.net. Thematisch passt das übrigens zum Konzept der Pole der Unzugänglichkeit – für alle, die sich mehr dafür interessieren.
Bild von IO-Images via pixabay / Lizenz: CC0 Creative Commons
Im Frühjahr 2018 ist die Trennung von ownCloud und Nextcloud zwei Jahre her. Anfangs haben viele das schnelle Ende von ownCloud und den Übergang zu Nextcloud vorhergesagt. In einer kürzlich verschickten Pressemitteilung stellt ownCloud klar, dass dem nicht so ist. Ganz im Gegenteil: Man konnte im vergangenen Jahr ordentlich zulegen und Subscriptionen von vielen Unternehmen einwerben.
Nextcloud veröffentlicht leider keine Zahlen (oder die Suchmaschine meiner Wahl wollte sie mir nicht zeigen?!), daher fehlt der direkte Vergleich. Funktional geben sich beide Projekte nicht viel, auch wenn Nextcloud medienwirksam andauernd neue Versionen veröffentlicht (siehe auch: Kommentar: Warum ownCloud statt Nextcloud?)
Die Zahlen von ownCloud passen aber zu meinen persönlichen Erfahrungen. In der, gewohnt gut informierten und an Forks gewöhnten Linux-Community vollzog sich der Wechsel schnell, aber Open Source-Entwickler unterschätzen oft die Wirkung einer etablierten Marke. OwnCloud war bereits fest etabliert, als Nextloud sich abspaltete und letzteres konnte diese Position bisher nicht übernehmen. Das Verhältnis OpenOffice zu LibreOffice zeigt ja sogar wie schwer dies ist, selbst wenn der Fork funktional deutlich überlegen sein sollte. Nextcloud hat aber gegenüber ownCloud nicht viel zu bieten, tut sich also noch schwerer mit der Durchsetzung.
Bild von stevepb via pixabay / Lizenz: CC0 Creative Commons
Im Jahr 2018 veröffentlicht nicht nur Ubuntu seine neue LTS Version (Kubuntu 18.04 LTS - Ein Ausblick), sondern das openSUSE Projekt hat nun ebenfalls die Betaphase für die Version 15 seiner stabiles LTS-Variante "Leap" eingeleitet. Die nun kommende Version 15 ist erst die zweite Hauptversion des Leap-Zweiges. Die letzte Hauptversion mit der Versionsnummer 42 stammt noch von 2015 (siehe: openSUSE Leap 42.1 im Test).
Leap und Tumbleweed sind die komplementären Veröffentlichungen von openSUSE. Während Tumbleweed als Rolling-Release Distribution konzipiert ist und die fortlaufenden Entwicklungen in der Linux-Communty widerspiegelt, ist Leap auf Stabilität ausgerichtet. Jede Hauptversion von Leap wird ca. 3 Jahre mit Updates versorgt. Die aktuell veröffentlichte Minorversion mindestens 18 Monate lang. Das System von Haupt- und Minorversionen kennt man von anderen Enterprise-Distributionen wie RHEL/CentOS.
Große Veränderungen erfolgen immer nur mit den Hauptversionen, während die Minorversionen lediglich der Produktpflege dienen und selektive Updates einspielen. Leap 42.2 und Leap 42.3 lieferten z.B. KDE Plasma in der LTS-Version 5.8 aus. Lediglich die Programmsammlung KDE Applications erhielt ein Versionsupgrade zwischen den Versionen.
Bedingt durch die Entscheidung der SUSE GmbH die Versionsnummern 13 und 14 für die Enterprise Version zu überspringen nutzt das openSUSE Projekt diese Gelegenheit und harmonisiert die Versionsnummern mit der Basis. Auf Leap 42 folgt daher Leap 15.
Versionen
Basisversionen
OpenSUSE Leap übernimmt, wie auch die Vorgängerversion, einen großen Kernbestand an Paketen von SUSE Linux Enterprise 15. Die neue Version basiert daher auf dem bereits recht abgehangenen Kernel 4.12. Was für die Besitzer brandaktueller Hardware eventuell problematisch ist, dürfte sich für eingefleischte Leap-Anwender als Fortschritt erweisen, immerhin nutzt man bisher noch Kernel 4.4 in Leap 42.3. Hinzu kommen Mesa 17.2, GCC 7 und eine moderne Wayland-Implementierung.
Desktop
Im Desktopbereich hebt man die Version des Standarddesktops auf KDE Plasma 5.12 an, der sich aktuell ebenfalls in der Betaphase befindet und die nächste LTS-Version des KDE Projekts ist. Hinzu kommen GNOME 3.26, MATE 1.18, Xfce 4.12, sowie LXDE und eine Vorschau auf LXQt. OpenSUSE Leap folgt also dem bewährten Prinzip aktuelle Desktopversionen mit einer LTS-Basis zu verknüpfen.
Programme
Das Paket wird komplettiert durch KDE Applications in der aktuellen Version 17.12, LibreOffice 6 und viele weitere Programme. Die Paketquellen sind nicht so umfangreich wie bei Debian und Ubuntu, aber es gammeln durch den Releaseprozes von openSUSE auch deutlich weniger ungepflegte Programmleichen in diesem herum.
Neuerungen
Die Veröffentlichung von openSUSE Leap 15 wird, gemessen an der aktuellen Betaversion, keine umstürzenden Neuerungen enthalten. Abgesehen von den angehobenen Versionsnummern in allen Bereichen gibt es moderate Anpassungen am Design. Manche Upstream-Neuerung wie die neuen KDE Systemeinstellungen hat man sogar standardmäßig abgeschaltet. Unklar ist noch in welchem Umfang Wayland eingesetzt wird. Bei der SLE-Basis hat SUSE sich entschieden standardmäßig auf Wayland umzusteigen. Bei der deutlich größeren Desktopauswahl von openSUSE wäre dies sowieso nur für KDE Plasma und die GNOME Shell möglich. Alle anderen Desktopumgebungen haben noch keine funktionsfähigen Wayland-Implementierungen.
Installationsroutine
Die Installationsroutine folgt den gewohnten SUSE-Richtlinien. Auffällig ist lediglich die neue Routine für die Partitionierung.
Hier hat man die Informationen deutlich reduziert und schafft dadurch mehr Übersichtlichkeit. Zusätzliche Bereiche wie Btrfs-Subvolumes sind beispielsweise standardmäßig ausgeblendet, was die Aufmerksamkeit auf die echten Partitionen lenkt.
Ebenfalls neu ist die Routine für ein "Geführtes Setup".
In einem ersten Schritt kann man sich sehr leicht für ein verschlüsseltes System entscheiden, was sehr erfreulich ist. OpenSUSE hat es hier schon immer viel leichter gemacht ein vollverschlüsseltes System einzurichten, als z.B. Ubuntu, aber dies ist nochmal ein Fortschritt.
Im nächsten Schritt kann man sich zusätzlich noch für ein Dateisystem entscheiden. Zur Auswahl stehen ext2/3/4, sowie Btrfs und XFS. Letztere beiden sind nach wie vor Standard für die root- und home-Partition.
Programmauswahl
Frühere Versionen von openSUSE zeichneten sich durch eine teils widersprüchliche Standard-Programmauswahl aus. Teilweise auch unabsichtlich durch zirkuläre Abhängigkeiten der Pakete. Hier hat man deutlich aufgeräumt. Noch immer liefert openSUSE einen sehr umfangreichen Desktop aus. So sind neben den obligatorischen KDE Programmen auch solche wie LibreOffice, GIMP, DigiKam etc. pp. vorausgewählt. Im Unterschied zu Debian oder Ubuntu kann man hier aber in der Installationsroutine bereits viel abwählen, wenn man lieber einen minimalistischen Desktop einrichten möchte.
Doppelungen von Programmen oder gar die Nachinstallation eines anderen Desktops über Abhängigkeiten erfolgen aber nicht mehr.
KDE hat zudem den endgültigen Abschied von KDE SC 4 vollzogen, weshalb die KDE Applications nun durchweg auf Qt 5 und den KDE Frameworks basieren. Etwaige Fehlfunktionen oder Unstimmigkeiten sind somit nun auch behoben.
Fazit
OpenSUSE Leap läuft bereits jetzt sehr stabil und repräsentiert die Upstream-Fortschritte der vergangenen Jahre. Letzte Unstimmigkeiten werden in der Betaphase sicher noch beseitigt. Leap bietet weiterhin einen konventionellen Linux-Desktop ohne ideologischen Überhang wie bei den puristischen KDE oder GNOME-Implementieren, wie sie z.B. KaOS oder Fedora ausliefern.
Trotz der abgehangenen Basis schafft man den Sprung auf zeitgemäße Technologien wie Wayland.
OpenSUSE Leap hat bei mir sowohl als Server, wie auch für Desktopsysteme und virtuellem Maschinen einen festen Platz - Leap 15 wird daran nichts ändern, sondern eher die ein oder andere Migration anstoßen.
Synology Diskstations stellen Anwendungen bereit, um Bilder, Musik und Videos verwalten zu können. Dies sind im einzelnen
die Photo Station,
die Audio Station und
die Video Station.
Damit die Medien in den jeweiligen Anwendungen angezeigt werden können, müssen diese zuvor indiziert werden. Die Indizierung erfolgt automatisch, wenn Medien über die entsprechende Anwendung hinzugefügt werden. Fügt man sie jedoch auf anderem Wege hinzu, z.B. durch rsync, startet die Medienindizierung nicht und die Medien können in der jeweiligen Anwendung nicht wiedergegeben werden.
Die Benutzeroberfläche „DSM“ bietet lediglich die Möglichkeit, ganz allgemein eine Medienindizierung zu starten. Dabei werden jedoch sämtliche Medien neu indiziert und nicht nur die neu hinzugefügten. Je nach Umfang dauert die Indizierung mehrere Stunden bis Tage. Es gibt jedoch eine Möglichkeit, die Indizierung manuell zu starten und dabei auf ein einzelnes Verzeichnis zu beschränken.
Dazu meldet man sich per SSH an der Diskstation an und führt folgendes Kommando aus: /usr/syno/bin/synoindex -R /Pfad/zum/Verzeichnis/
New Tab Override ist eine Erweiterung zum Ersetzen der Seite, welche beim Öffnen eines neuen Tabs in Firefox erscheint. Die beliebte Erweiterung mit mehr als 150.000 aktiven Nutzern ist nun in Version 12.0 mit weiteren Verbesserungen erschienen.
Was ist New Tab Override?
Seit Firefox 41 ist es nicht länger möglich, die Seite anzupassen, welche beim Öffnen eines neuen Tabs erscheint, indem die Einstellung browser.newtab.url über about:config verändert wird. Da diese Einstellung – wie leider viele gute Dinge – in der Vergangenheit von Hijackern missbraucht worden ist, hatte sich Mozilla dazu entschieden, diese Einstellung aus dem Firefox-Core zu entfernen. Glücklicherweise hat Mozilla nicht einfach nur die Einstellung entfernt, sondern gleichzeitig auch eine neue API bereitgestellt, welche es Entwicklern von Add-ons erlaubt, diese Funktionalität in Form eines Add-ons zurück in Firefox zu bringen.
New Tab Override war das erste Add-on, welches diese Möglichkeit zurückgebracht hat, und ist damit das Original. Mittlerweile hat New Tab Override mehr als 150.000 aktive Nutzer, wurde im Dezember 2016 sogar auf dem offiziellen Mozilla-Blog vorgestellt und im Oktober 2017 im Add-on Manager von Firefox beworben.
Bei Verwendung der Option, eine lokale Datei als neuen Tab zu verwenden, wird nun der Inhalt des <title>-Elements aus dem Dokument extrahiert und als Seitentitel für den neuen Tab verwendet.
Die Option, den Fokus auf die Webseite statt auf die Adressleiste zu legen, steht nun auch für die leere Seite about:blank zur Verfügung. Dies kann vor allem im Zusammenspiel mit anderen Add-ons wie Vimium-FF nützlich sein.
Die Hintergrundfarbe der Einstellungsseite wurde im CSS nun explizit gesetzt, so dass es zu keinen Darstellungsproblemen kommt, wenn die Firefox-Einstellung browser.display.background_color auf einem Nicht-Standard-Wert steht.
Die russische sowie die chinesische Übersetzung wurden aufgrund von Inaktivität der Übersetzer entfernt. Außerdem wurden wieder sämtliche Abhängigkeiten auf den aktuellen Stand gebracht. Neue Mindestvoraussetzung ist Firefox 58, ältere Firefox-Versionen werden nicht unterstützt.
Ich erstelle recht häufig Screenshots. Nicht nur für diesen Blog, sondern generell um Dinge zu dokumentieren. Mit dem bekannten Tool Shutter konnte ich mich nie anfreunden. Daher habe ich immer das doch sehr beschränkte Gnome-Bildschirmfoto genutzt. Um anschließend Dinge zu markieren, habe ich GIMP genutzt. Ein etwas umständlicher Workflow, an den ich mich aber gewöhnt hatte.
In der c’t 04/2018 wurde ein Werkzeug zum Erstellen von Screenshots unter Linux vorgestellt, das mich sehr neugierig gemacht hat. Es handelt sich um Flameshot.
Das Projekt selbst ist Open Source und auf Github zu finden. Zur Installation unter Ubuntu kann ein inoffizielles Repo von Launchpad eingebunden werden, dem man natürlich vertrauen muss. Von dort kann auch ein .deb Paket direkt heruntergeladen und installiert werden. Arch Nutzer finden Flameshot im AUR.
Nach dem Start nistet sich Flameshot als kleines Tray-Icon in der Leiste des von mir genutzten Cinnamon-Desktops ein. Mit einem Klick auf das Icon können direkt Screenshots von einem ausgewählten Bereich erstellt werden.
Anschließend öffnet Flameshot den Screenshot ohne ihn direkt zu speichern. Hier werden einem eine Vielzahl von Bearbeitungsmöglichkeiten angeboten. So kann man beispielsweise Pfeile oder Linien zeichnen. Elemente zensieren oder mit einem Rahmen hervorheben uvm. Nur eine Möglichkeit Text einzufügen gibt es leider nicht. Das ist allerdings auch eine Funktion die ich nur selten benötige.
Mit Flameshot kann ich Screenshots in einem Arbeitsschritt erstellen für die ich bisher mehrere Schritte und mehrere Programme benötigt habe. Außerdem finde ich das Programm optisch ansprechend. Die Farbe der Buttons lässt sich ändern und passend zum eigenen System gestalten.
Für mich bleibt Flameshot daher weiterhin in der digitalen Werkzeugkiste.
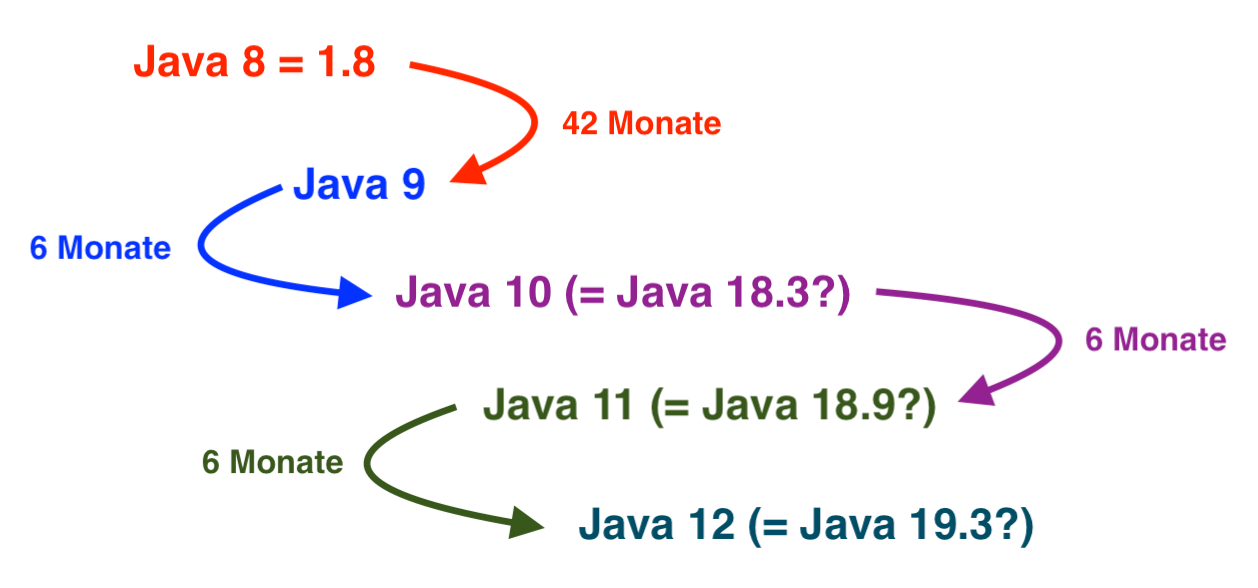
Der Schritt von Java SE 8 hin zu Java SE 9 hat beachtliche dreieinhalb Jahre gedauert. Der Weg war steinig, und das hatte nicht nur mit der eigentlichen Implementierung der Neuerungen zu tun. Bis Java SE 9 im September 2017 endlich ausgeliefert werden konnte, mussten auch viele (firmen-)politische Differenzen ausgeräumt werden.
Aktuelle und zukünftige Java-Versionsnummern
Nun haben wir also Java 9. Allmählich lernen IDEs wie Eclipse richtig mit den Neuerungen umzugehen, insbesondere also mit dem neuen Modulsystem. Langsam kommt Java 9 auf Rechnern in den Labors von Schulen und Universitäten bzw. in den Entwicklungsabteilungen von Firmen an. Noch langsamer etabliert sich OpenJDK 9 unter Linux. (In Ubuntu 17.10 ist OpenJDK 9 nur in der universe-Paketquelle, in Fedora 27 gilt OpenJDK 9 als Technology Preview. Bei den Enterprise-Distributionen ist ohnedies das Warten auf die nächste Version angesagt, oder natürlich die manuelle Installation abseits der offiziellen Paketquellen.)
Aktualisiert: 4.5.2018
Speed kills
3 1/2 Jahre für eine neue Version ist lang, vermutlich zu lang. Was will man also bei Oracle dagegen tun? Einen schnelleren Versionszyklus etablieren. An sich wäre das ja keine schlechte Idee, aber der aktuelle Plan wirkt vollkommen irrwitzig. In Zukunft soll es halbjährlich eine neue Major-Version geben!
Für Java-Freaks ist das super, die müssen nun nicht mehr jahrelang auf neue Features warten. Was fertig implementiert ist, wird in die jeweils aktuelle Version aufgenommen. Hurra!
Die Frage ist aber, ob bzw. wie das Java-Umfeld mit dieser Geschwindigkeit mithalten kann.
Werden alle IDEs nun ebenfalls halbjährlich neue Hauptversionen veröffentlichen?
Wie sollen die neuen Java-Releases so schnell auf alle möglichen Geräte kommen? (Außer Windows und macOS ist ja auch Linux und Android zu berücksichtigen, wo häufig anstelle von Oracle Java die OpenJDK-Version zum Einsatz kommt. In der Regel vergehen einige Monate, bis es hierfür stabile, von den Distributoren offiziell unterstützte Pakete gibt.)
Wie soll in Java entwickelte Software gewartet werden? Halbjährlich neu kompilieren und ausliefern?
Welche Java-Version soll im Unterricht verwendet werden?
Wie sollen gedruckte Dokumentation, Java-Websites, Schulungsunterlagen auf dem aktuellen Stand gehalten werden? (Hier schreibt ein Autor …)
Versionsnummern
Aktuell ist noch nicht einmal klar (siehe diesen heise.de-Artikel), ob die künftigen Java-Versionen nun 10, 11 oder 12 heißen werden, oder ob die von Ubuntu bekannten Nomenklatur übernommen wird, also 18.3, 18.9, 19.3 usw. Update 4.5.2018: beides. Offiziell 10, 11, 12, aber java -version zeigt beide Varianten:
java -version
java version "10" 2018-03-20
Java(TM) SE Runtime Environment 18.3 (build 10+46)
Java HotSpot(TM) 64-Bit Server VM 18.3 (build 10+46, mixed mode)
Angesichts der oben skizzierten Fragen ist das ohnedies nur ein sekundärer Aspekt. Aber die Tatsache, dass noch nicht einmal die Versionsnummer für das in 2 Monaten zu veröffentlichende Java-Release bekannt ist, unterstreicht, wie sehr hier mit der heißen Nadel gestrickt wird.
Wartung und Updates
Aus meiner Sicht die entscheidende Frage ist, in welcher Form Java in Zukunft gewartet wird. Gegenwärtig sieht der Plan anscheinend so aus, dass das jahrelang erwartete Java 9 schon in zwei Monaten obsolet sein wird.
Wer Sicherheits-Updates wünscht, muss dann auf Java 10 umsteigen. (Oder ist es Java 18.3? Na ja, egal.) Und auch wenn Java 10 nur relativ wenig neue Features bieten wird: Kann Oracle wirklich garantieren, dass dieser Versionswechsel ohne Kompatiblitätsprobleme über die Bühne geht?
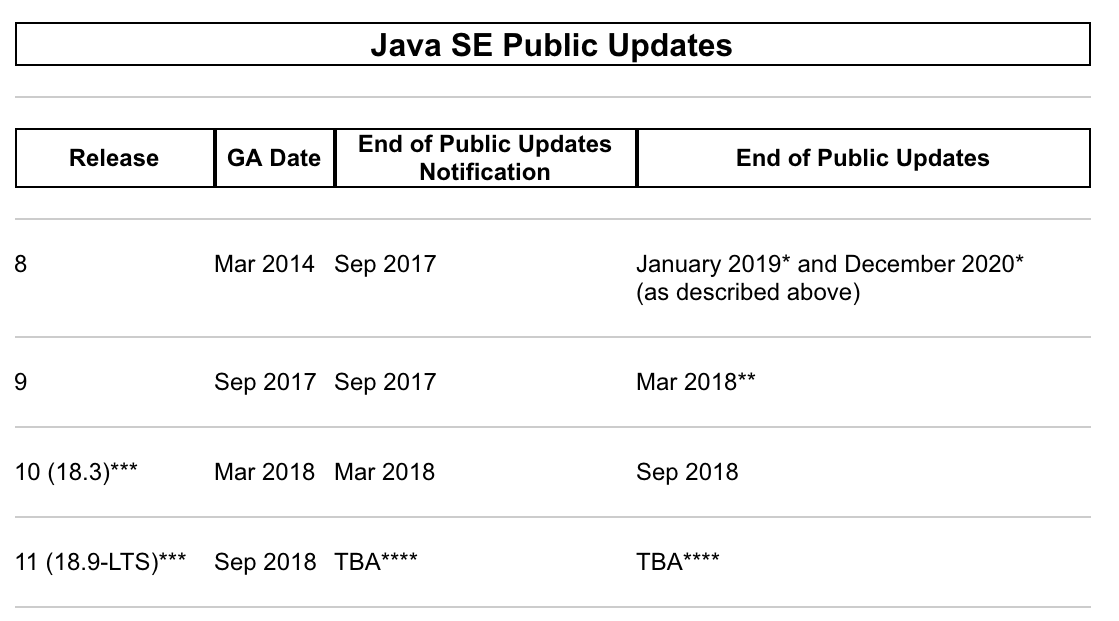
Java 10 wird aber wohl auch nur ein kurzes Leben haben, es soll im Herbst durch Java 11 (Java 18.9) abgelöst werden. Erst diese Version soll eine LTS-Version sein (Long Time Support), die dann etwas länger gepflegt wird. Wie lange, das weiß man bei Oracle offensichtlich selbst noch nicht (siehe die Oracle Java SE Support Roadmap):
Java-Roadmap, Screenshot von http://www.oracle.com/technetwork/java/eol-135779.html, Stand 2.2.2018
Update 4.5.2018: Java 8 soll bis Januar 2019 offizielle Updates erhalten.
Ubuntu plant offensichtlich, mit Ubuntu 18.04 vorerst OpenJDK 10 auszuliefern, im Herbst ein Update auf OpenJDK 11 mitzumachen und dann dabei zu bleiben. Wie andere Linux-Distributionen vorgehen wollen, ist noch unklar. Aber die Begeisterung darüber, dass Java plötzlich so wie Firefox als heiße Kartoffel zu behandeln ist, wird sich in Grenzen halten.
Vermutlich wäre es am einfachsten, Java-Pakete gleich ganz aus Linux-Distributionen herauszuwerfen und auf Docker oder eine andere Container-Technologie zu setzen. Aber über Nacht sind derartig radikale Änderungen natürlich schwer zu realisieren.
Update 4.5.2018: Ubuntu 18.04 hat Java-10-Pakete, die aber den Namen openjdk-11 tragen. Sie werden im Herbst 2018 auf Java 11 aktualisiert. Fedora 28 enthält ebenfalls Java-10-Pakete. Ob es hier ebenfalls im Herbst ein Update auf Java 11 geben wird, ist mir nicht bekannt.
Fazit
Egal, ob für den produktiven Entwicklungsalltag oder für den Unterricht: Eine Programmiersprache muss eine gewisse Stabilität bieten.
Will man die Sprache gleichzeitig halbjährlich um neue Features erweitern, dann geht aus meiner Sicht kein Weg vorbei, eben zwei Zweige anzubieten: einen stabilen Zweig und einen Entwickler-Zweig. (Das Ubuntu-Modell hat sich diesbezüglich bewährt.)
Prinzipiell scheint sich diese Erkenntnis auch bei Oracle durchzusetzen. Aber da hätte man eigentlich erwarten können, dass Java 9 eine stabile Version ist bzw. wird, und dass man das neue Entwicklungsmodell zuerst ein wenig testet, sich in Ruhe die Wartungsmodalitäten für beide Zweige überlegt und diese öffentlich dokumentiert.
Gegenwärtig sieht es aber so aus, als wolle man Java SE mit maximaler Geschwindigkeit gegen die Wand fahren. Wer nach langem Warten im Herbst 2017 auf Java 9 umgestellt hat, kann sich jetzt eigentlich nur veräppelt vorkommen.
Bei Diceware handelt es sich um ein Verfahren mit dem man lange, aber leichter zu merkende Passwörter erstellen kann. Hierzu braucht man einen Würfel und eine Liste mit Wörtern.
In dieser Liste findet man pro Zeile ein Wort dem eine fünfstellige, einzigartige Zahl vorangestellt ist. Will man nun zum Beispiel ein Passwort aus 5 Wörtern erstellen, muss man pro Wort 5 mal würfeln. Also insgesamt 25 mal. Am Ende hat man dann beispielsweise 54678 29412 37783 79381 erwürfelt. Nun schnappt man sich besagte Liste und sucht die betreffenden Wörter. Somit könnte beispielsweise DachsPlastikrodelnEinkaufFluss herauskommen. Wichtig hierbei ist, dass man die Wörter nicht neu würfelt oder sich eigene Wörter ausdenkt, wenn man mit dem Ergebnis nicht zufrieden ist.
Im Internet gibt es diverse Wörterlisten für Diceware. Zum Beispiel unter http://world.std.com/~reinhold/diceware.html. Diese ist aber inzwischen so bekannt, dass sie vermutlich schon von Crackern benutzt wird und zum anderen sind dort “nur” knapp 7800 Wörter enthalten.
Nehmen wir nun an, man trifft im Internet die Aussage, dass man Diceware nutzt. Somit steht die Chance für die bösen Buben nicht schlecht, dass man die offizielle Liste mit den Wörtern nutzt. Dies macht die Aufgabe das Passwort zu knacken schon etwas einfacher. Daher wäre eine eigene Liste wohl nicht verkehrt. Dies kann man mit folgendem Script erledigen.
Herunterladen und Entpacken der OpenThesaurus-Textversion (deutlich mehr als 7800 Worte)
Je einen Eintrag in jeweils eine Zeile packen
Filtern der Einträge mit Umlaute, Unterstrich oder Zahlen sowie Einträge die aus mehreren Wörtern bestehen
Entfernen aller Wörter mit weniger als 3 und mehr als 8 Zeichen
Entfernen eventueller doppelter Einträge
Zufällige Sortierung der restlichen Einträge<
Übernahme der ersten 10000 Einträge
Alphabetische Sortierung dieser Einträge
Nummerrierung der Einträge und das Abspeichern in die Datei “wordlist_de.txt”
Anhand dieser Liste lässt sich nun mittels eines Würfels ein Passwort aus einem großeren Pool an Wörtern erstellen. Wer hierzu keine Lust hat, kann auch Tools diceware nutzen. Diese kommen mit oben erstellter Liste auch zurecht. Es ist allerdings zu empfehlen wirklich selbst zu würfeln. Was die Anzahl der Wörter betrifft, sollte man aktuell mindestens 6 Wörter würfeln. Mehr sind natürlich besser. Wer will kann zwischen die Wörter noch ein Sonderzeichen oder ein Leerzeichen einfügen. Das erhöht die Sicherheit noch einmal.







 Ich möchte da nur zeitgleich an den
Ich möchte da nur zeitgleich an den