Mozilla hat Firefox 118.0.2 veröffentlicht und verbessert damit die Übersetzungsfunktion, behebt Webkompatibilitätsprobleme und bringt weitere Verbesserungen.
Download Mozilla Firefox 118.0.2
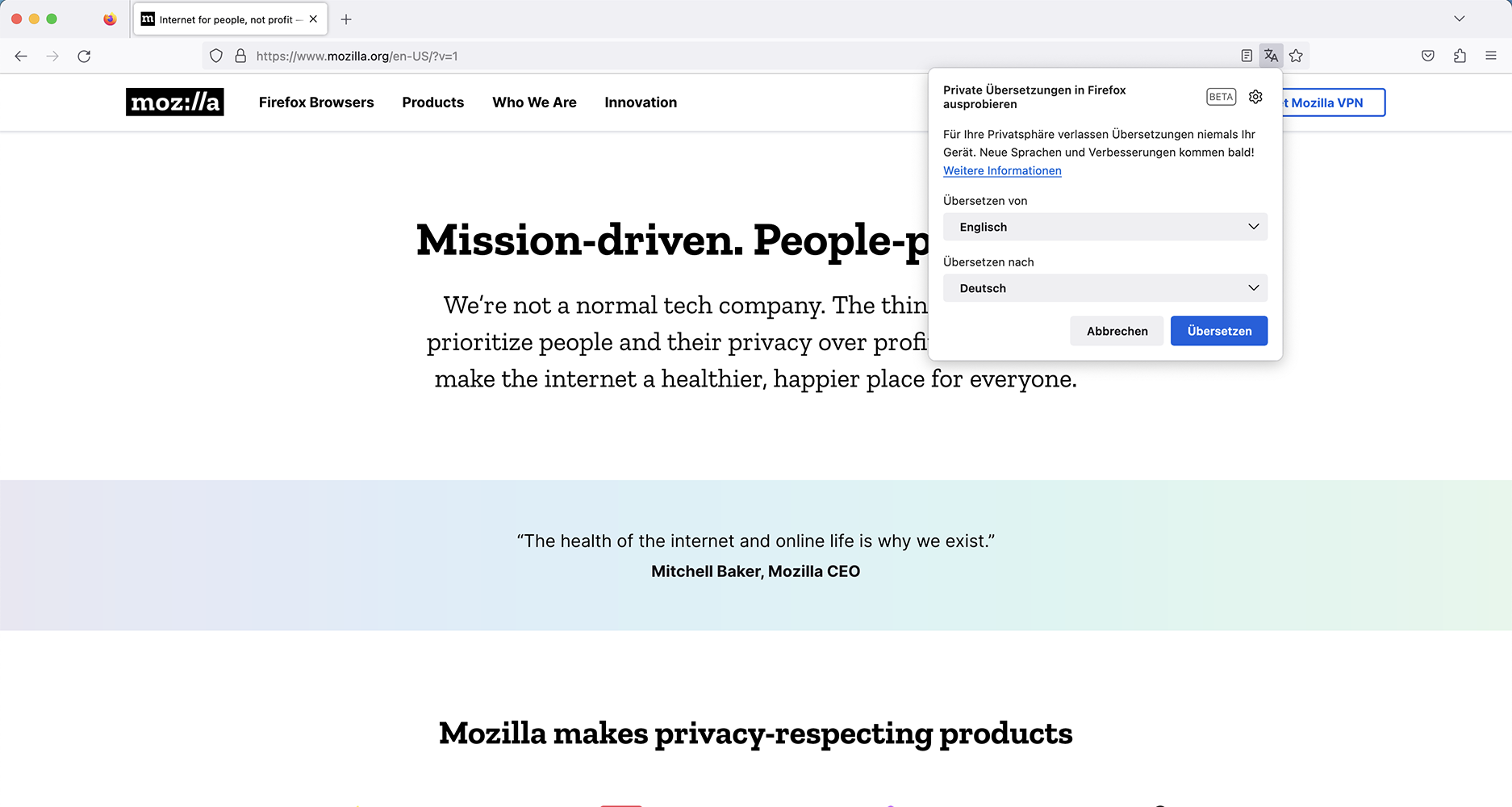
Mit dem Update auf Firefox 118.0.2 verbessert Mozilla die mit Firefox 118 eingeführte Übersetzungsfunktion, welche Websites komplett im Browser übersetzen kann, ohne die zu übersetzenden Texte an einen Online-Dienst wie Google Translate senden zu müssen. Ab sofort können auch Inhalte übersetzt werden, welche sich im sogenannten Shadow DOM einer Website befinden.
Firefox 118.0.2 behebt auch einige Webkompatibilitätsprobleme. So wurde ein Problem behoben, durch welches manche H.264 WebRTC-Videos nicht abgespielt werden konnten, ebenso wie ein Audio-Decoding-Problem unter Windows mit manchen Formaten korrigiert wurde. Ein weiteres behobenes Problem verursachte, dass die Website betsoft.com nicht geladen werden konnte. Ebenfalls behoben wurde das Problem, dass CORS XHR mit Authentifizierung nicht mehr funktionierte. Außerdem gab es Probleme beim Drucken mancher SVG-Grafiken.
Durch die Anti-Fingerprinting-Konfiguration von Firefox konnte es in privaten Fenstern dazu kommen, dass teilweise nicht die richtigen Schriften angezeigt worden sind. Dies hat vor allem Nutzer japanischer, chinesischer oder koreanischer Sprachen betroffen.
Für Nutzer von Windows 11 ab Build 22621 poppte bei Installation eine Berechtigungsanfrage von Windows für das Anpinnen an die Taskleiste auf. Mit Firefox 118.0.2 wird diese Aktion ab diesem Windows-Build nicht mehr als Teil des Installers ausgeführt, sondern nur noch als Teil der Willkommenstour, wo Nutzer explizit danach gefragt werden und wo diese Berechtigungsanfrage daher weniger Verwirrung beim Anwender auslöst.
Dazu kommt noch die Behebung dreier möglicher Absturzursachen sowie eine Performance-Verbesserung in Zusammenhang mit CSS und dem Shadow DOM.
Der Beitrag Mozilla veröffentlicht Firefox 118.0.2 erschien zuerst auf soeren-hentzschel.at.