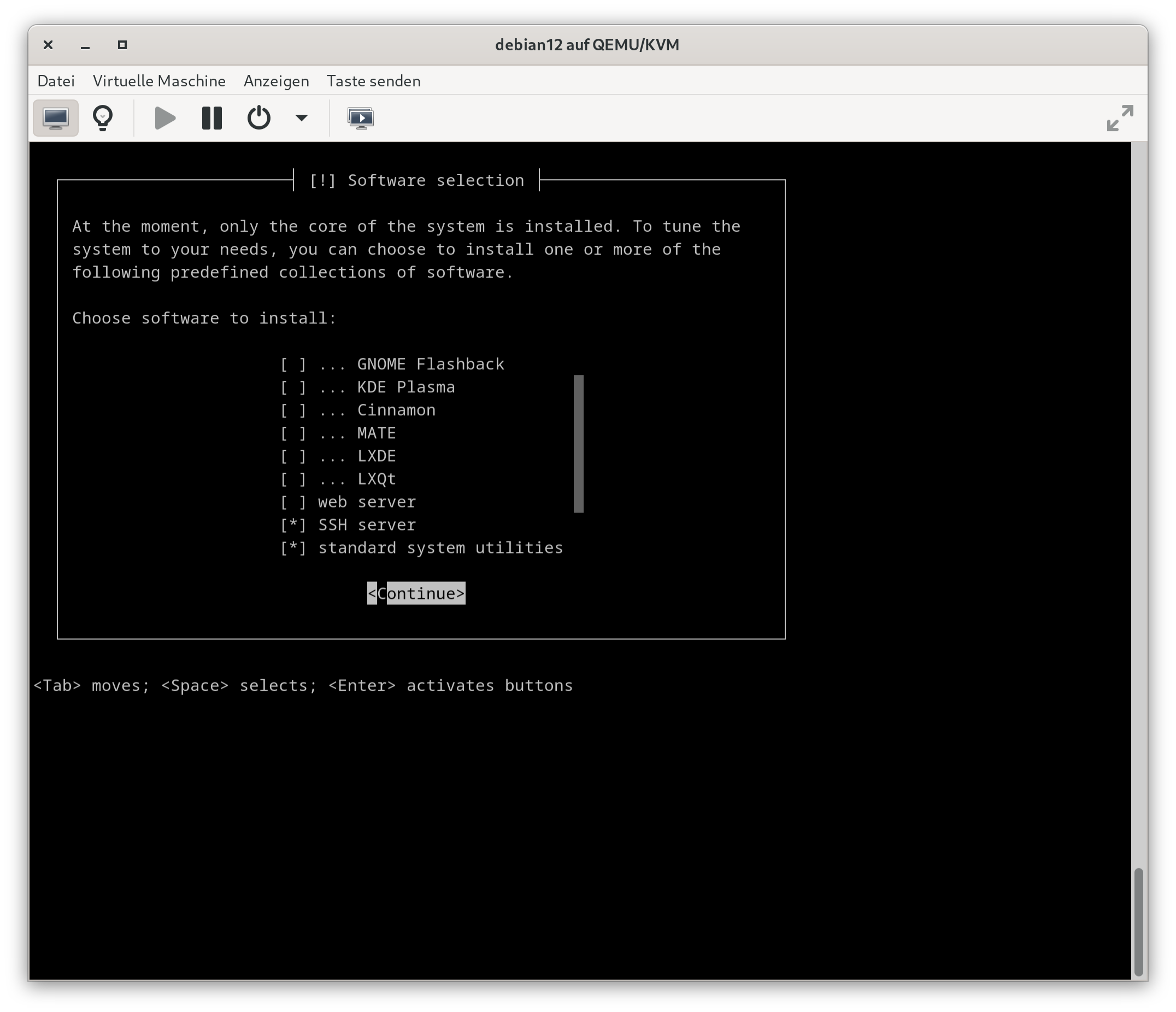
Mit dem TaschenrechnerTaschencomputer Sharp PC-1500 von
meinem Vater habe ich vor Dekaden (ca. 2) angefangen zu programmieren.
Ganz simpel in Basic. Haengen geblieben ist auf jeden Fall das “goto” *in
Nostalgie schwelg*
Aber warum noch eine weitere Software einsetzen, wenn es auch einfach™
mit Hugo geht, was ich sowieso schon nutze?
Im Folgenden stelle ich 3 Varianten vor, einmal die native Version mit
Aliases (wenigster Aufwand, aber auch Voraussetzung
fuer die beiden anderen Varianten), dann via einem Apache
Webserver und .htaccess-Dateien (mittlerer Aufwand, Apache
muss natuerlich eingesetzt werden) und zuletzt via einem nginx
Webserver und inkludierten Dateien (hoechster Aufwand, nginx
muss natuerlich eingesetzt werden).
Hierdurch werden nur die Shortlinks in der Uebersicht angezeigt, die den
Parameter public auf true gesetzt haben. Eine
Beispieldatei ist z.B. diese hier, die dann dort auch angezeigt
wird:
Der Rest der Magic passiert dann auf der Detailseite, hier wird die
Markdowndatei via des Alias Templates in eine kleine
HTML-Datei umgewandelt, die dann mit Hilfe von dem <meta> http-equiv Attribut eine Weiterleitung auf das
target macht:
Diese Variante habe ich mir von Til Seiffert abgeguckt . Dort wird
eine .htaccess-Datei genutzt, um alle Hugo Aliases in
einer Datei zu sammeln und damit eine “richtige” und schnellere
Weiterleitung zu bekommen.
In meinem Anwendungsfall brauche ich das nicht fuer alle Aliases,
sondern eben nur fuer die in der Sektion goto, aber die Vorgehensweise
ist aehnlich.
Zudem muss noch im Front matter der content/goto/_index.md
festgelegt werden, dass fuer diese Sektion “html” und “htaccess”
ausgegeben werden soll, aber kein “rss”, was erstmal der Standard fuer
Sektionen ist:
---
title: "goto"
# no rss here please, but html and htaccess
outputs:
- html
- htaccess
---
Die eigentliche .htaccess fuer die Sektion goto sieht dann wie folgt
aus (hier wird eine Hugo Page Methode namens File genutzt):
Ich habe hier den HTTP-Statuscode 302 gewaehlt, da
sich die Ziele theoretisch aendern koennen (und nginx diesen Code auch
nutzt fuer die temporaere Weiterleitung). 307 waere auch eine
Moeglichkeit.
Da ich nicht Apache als Webserver einsetze, kann ich nicht garantieren,
dass das auch alles so klappt. Aber mit der .htaccess in einem
Verzeichnis sollte™ das gehen. Wenn nicht, gerne Bescheid
geben.
Wie bei Apache auch wollen wir diese Datei ja nur in der Sektion goto
haben, daher tragen wir auch nur im Front matter der
content/goto/_index.md folgendes ein:
---
title: "goto"
# no rss here please, but html, htaccess and nginx
outputs:
- html
- htaccess
- nginx
---
Und definieren zu guter Letzt noch eine nginx.conf
(Doku ):
So, jetzt wird es spannend. Wie bekommt nginx jetzt diese Regeln mit?
Eine .htaccess koennen wir ja nicht einsetzen.
Aber wir koennen
include nutzen ! Das geht auch, wenn die Datei leer
ist, allerdings leider nicht, wenn die Datei nicht vorhanden
ist.
Entweder wird also der Ordner goto und eine leere nginx.conf
angelegt, oder wir passen die nginx Config erst an, wenn die Website mit
hugo gebaut wurde.
Jedenfalls sieht meine nginx Config in etwa so aus:
Im Prinzip koennen auch alle Weiterleitungen oeffentlich sein, dann kann
sich der Aufwand mit dem Parameter “public” auch gespart werden.
Allerdings verwende ich den nun und muss sich daher auch drum kuemmern,
dass nicht aus Versehen was in den RSS Feeds, der Sitemap
oder sonst wo auftaucht.
Die Standard sitemap.xml habe ich sowieso schon
angepasst, falls ich Seiten habe, die ich mit dem Parameter “exclude”
eben nicht in der Sitemap haben will (siehe
GitHub Issue #653 dazu). Fuer die Sektion goto kam
dann noch ein Zusatz dazu.
Theoretisch brauchen wir mit Einsatz von Apache oder nginx die
Alias-Dateien nicht mehr, also koennte die Datei
layouts/goto/single.html auch geloescht werden.
Als kleine™ Spielerei koennte jetzt noch an jeden “goto” ein QR-Code
dran geklebt werden. Z.B. koennte neben der nginx Datei auch noch fuer
jeden Link eine Textdatei erstellt werden, die den Link enthaelt. Ein
Script koennte dann vor dem Bauen der Website mit hugo via find
ueber all diese Textdateien drueberlaufen und mit einem Text-QR-Code
ersetzen, die dann z.B. mit readfile eingebunden
werden.
Ja, richtig gelesen, QR-Codes muessen nicht unbedingt Bilder sein,
sondern koennen auch aus Text bestehen. qrencode bringt
sowas auch schon mit:
qrencode -t UTF8i "https://uxg.ch"| sed 's/[ \t]*$//;/^$/d'
In drei Wochen beginnen die Chemnitzer Linux-Tage 2024 mit dem diesjährigen Motto „Zeichen setzen“. Am 16. und 17. März erwartet euch im Hörsaalgebäude an der Richenhainer Straße 90 ein vielfältiges Programm an Vorträgen und Workshops. Hier finden sich Vorträge für interessierte Neueinsteiger wie für alte Hasen.
So geht es am Samstag im Einsteigerforum beispielsweise um die Digitalisierung analoger Fotos, das Erstellen von Urlaubsvideos mit der Software OpenShot oder die Verschlüsselung von E-Mails. In der Rubrik „Schule“ gibt Arto Teräs einen Einblick in den Einsatz der Open-Source-Lösung Puavo an finnischen und deutschen Schulen. Zusätzlich stehen Vorträge aus den Bereichen Finanzen, Medien, Datensicherheit, KI oder Netzwerk auf dem Programm. Am Sonntag gibt das Organisationsteam der Chemnitzer Linux-Tage mit „make CLT“ Einblicke in die Planung und Strukturen der Veranstaltung selbst. In der Rubrik „Soft Skills” wird es um die Schätzung von Aufwänden oder notwendige Fähigkeiten von Software-Entwicklern gehen.
Eintrittskarten können online im Vorverkauf und an der Tageskasse erworben werden. Kinder bis 12 Jahren haben freien Eintritt.
Während viele Besucher bereits Stammgäste sind, werden auch neue Gesichter herzlich willkommen. Lasst euch gern von der hier herrschenden Atmosphäre voller Begeisterung für freie Software und Technik anstecken und begeistern.
Ich selbst freue mich, am Samstag um 10:00 Uhr in V6 den Vortrag mit dem obskuren Namen ::1 beisteuern zu dürfen. Update: Unverhofft kommt oft. Uns so freue ich mich am Sonntag um 10:00 Uhr in Raum V7 noch in einem zweiten Vortrag vertreten zu sein. Zusammen mit Michael Decker von der ASPICON GmbH erfahrt ihr, wie man „Mit Ansible Collections & Workflows gegen das Playbook-Chaos“ angehen kann.
Darüber hinaus beteilige ich mich als Sessionleiter für die folgenden drei Vorträge an der Veranstaltung:
So habe ich auf jeden Fall einen Platz im Raum sicher. ;-)
Wer ebenfalls helfen möchte, kann sich unter Mitmachen! informieren und melden.
Für mich ist dieses Jahr einiges im Programm dabei. Doch freue ich mich ebenso sehr auf ein Wiedersehen mit alten Bekannten aus der Gemeinschaft und darauf, neue Gesichter (Namen kann ich mir meist erst Jahre später merken) kennenzulernen.
Mozilla hat über seinen Risikokapitalfonds Mozilla Ventures in das deutsche KI-Startup Flower Labs investiert.
Mozilla Ventures ist ein Ende 2022 gestarteter und mit 35 anfänglich Millionen USD ausgestatteter Risikokapitalfonds, über welchen Mozilla in Startups investiert, welche das Internet und die Tech-Industrie in eine bessere Richtung bringen. Nach zahlreichen Investitionen im vergangenen Jahr ist nun die erste Investition des Jahres 2024 bekannt.
So ist Mozilla Ventures an der Serie-A-Finanzierungsrunde beteiligt, in deren Rahmen das Hamburger Unternehmen Flower Labs insgesamt 20 Millionen USD einsammeln konnte. Die Seite Hamburg Startups beschreibt den Aufgabenbereich von Flower Labs wie folgt:
Das Ziel von Flower Labs ist es, die Art und Weise zu verändern, wie die Welt an KI herangeht. Durch die Vereinfachung der Nutzung dezentraler Technologien wie föderiertes Lernen wird eine Reihe von Vorteilen gegenüber zentralisierten Alternativen erschlossen. Dazu gehört vor allem der sichere Zugang zu großen Mengen verteilter Daten, wie sie in Krankenhäusern, Unternehmen, Produktionsanlagen, Autos und Telefonen anfallen. Solche Daten bleiben relativ ungenutzt und werden ein Katalysator für Fortschritte in einer Reihe von KI-Anwendungsbereichen sein – etwa im Gesundheitswesen, in der Fertigung, im Finanzwesen und in der Automobilindustrie. In diesem nächsten Schritt der KI wird Flower das entscheidende Open-Source-Framework und -Ökosystem sein, wenn sich die KI-Software zur Unterstützung dieser neuen Generation dezentraler Systeme weiterentwickelt.
So mancher Nutzer wird für virtuelle Maschinen das Programm VirtualBox nutzen. Diese virtuellen Maschinen liegen in der Regel in Form von VDI-Dateien vor. Leider ist dieses Format nicht mit KVM kompatibel.
KVM oder besser gesagt QEMU nutzt nämlich das Format qcow/qcow2. QEMU bietet glücklicherweise eine einfache Lösung die virtuellen Maschinen von einem Format in ein anderes umzuwandeln.
Mit diesem Beispiel wird anhand der unter VirtualBox erstellten virtuellen Maschine CentOS7.vdi eine identische virtuelle Maschine im gcow2-Format (CentOS7.qcow2) erzeugt.
Die Datei CentOS7.vdi bleibt hierbei erhalten und kann anschließend gelöscht werden. Die Datei CentOS.qcow2 benötigt ungefähr den gleichen Speicherplatz.
In manchen Fällen kann es vorkommen, dass das direkte Umwandeln nicht funktioniert. In solch einem Fall hilft es meist die Datei CentOS7.vdi mit VirtualBox mit folgendem Befehl in ein RAW-Image umzuwandeln und dieses dann in das Format umzuwandeln das QEMU unterstützt.
1VBoxManage clonehd --format RAW CentOS7.vdi CentOS7.img
2qemu-img convert -f raw CentOS7.img -O qcow2 CentOS7.qcow2
Aber Achtung! Images im RAW-Format benötigen mehr Speicherplatz. RAW-Images sind nicht komprimiert. Und sollte die virtuelle Festplatte unter VirtualBox dynamisch angelegt worden sein, ist das Image so groß wie die maximale Größe der virtuellen Festplatte. Auch dann, wenn diese nur zu einem Bruchteil tatsächlich belegt ist.
Nach der erfolgreichen Umwandlung kann die neue virtuelle Maschine zum Beispiel mit virt-manager direkt genutzt werden.
Wer unter VirtualBox die Guest Additions genutzt hat, sollte diese vor der Umwandlung entfernen. Genauso sollte vorher in den Einstellungen unter VirtualBox geprüft werden, dass beim Grafik-Controller nicht VBoxVGA oder VBoxSVGA ausgewählt ist.
Mozilla hat Firefox 123 für Windows, Apple macOS und Linux veröffentlicht. Dieser Artikel fasst die wichtigsten Neuerungen zusammen – wie immer auf diesem Blog weit ausführlicher als auf anderen Websites.
Die mit Firefox 106 eingeführte und mit Firefox 119 stark verbesserte Funktion Firefox View hat mit Firefox 123 eine Suchfunktion erhalten. Diese steht in allen Reitern zur Verfügung, um den entsprechenden Abschnitt durchsuchen zu können: Kürzlich besucht, Offene Tabs, Kürzlich geschlossene Tabs, Tabs von anderen Geräten, Chronik. Außerdem wurde die Performance von Firefox View verbessert.
Verbesserungen der Übersetzungsfunktion
Die Funktion zur vollständigen Übersetzung von Websites, welche im Gegensatz zu Google Translate & Co. komplett im Browser arbeitet und nichts an einen Server sendet, übersetzt jetzt auch Platzhaltertexte in Formularelementen sowie Tooltips.
Übersetzungen werden jetzt für zehn Minuten gecacht, sodass wiederkehrende Übersetzungen, wenn beispielsweise die Seite häufiger neu geladen werden muss, schneller erfolgen. Außerdem wird nach erfolgter Übersetzung das lang-Attribut der Website entsprechend verändert.
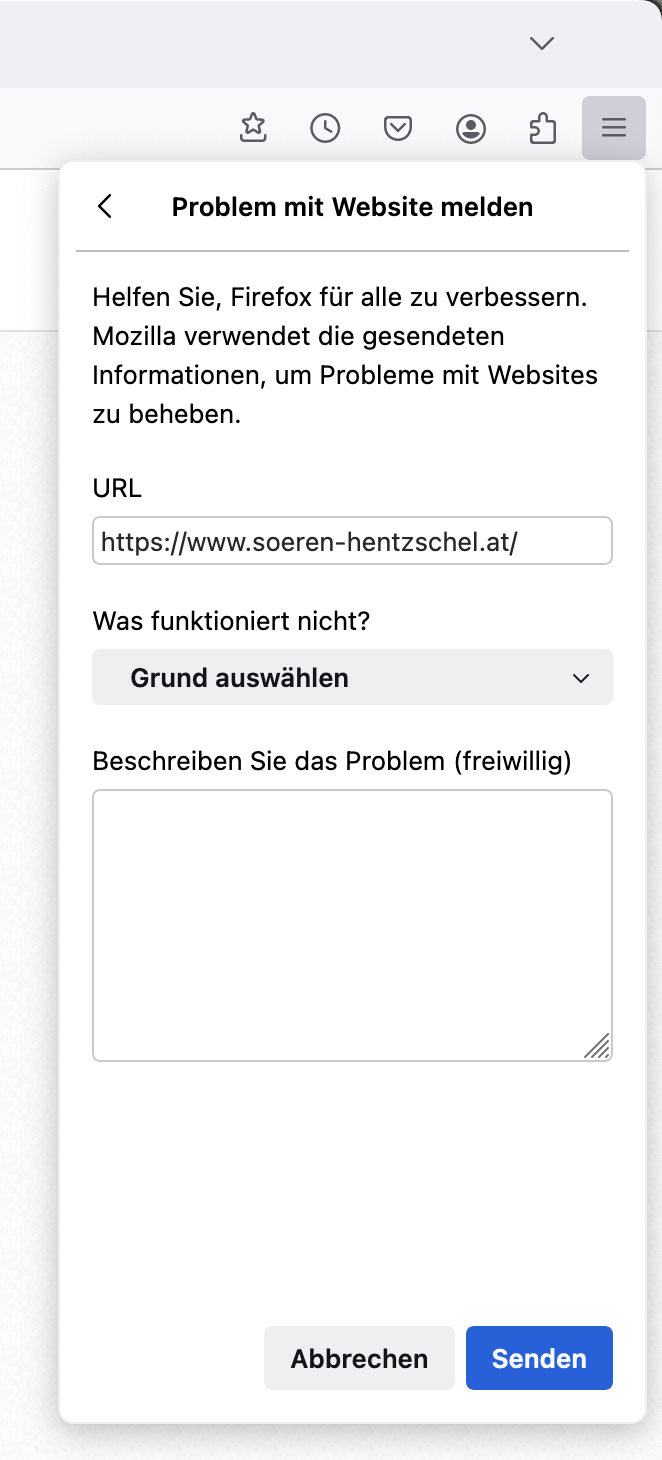
Kompatibilitätsprobleme mit Websites melden
Mozilla hat eine Melden-Funktion für webcompat.com in das Hauptmenü von Firefox integriert. Wer auf ein Website-Problem stößt, welches in einem anderen Browser nicht besteht, kann dieses darüber melden, sodass Mozilla von dem Problem mitbekommt und ggf. notwendige Maßnahmen einleiten kann.
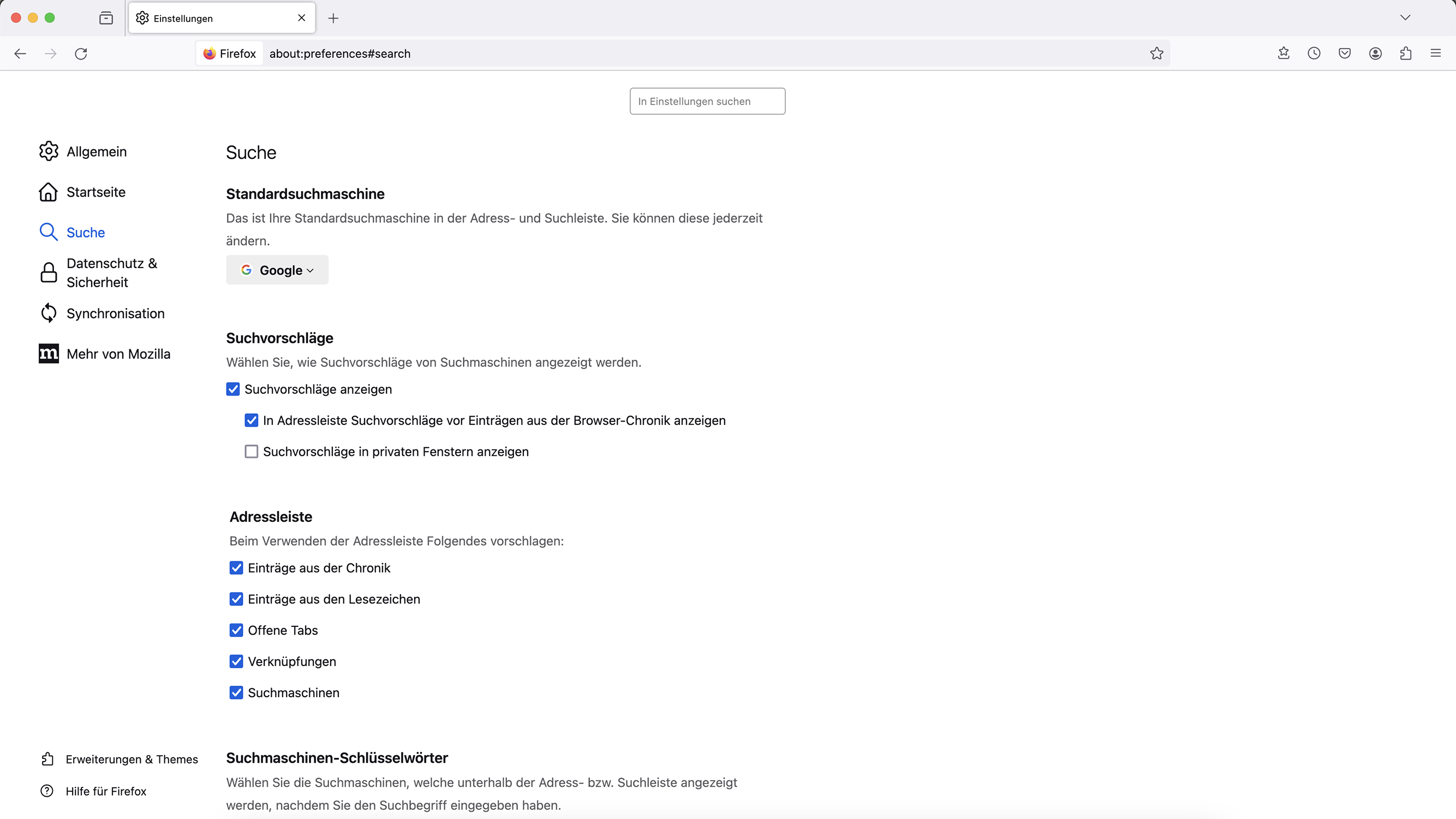
Sonstige Endnutzer-Neuerungen von Firefox 123
Die Konfiguration, welche Inhalte über die Adressleiste vorgeschlagen werden, befindet sich in den Einstellungen jetzt im Reiter für die Suche, sodass alle Optionen, welche Vorschläge betreffen, an einem zentralen Ort zu suchen sind und nicht länger über zwei Kategorien verteilt sind.
Unter Windows wurde die sichtbare Option für die Verwendung eines Hintergrunddienstes zur Installation von Firefox-Updates entfernt. Der Hintergrunddienst ist notwendig, damit Nutzer nicht bei jedem Firefox-Update den UAC-Dialog von Windows bestätigen müssen.
Performance-Verbesserungen gab es für Nutzer von macOS mit Apple Silicon durch verbesserte PGO-Optimierungen, für Linux-Nutzer durch eine Anpassung der Sandbox sowie für Nutzer von macOS und Linux durch Off-Main-Thread Canvas. Beschleunigt wurde auch die Zeit zum Wiederherstellen vieler Tabs.
Unter Linux wurde die CPU-Architektur im User-Agent eingefroren und zeigt nun unabhängig von der tatsächlichen Hardware immer x86_64 an.
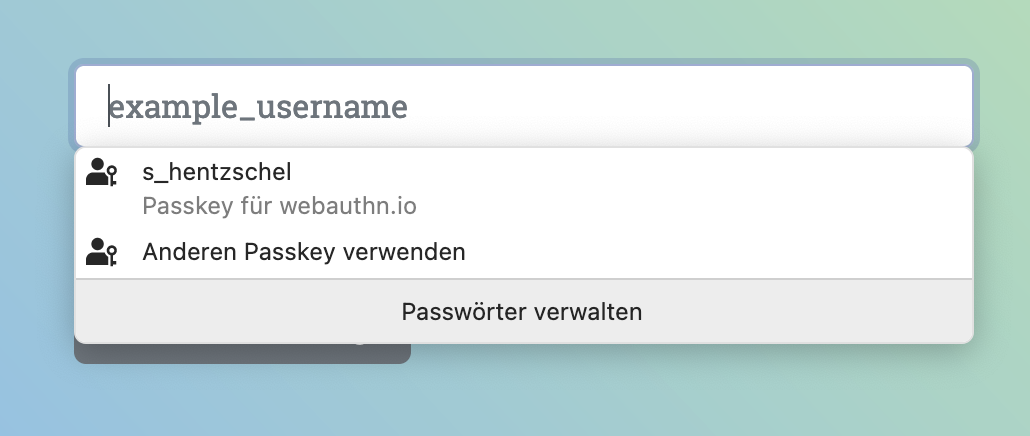
Auf macOS schlägt Firefox bei Login-Feldern im iCloud-Schlüsselbund gespeicherte Passkey-Zugänge vor, sofern welche für die Domain existieren.
Nutzer, welche nicht für die Synchronisation in Firefox angemeldet sind, sehen jetzt standardmäßig eine Schaltfläche zum Anmelden in der Navigationssymbolleiste. Wer diese Schaltfläche nicht möchte, kann diese wie üblich über das Kontextmenü entfernen.
Mehr Sicherheit für Firefox-Nutzer
Auch in Firefox 123 wurden wieder mehrere Sicherheitslücken geschlossen. Alleine aus Gründen der Sicherheit ist ein Update auf Firefox 123 daher für alle Nutzer dringend empfohlen.
Verbesserungen der Entwicklerwerkzeuge
Im Netzwerkanalyse-Werkzeug ersetzt ein neuer Kontextmenüeintrag zum Speichern der Antwort den bisherigen Eintrag zum Speichern von Bildern. Dafür steht diese Option jetzt für alle Dateitypen und nicht länger nur für Bilder zur Verfügung.
Der HTTP-Statuscode 103 Early Hints ist für das Vorladen von Ressourcen aktiviert, welche die Seite wahrscheinlich benötigt, während der Server noch die vollständige Antwort vorbereitet. Dies kann die Ladezeit einer Seite erheblich verkürzen.
Die WebExtension-Schnittstelle für Tab-Umgebungen wurde um eine Methode erweitert, die es Erweiterungs-Entwicklern erlaubt, die Reihenfolge der Tab-Umgebungen zu verändern.
Weitere Neuerungen für Entwickler von Websites lassen sich in den MDN Web Docs nachlesen.
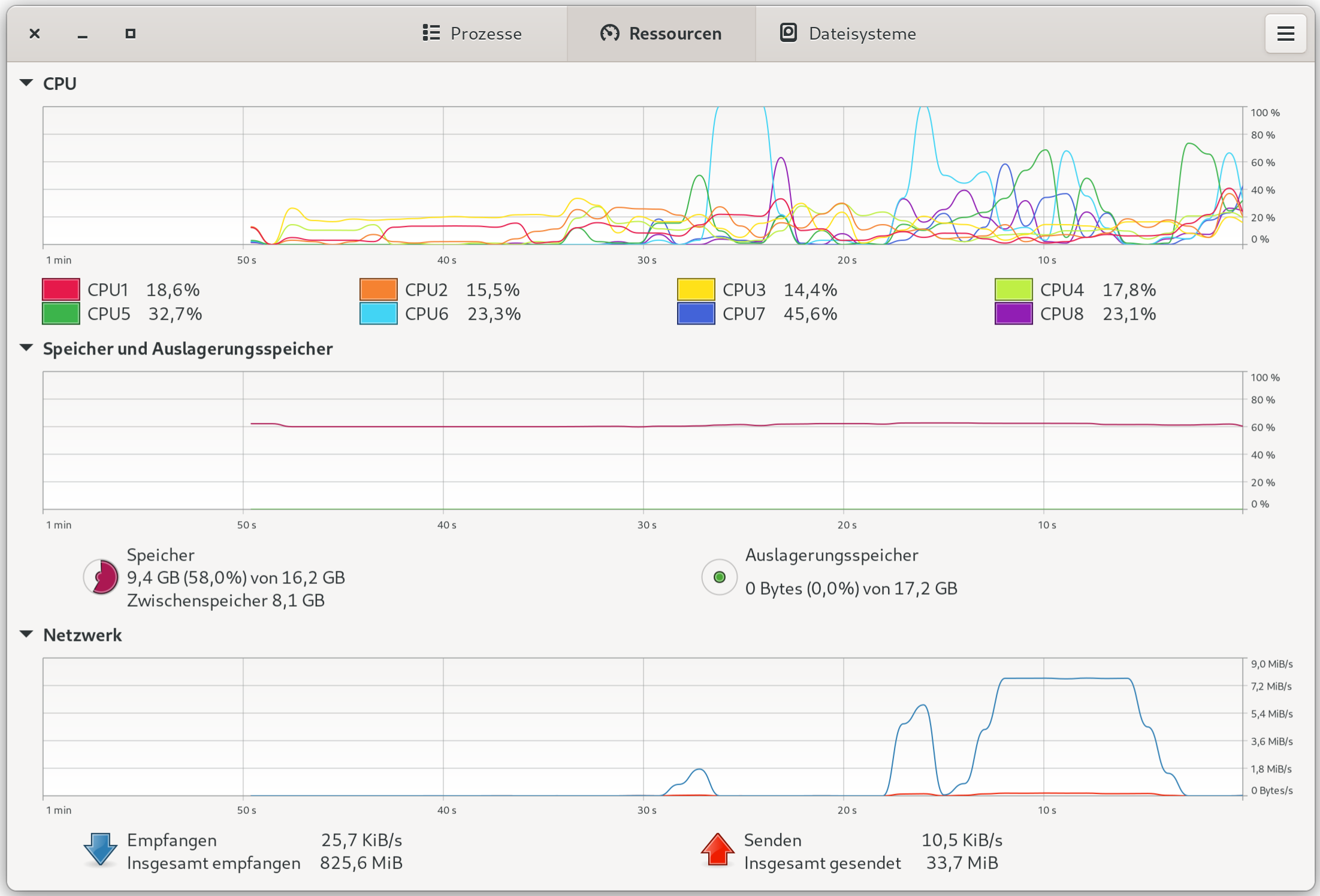
Die letzten Wochen habe ich mich ziemlich intensiv mit Home Assistant auseinandergesetzt. Dabei handelt es sich um eine Open-Source-Software zur Smart-Home-Steuerung. Home Assistant (HA) ist eine spezielle Linux-Distribution, die häufig auf einem Raspberry Pi ausgeführt wird. Dieser Artikel zeigt die nicht ganz unkomplizierte Integration meines Fronius Wechselrichters in das Home-Assistant-Setup. (Die Basisinstallation von HA setze ich voraus.)
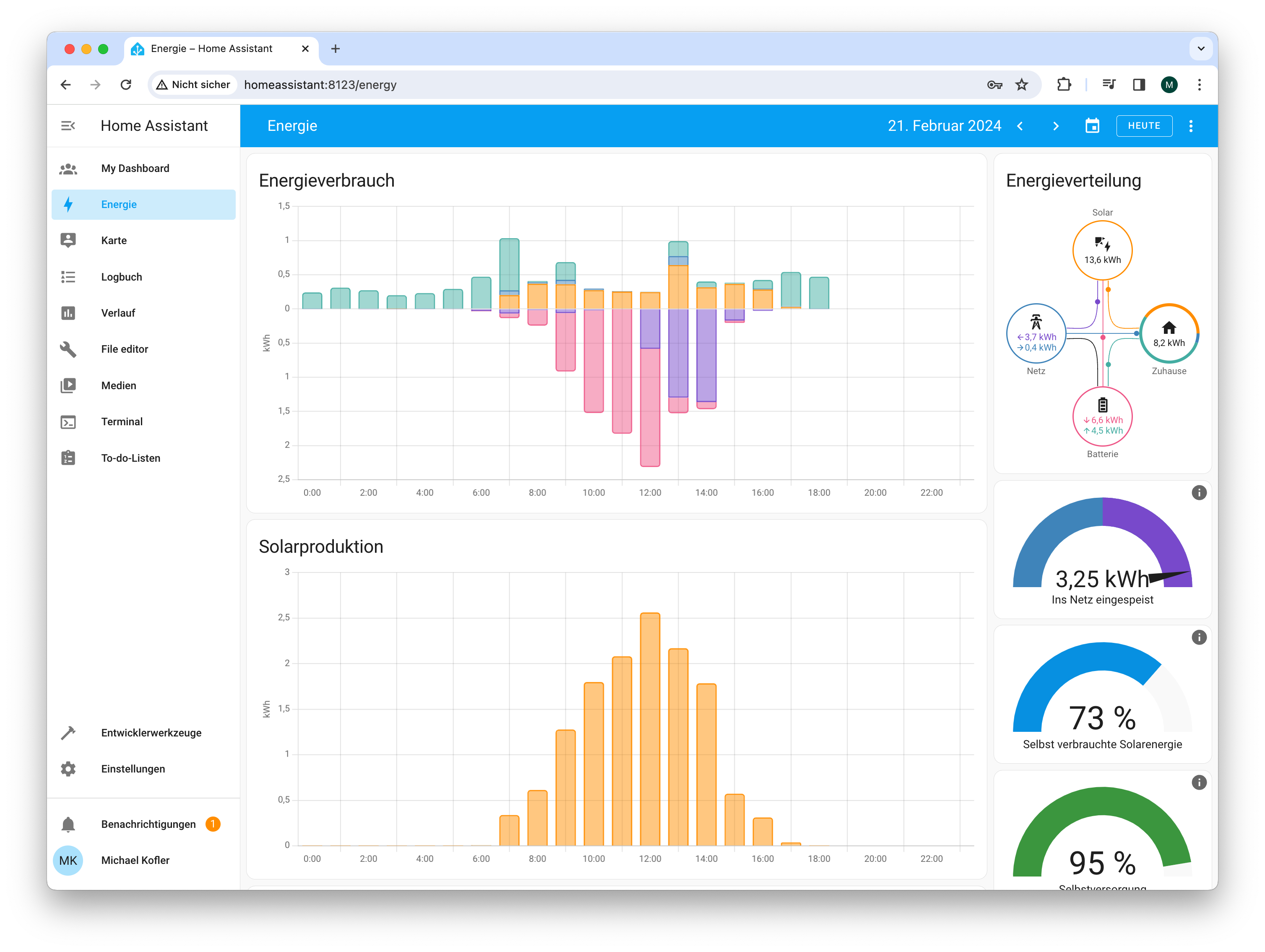
Die Energieansicht nach der erfolgreichen Integration des Fronius Wechselrichters.
Die Abbildung ist wie folgt zu interpretieren: Heute bis 19:00 wurden im Haushalt 8,2 kWh elektrische Energie verbraucht, aber 13,6 kWh el. Energie produziert (siehe die Kreise rechts). 3,7 kWh wurden in das Netz eingespeist, 0,4 kWh von dort bezogen.
Das Diagramm »Energieverbrauch« (also das Balkendiagramm oben): In den Morgen- und Abendstunden hat der Haushalt Strom aus der Batterie bezogen (grün); am Vormittag wurde der Speicher wieder komplett aufgeladen (rot). Am Nachmittag wurde Strom in das Netz eingespeist (violett). PV-Strom, der direkt verbraucht wird, ist gelb gekennzeichnet.
Fronius-Integration
Bevor Sie mit der Integration des Fronius-Wechselrichters in das HA-Setup beginnen, sollten Sie sicherstellen, dass der Wechselrichter, eine fixe IP-Adresse im lokalen Netzwerk hat. Die erforderliche Einstellung nehmen Sie in der Weboberfläche Ihres WLAN-Routers vor.
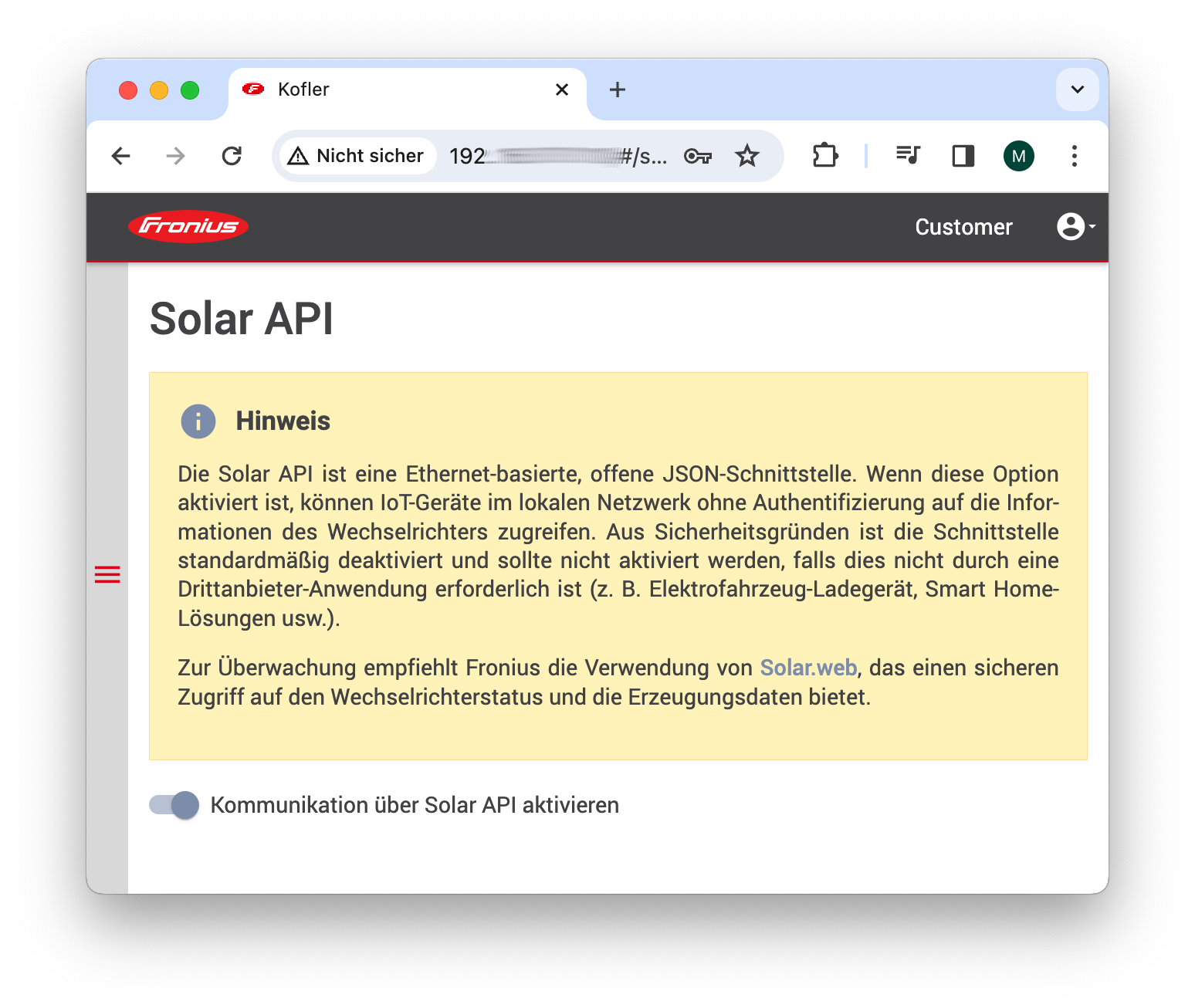
Außerdem müssen Sie beim Wechselrichter die sogenannte Solar API aktivieren. Über diese REST-API können diverse Daten des Wechselrichters gelesen werden. Zur Aktivierung müssen Sie sich im lokalen Netzwerk in der Weboberfläche des Wechselrichters anmelden. Die relevante Option finden Sie unter Kommunikation / Solar API. Der Dialog warnt vor der Aktivierung, weil die Schnittstelle nicht durch ein Passwort abgesichert ist. Allzugroß sollte die Gefahr nicht sein, weil der Zugang ohnedies nur im lokalen Netzwerk möglich ist und weil die Schnittstelle ausschließlich Lesezugriffe vorsieht. Sie können den Wechselrichter über die Solar API also nicht steuern.
Aktivierung der Solar API in der lokalen Weboberfläche des Fronius-Wechselrichters
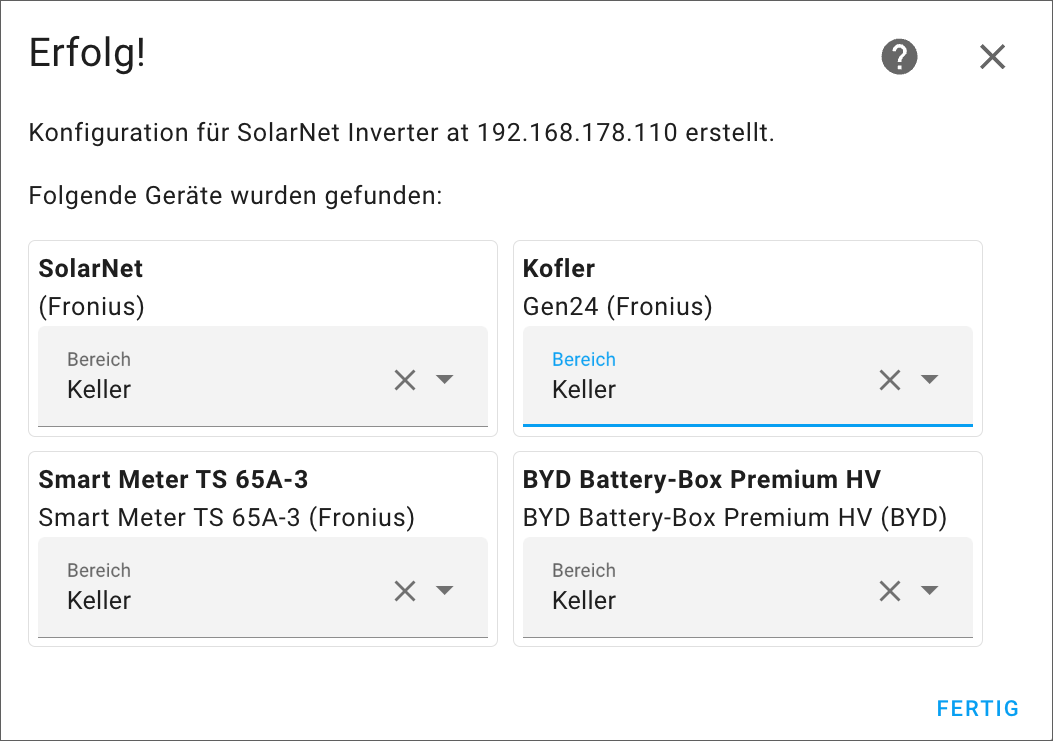
Als nächstes öffnen Sie in der HA-Weboberfläche die Seite Einstellungen / Geräte & Dienste und suchen dort nach der Integration Fronius (siehe auch hier). Im ersten Setup-Dialog müssen Sie lediglich die IP-Adresse des Wechselrichters angeben. Im zweiten Dialog werden alle erkannten Komponenten aufgelistet und Sie können diese einem Bereich zuordnen.
Setup der Fronius-Integration in der Weboberfläche von Home Assistant
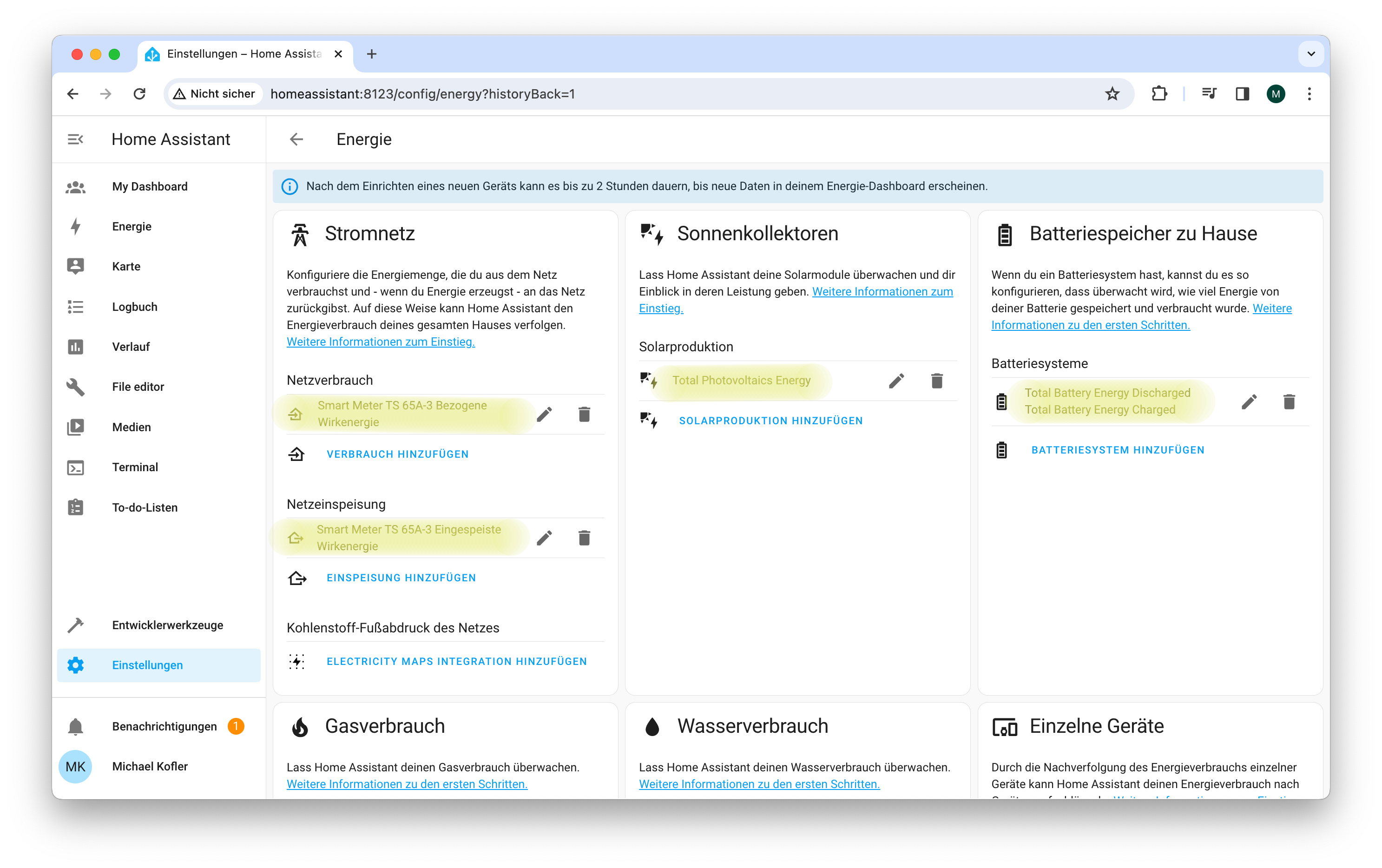
Bei meinen Tests standen anschließend über 60 neue Entitäten (Sensoren) für alle erdenklichen Betriebswerte des Wechselrichters, des damit verbundenen Smartmeters sowie des Stromspeichers zur Auswahl. Viele davon werden automatisch im Default-Dashboard angezeigt und machen dieses vollkommen unübersichtlich.
Energieansicht
Der Zweck der Fronius-Integration ist weniger die Anzeige diverser einzelner Betriebswerte. Vielmehr sollen die Energieflüssen in einer eigenen Energieansicht dargestellt werden. Diese Ansicht wertet die Wechselrichterdaten aus und fasst zusammen, welche Energiemengen im Verlauf eines Tags, einer Woche oder eines Monats wohin fließen. Die Ansicht differenziert zwischen dem Energiebezug aus dem Netz bzw. aus den PV-Modulen und berücksichtigt bei richtiger Konfiguration auch den Stromfluss in den bzw. aus dem integrierten Stromspeicher. Sofern Sie eine Gasheizung mit Mengenmessung verfügen, können Sie auch diese in die Energieansicht integrieren.
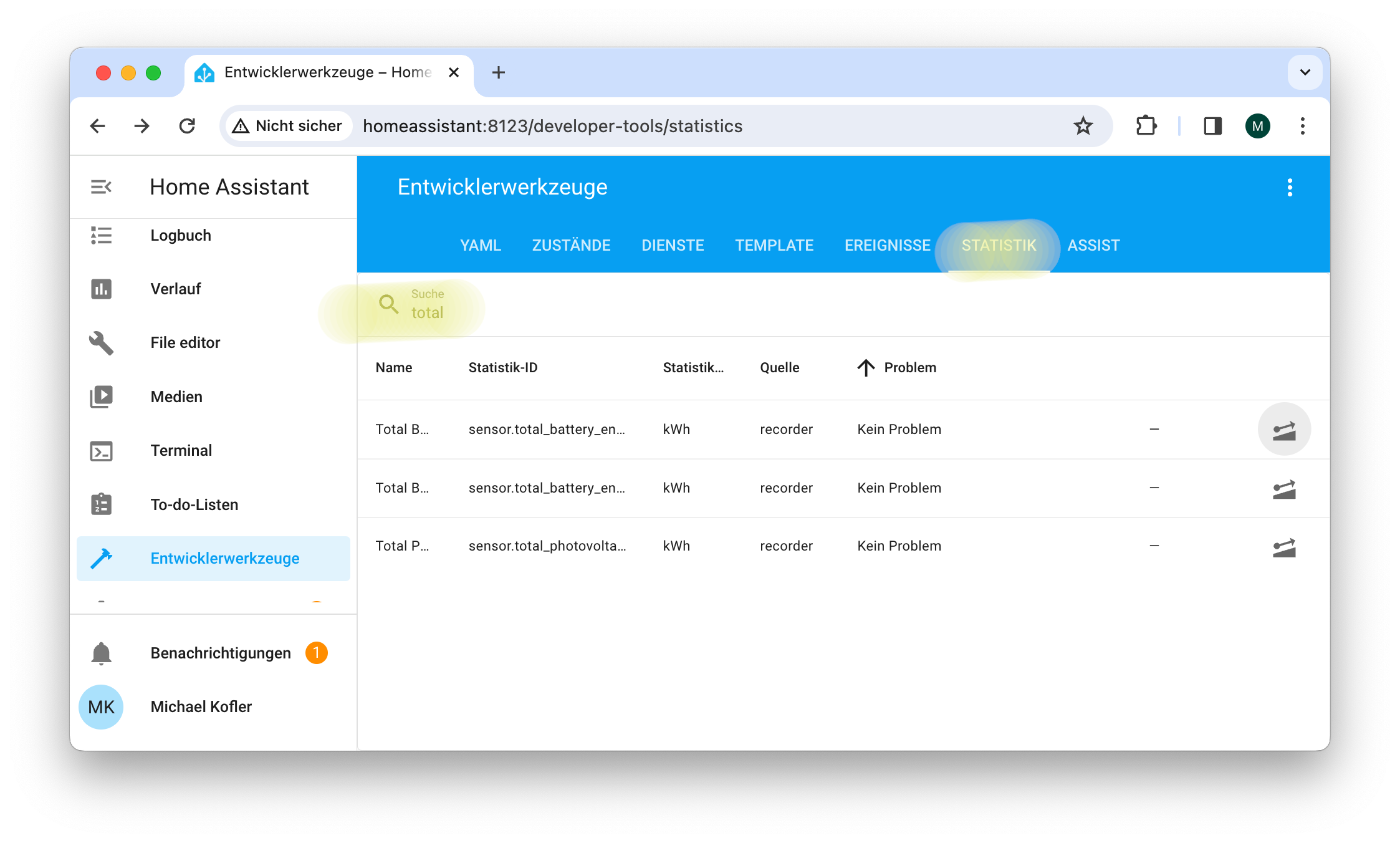
Die Konfiguration der Energieansicht hat sich aber als ausgesprochen schwierig erwiesen. Auf Anhieb gelang nur das Setup des Moduls Stromnetz. Damit zeigt die Energieansicht nur an, wie viel Strom Sie aus dem Netz beziehen bzw. welche Mengen Sie dort einspeisen. Die Fronius-Integration stellt die dafür Daten in Form zweier Sensoren direkt zur Verfügung:
Aus dem Netz bezogene Energie: sensor.smart_meter_ts_65a_3_bezogene_wirkenergie
In das Netz eingespeiste Energie: sensor.smart_meter_ts_65a_3_eingespeiste_wirkenergie
Je nachdem, welchen Wechselrichter und welche dazu passende Integration Sie verwenden, werden die Sensoren bei Ihnen andere Namen haben. In den Auswahllisten zur Stromnetz-Konfiguration können Sie nur Sensoren
auswählen, die Energie ausdrücken. Zulässige Einheiten für derartige Sensoren sind unter anderem Wh (Wattstunden), kWh oder MWh.
Konfiguration der Energie-Ansicht in Home Assistant
Code zur Bildung von drei Riemann-Integralen
Eine ebenso einfache Konfiguration der Module Sonnenkollektoren und Batteriespeicher zu Hause scheitert daran, dass die Fronius-Integration zwar aktuelle Leistungswerte für die Produktion durch die PV-Module und den Stromfluss in den bzw. aus dem Wechselrichter zur Verfügung stellt (Einheit jeweils Watt), dass es aber keine kumulierten Werte gibt, welche Energiemengen seit dem Einschalten der Anlage geflossen sind (Einheit Wattstunden oder Kilowattstunden). Im Internet gibt es eine Anleitung, wie dieses Problem behoben werden kann:
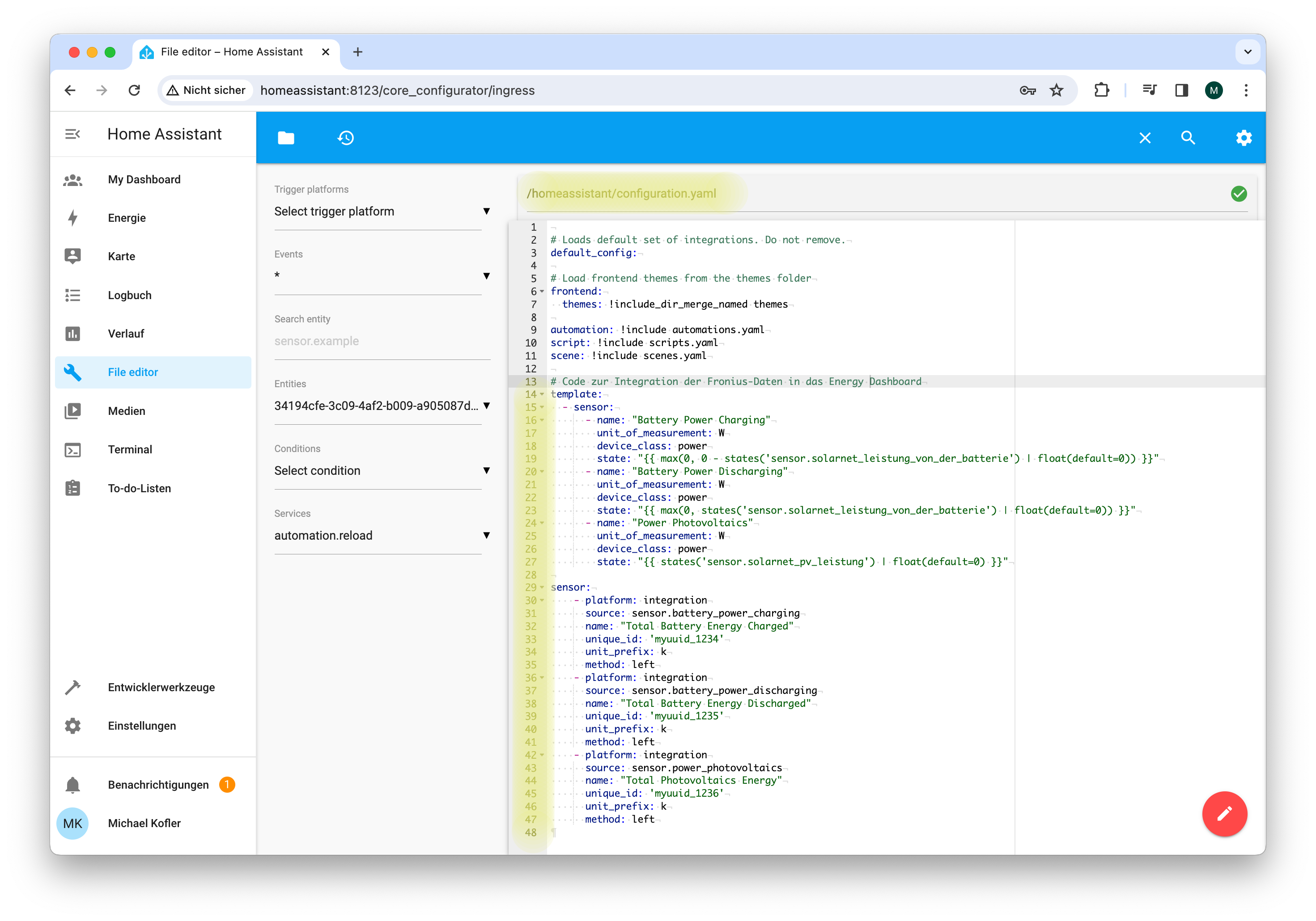
Die Grundidee besteht darin, dass Sie eigenen Code in eine YAML-Konfigurationsdatei von Home Assistant einbauen. Gemäß dieser Anweisungen werden mit einem sogenannten Riemann-Integral die Leistungsdaten in Energiemengen umrechnet. Dabei wird regelmäßig die gerade aktuelle Leistung mit der zuletzt vergangenen Zeitspanne multipliziert. Diese Produkte (Energiemengen) werden summiert (method: left). Das Ergebnis sind drei neue Sensoren (Entitäten), deren Name sich aus den title-Attributen im zweiten Teil des Listings ergeben:
Die Umsetzung der Anleitung hat sich insofern schwierig erwiesen, als die in der ersten Hälfte des Listungs verwendeten Sensoren aus der Fronius-Integration bei meiner Anlage ganz andere Namen hatten als in der Anleitung. Unter den ca. 60 Sensoren war es nicht ganz leicht, die richtigen Namen herauszufinden. Wichtig ist auch die Einstellung device_class: power! Die in einigen Internet-Anleitungen enthaltene Zeile device_class: energy ist falsch.
Der template-Teil des Listings ist notwendig, weil der Sensor solarnet_leistung_von_der_batterie je nach Vorzeichen die Lade- bzw. Entladeleistung enthält und daher getrennt summiert werden muss. Außerdem kommt es vor, dass die Fronius-Integration einzelne Werte gar nicht übermittelt, wenn sie gerade 0 sind (daher die Angabe eines Default-Werts).
Der zweite Teil des Listungs führt die Summenberechnung durch (method: left) und skaliert die Ergebnisse um den Faktor 1000. Aus 1000 Wh wird mit unit_prefix: k also 1 kWh.
Bevor Sie den Code in configuration.yaml einbauen können, müssen Sie einen Editor als Add-on installieren (Einstellungen / Add-ons, Add-on-Store öffnen, dort den File editor auswählen).
# in die Datei /homeassistant/configuration.yaml einbauen
...
template:
- sensor:
- name: "Battery Power Charging"
unit_of_measurement: W
device_class: power
state: "{{ max(0, 0 - states('sensor.solarnet_leistung_von_der_batterie') | float(default=0)) }}"
- name: "Battery Power Discharging"
unit_of_measurement: W
device_class: power
state: "{{ max(0, states('sensor.solarnet_leistung_von_der_batterie') | float(default=0)) }}"
- name: "Power Photovoltaics"
unit_of_measurement: W
device_class: power
state: "{{ states('sensor.solarnet_pv_leistung') | float(default=0) }}"
sensor:
- platform: integration
source: sensor.battery_power_charging
name: "Total Battery Energy Charged"
unique_id: 'myuuid_1234'
unit_prefix: k
method: left
- platform: integration
source: sensor.battery_power_discharging
name: "Total Battery Energy Discharged"
unique_id: 'myuuid_1235'
unit_prefix: k
method: left
- platform: integration
source: sensor.power_photovoltaics
name: "Total Photovoltaics Energy"
unique_id: 'myuuid_1236'
unit_prefix: k
method: left
In »configuration.yaml« müssen etliche Zeilen zusätzlicher Code eingebaut werden.
Damit die neuen Einstellungen wirksam werden, starten Sie den Home Assistant im Dialogblatt Einstellungen / System neu. Anschließend sollte es möglich sein, auch die Module Sonnenkollektoren und Batteriespeicher zu Hause richtig zu konfigurieren. (Bei meinen Experimenten hat es einen ganzen Tag gedauert hat, bis endlich alles zufriedenstellend funktionierte. Zwischenzeitlich habe ich zur Fehlersuche Einstellungen / System / Protokolle genutzt und musste unter Entwicklerwerkzeuge / Statistik zuvor aufgezeichnete Daten von falsch konfigurierten Sensoren wieder löschen.) Der Lohn dieser Art zeigt sich im Bild aus der Artikeleinleitung.
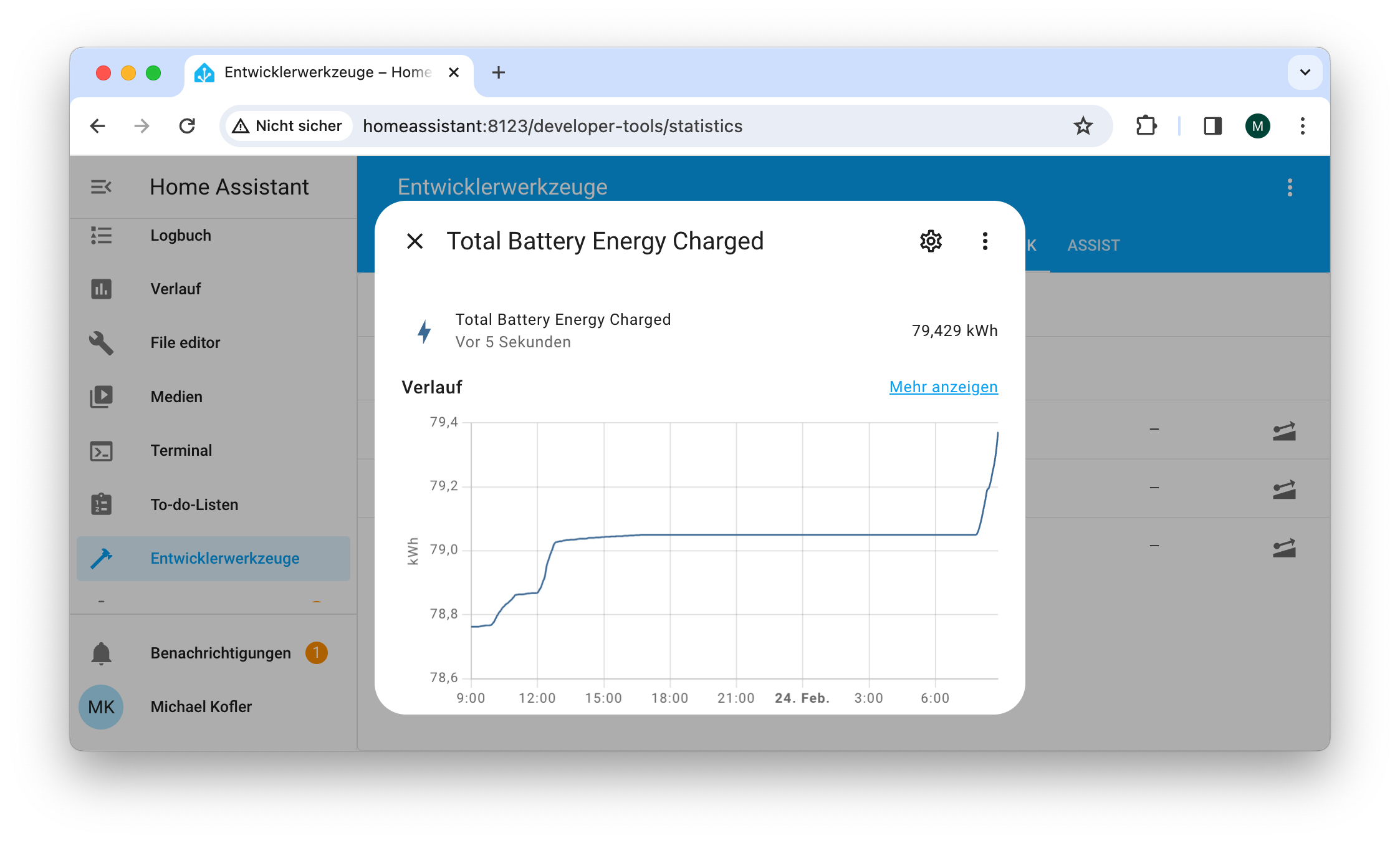
Unter Entwicklerwerkzeuge/Statistik können Sie sich vergewissern, dass die neuen Sensoren korrekt eingerichtet sind.Wenn ein Sensor angeklickt wird, erscheint eine Verlaufskurve.
Die MZLA Technologies Corporation hat mit Thunderbird 115.8 ein planmäßiges Update für seinen Open Source E-Mail-Client veröffentlicht.
Neuerungen von Thunderbird 115.8
Mit dem Update auf Thunderbird 115.8 hat die MZLA Technologies Corporation ein planmäßiges Update für seinen Open Source E-Mail-Client veröffentlicht. Das Update bringt diverse Fehlerbehebungen und Verbesserungen unter der Haube, welche sich in den Release Notes (engl.) nachlesen lassen. Auch wurden diverse Sicherheitslücken geschlossen.
Ich verwende KDE (also Plasma) als Desktop. Ich habe eh begrenzten vertikalen Platz (meine Bildschirme sind breiter als hoch), und durch ein Panel oben oder unten würde dieser Platz noch weniger werden. Daher habe ich mir ein seitliches Panel am linken Bildschirmrand eingerichtet.
#showyourdesktop
Sieht gut aus, oder?
Nachbauen
Um ein seitliches Panel zu erstellen führt ihr in einem leeren Bereich eures Desktops einen Rechtsklick aus und wählt “Kontrolleiste hinzfügen -> leere Kontrollleiste”.
Dies macht ihr so lange, bis eine seitliche Leiste links oder rechts entsteht (zuerst wird oben eine entstehen, dann links, dann rechts).
Die nicht benötigten neuen Leisten könnt ihr direkt wieder löschen.
Mein Panel hat eine Breite von 100
Widgets
Mein Panel besteht aus folgenden Widgets:
Panel
Widgets
Analoge Uhr
Digitale Uhr
Systemmonitor-Sensoren
Azeige-Stil: Gitter
Gitter-Stil: Liniendiagramm
Sensoren:
Gesamtauslastung
Warteauslastung
Download-Rate
Upload-Rate
Abstandhalter (Breite 10)
Systemabschnitt der Kontrollleiste
Abstandhalter
Fensterleiste
Anwendungsstarter
Weitere Desktopbilder finden sich bei Mastodon unter dem Hashtag #showyourdesktop. Wie sieht euer Desktop aus?
Bisher nur als Vorschlag eingereicht, möchte der COSMIC Desktop ein weiterer Spin im Reigen der Fedora Atomic Sammlung werden.
Seit Mitte Februar vereint Fedora seine immutable Spins unter dem Namen Fedora Atomic Desktops. Damit gibt es eine Sammlung aller Desktop-Varianten, die auf rpm-ostree aufbauen. rpm-ostree ist ein hybrides Image-/Paketsystem. Es kombiniert libostree als Basis-Image-Format und akzeptiert RPM sowohl auf der Client- als auch auf der Serverseite und teilt sich den Code mit dem dnf-Projekt, insbesondere libdnf.
Bisher gibt es bei Fedora Atomic Desktops die Varianten:
Fedora Silverblue (GNOME Desktop)
Fedora Kionite (KDE Plasma Desktop)
Fedora Sway Atomic (Sway Desktop)
Fedora Budgie Atomic (Budgie Desktop)
Neu hinzukommen soll Fedora COSMIC Atomic, basierend auf der neuen Cosmic Desktop Umgebung von System76, der im März erscheinen soll. Das Fedora-Team ist offen für andere Desktop-Umgebungen im Rahmen der Sammlung Fedora Atomic Desktops, und wie es aussieht, haben die Leute den Wink verstanden.
Vor ein paar Tagen wurde auf der offiziellen Fedora-Mailingliste ein Vorschlag vom unabhängigen Mitarbeiter, Ryan Brue, gemacht, der herausfinden wollte, ob genügend Interesse an der Gründung einer dedizierten COSMIC SIG für Fedora besteht. Eine Fedora SIG ist eine Special Interest Group, die Teil des Fedora-Projekts ist, das normalerweise als Ausgangspunkt für viele neue Projekte dient, bei denen sich Mitwirkende zusammentun und an der Erreichung einer Reihe von Zielen arbeiten können. Für die vorgeschlagene COSMIC SIG wären die Ziele die Erstellung von RPM-Paketen für die verschiedenen COSMIC-Komponenten, die Ausarbeitung eines Plans zur Förderung eines Fedora COSMIC Spins, die Mitwirkung an der Entwicklung von COSMIC und die Erstellung einer speziellen Fedora COSMIC Atomic Desktop Variante.
Ryan schreibt:
Mein Ziel ist es, kurz vor der Alpha-Veröffentlichung eine SIG für COSMIC zu entwickeln, hoffentlich ein paar Leute zu finden, die mir dabei helfen, rpms für COSMIC-Komponenten zu packen, und diese rpms dann zu verwenden, um eine Spin- UND eine atomare Variante zu erstellen (ich selbst bin eher ein Fan der atomaren Desktops). Momentan kompiliert mein COSMIC-Image alles manuell und legt die Dinge dort ab, wo sie im Dateisystem sein müssen, aber rpms sind das letztendliche Ziel.
Er hat bereits mit der Arbeit daran begonnen, indem er ein bestehendes Projekt eines System76-Entwicklers forkte, das auf einem OSTree-Image von Fedora Silverblue mit COSMIC DE basierte. Der Fork heißt Fedora Cosmic Atomic; ein Atomic-Desktop, der einen Pre-Alpha-Build von COSMIC DE enthält. Das kann man sich auf GitHub ansehen. Da die Veröffentlichung des Alpha-Builds von COSMIC kurz bevorsteht, sollte der Fedoras Spin es den Benutzern ermöglichen, die brandneue Desktop-Umgebung von System76 ohne Ubuntu zu nutzen.
Es lohnt sich nicht über ein Erscheinungsdatum zu schreiben, da sich der COSMIC Desktop immer noch in einem frühen und unfertigen Stadium befindet. Voraussichtlich werden wir die erste stabile Version basierend auf Ubuntu 24.04 im Laufe der nächsten Monate sehen. Da es sich bei Fedora COSMIC Atomic erst einmal um einen Vorschlag handelt, wird das Erscheinen sehr wahrscheinlich länger dauern.
GNU/Linux.ch ist ein Community-Projekt. Bei uns kannst du nicht nur mitlesen, sondern auch selbst aktiv werden. Wir freuen uns, wenn du mit uns über die Artikel in unseren Chat-Gruppen oder im Fediverse diskutierst. Auch du selbst kannst Autor werden. Reiche uns deinen Artikelvorschlag über das Formular auf unserer Webseite ein.
Am 16. und 17. März 2024 werde ich euch auf den Chemnitzer Linux-Tagen um 10:00 Uhr in Raum V6 mit einem Vortrag über IPv6 unterhalten.
Dazu bin ich noch auf der Suche nach ein paar Beispielen aus dem echten Leben. Falls ihr mögt, teilt mir doch eure schönsten und schlimmsten Momente im Zusammenhang mit IPv6 mit und ich prüfe, ob ich sie in meinen Vortrag mit einbauen kann.
Wann und wie hat IPv6 euren Tag gerettet?
Wieso hat euch das Protokoll Alpträume beschehrt?
Was funktioniert wider Erwarten immer noch nicht mit IPv6?
Habt ihr lustige Geschichten, die ihr (anonym) mit der Welt teilen möchtet?
Ich freue mich über Einsendungen, Beiträge und Rückmeldungen:
Bitte schreibt dazu, ob ihr eine Namensnennung wünscht oder euer Beispiel anonym einfließen soll.
Um einen runden Vortrag zu erstellen, wird evtl. nicht jeder Beitrag einfließen können. Bitte habt Verständnis dafür und verzeiht, wenn ihr euch nicht im Vortrag wiederfindet. Ich werde eure Geschichten ggf. im Nachgang hier im Blog veröffentlichen.
Als Folge der internen Umstrukturierung bei Mozilla wird es, anders als bisher geplant, keine eigenen Mastodon-Apps von Mozilla geben. Mozilla Social für Android wird jedoch unter dem Namen Firefly weiterentwickelt.
Vor wenigen Tagen hat Mozilla eine Umstrukturierung angekündigt, welche auch Mozillas Fediverse-Engagement betrifft. Während die eigene Mastodon-Instanz mozilla.social weiterhin betrieben wird, hat Mozilla die Entwicklung eigener Apps für Android und Apple iOS gestoppt.
Dabei ist vor allem um die Android-App sehr schade, deren Entwicklung bereits weiter fortgeschritten war und die seit dem 5. Januar als Alpha-Version getestet werden konnte. Noch am selben Tag hatte ich eine ausführliche Vorschau zum damaligen Stand der Entwicklung veröffentlicht und kam dabei zu dem Fazit, dass die App bereits einen sehr vielversprechenden Ersteindruck hinterlässt. Seit dem gab es einige Verbesserungen. Unter anderem wurden Benachrichtigungen innerhalb der App ergänzt.
Auch wenn Mozilla das Projekt gestoppt hat, scheint es für die Android-App dennoch weiterzugehen. So wird die App unter dem Namen Firefly von den Entwicklern der Original-App fortgeführt. Sobald hier die notwendige Bereinigung (wie eine Entfernung aller Mozilla-Referenzen) abgeschlossen ist, dürfte es im Firefly-Repository mit den Downloads neuer Versionen weitergehen.
Was die Entwicklung einer eigenen Mastodon-App für iOS betrifft, war die Entwicklung noch nicht so weit vorangeschritten. Ohnehin ging es dort bereits seit Mitte Januar nicht mehr weiter und es sah so aus, als hätte Mozilla die Ressourcen stattdessen in einen Fork der bereits existierenden Mastodon-App Ice Cubes gesteckt. Aber auch die Entwicklung des Forks wurde offiziell beendet. Abgesehen davon ist Mozilla auch Hauptinvestor der Mastodon-App Mammoth für iOS.
In eigener Sache: Dieser Blog auf Mastodon
Auch dieser Blog ist auf Mastodon vertreten. Wer mir folgen möchte, findet mich unter dem Namen @s_hentzschel@mozilla.social.
Wer IRC genutzt hat oder vielleicht noch nutzt, wird den Client HexChat kennen. Und sei es nur vom Namen her. Vor ein paar Tagen wurde Version 2.16.2 veröffentlicht. Was wohl die finale uns somit letzte Version darstellt.
Der Grund ist wie so oft der übliche. Das Projekt wurde längere Zeit nicht gewartet und niemand wollte den Job übernehmen.
Da der Code laut Ankündigung weiterhin auf Github vorhanden sein wird, hätte er auch nichts gegen einen Fork. Aus genannten Gründen und weil IRC heutzutage nicht mehr den Stellenwert hat den er früher hatte, wage ich es zu bezweifeln, dass jemand einen Fork erstellt. Zumindest keinen der längerfristig aktiv entwickelt wird.
Mozilla Hubs ist eine Plattform, um virtuelle Treffpunkte zu erstellen. Mozilla hat nun bekannt gegeben, wie genau es mit Hubs in Zusammenhang mit der Einstellung als Mozilla-Produkt weitergehen wird.
Was ist Mozilla Hubs?
Mit dem Start von Mozilla Hubs im April 2018 ging eine Online-Plattform an den Start, welche es Nutzern ermöglicht, sich in sogenannten Räumen virtuell zu treffen. Das Besondere an Hubs: es spielt sich komplett im Web ab – keine geschlossene Plattform, keine Installation einer Anwendung, keine Abhängigkeit von einem bestimmten Gerät. Einfach eine URL teilen und miteinander treffen. Hubs funktioniert in jedem Browser, am Smartphone – und auch mit der VR-Brille, wo Hubs als virtuelle Plattform sein volles Potenzial entfaltet. Mozilla Hubs ist quasi eine Miniatur-Ausgabe eines Web-basierten „Metaverse“, aber Open Source und mit Fokus auf Datenschutz, vom Macher des Firefox-Browsers.
So geht es mit Mozilla Hubs weiter
Vor wenigen Tagen hat Mozilla eine Umstrukturierung angekündigt, welche auch direkte Auswirkungen auf Mozilla Hubs hat. Nun hat Mozilla Details bekannt gegeben.
Mit dem 1. März 2024 wird Mozilla die Erstellung neuer Abonnements deaktivieren. Bestehende Kunden können ihre Instanz weiterhin nutzen. Am 1. April 2024 wird Mozilla ein Tool veröffentlichen, mit welchem sowohl Demo-Nutzer als auch Abonnenten ihre Daten herunterladen können. Am 31. Mai 2024 soll schließlich die Abschaltung von Mozilla Hubs erfolgen. Dies betrifft die Instanzen der Abonnenten, den Demo-Server sowie weitere von Mozilla betriebene Community-Ressourcen.
Die Hubs Community Edition, die seit Oktober 2023 verfügbar ist, ist als Open Source-Software zum selber Hosten nicht von Mozilla als Dienstleister abhängig. So hofft das Hubs-Team, dass die Software auch außerhalb von Mozilla eine Zukunft hat. Seitens Mozilla wird es ab dem 31. Mai 2024 jedoch keine Weiterentwicklungen und Fehlerbehebungen mehr geben.
Das geplante Tool zum Herunterladen der Daten soll alle mit der E-Mail-Adresse verknüpften Medien herunterladen können, einschließlich 3D-Modelle, Audiodateien, Bilddateien und Videodateien, die über Spoke hochgeladen wurden, sowie gLTFs von veröffentlichten Spoke-Szenen und Avataren. Das Tool wird es auch ermöglichen, alle Hubs-URLs abzurufen, einschließlich Szenen-URLs, Raum-URLs, Avatar-URLs und Spoke Projekt-URLs.
Von den Assets, die das Hubs-Team im Laufe der Jahre erstellt hat, sollen so viele wie möglich vor der Abschaltung als Open Source veröffentlicht werden.
Es ist so traurig, aber Firefox kennt wirklich nur noch eine Richtung, was die Marktanteile angeht. Dabei hat sich funktional in letzter Zeit so viel zum Besseren verändert und auch so manches Fehlverhalten von Mozilla hat sich verbessert.
Vor wenigen Tagen konnte man bei dem ausgewiesenen Mozilla-Experten Sören Hentzschel lesen, dass Mozilla nach dem unerwarteten Wechsel auf dem CEO-Posten mal wieder Leute entlässt, Dienste neu priorisiert und Firefox stärken will. Dies ist nur die jüngste Kehrtwende in einem jahrelangen Niedergang und seien wir ehrlich: Hätte Google nicht aus Wettbewerbsgründen ein Interesse am Überleben von Mozilla Firefox, hätte Alphabet die Kooperation mit Mozilla bei der Standardsuchmaschine schon längst beenden und dem Feuerfuchs den Todesstoß versetzen können.
Natürlich kommen jetzt wieder die üblichen Nörgler mit irgendwelchen Geschichte von vor dem Krieg, die sich in der Community schon lange verselbständigt haben. Damals als Mozilla die Extensions getötet hat, weshalb “Millionen” User abgewandert sind, weil man ohne drölfzig Extensions das Internet nicht nutzen kann oder damals als das Design geändert wurde. Wer kann schon ohne Menübar professionell arbeiten. Wir kennen das alles. Ich halte das für Quatsch, für den sich eine kleine Minderheit zu wichtig nimmt.
Sicherlich hat Mozilla einige fragwürdige Entscheidungen getroffen. Das Hin und Her mit Thunderbird, die Pocket-Geschichte, die zähe Entwicklung, als man noch erfolgreich war. Man könnte sicher einiges aufzählen. Aber Firefox war bereits auf dem absteigenden Ast und Mozilla stand unter Druck. In dieser Situation werden manchmal Entscheidungen getroffen, die sich im Nachhinein als falsch herausstellen. Die Geschichte ist immer offen und es ist immer leicht, sich im Nachhinein hinzustellen und alles besser gewusst zu haben.
Die Ursache für die Misere liegt aber woanders und das wird immer wieder thematisiert. Firefox ist ein Opfer der Entwicklungen im Mobilbereich. Immer weniger Menschen nutzen Desktopsysteme, immer mehr Menschen arbeiten nur noch mit Smartphones und Tablets. Es ist nicht so als ob Mozilla es nicht versucht hätte, aber alternative Systeme wie damals Firefox OS hatten keine Chance. Nichts besteht neben dem Duopol aus Android und iOS. Apple und Google haben mit ihren Systemen eine unangefochtene Dominanz und diktieren den Standardbrowser. Nur sehr wenige Menschen installieren hier überhaupt Alternativen und bei iOS war das dann bis zuletzt sogar nur die Oberfläche, weil die Apple-Engine festgelegt war.. Die Regulierungsbehörden haben das Thema viel zu lange missachtet und das was jetzt aus Brüssel kommt ist vermutlich zu wenig und zu spät.
Schaut man sich die Zahlen an, dann ist das aber noch ernüchternder als ich vermutete. Für Deutschland kommt Statista noch auf wenigstens 18% und der Sinkflug hat sich zuletzt auch verlangsamt. Weltweit sind es deutlich unter 10%. Selbst Apples Safari liegt hier deutlich vor dem traditionsreichen Open-Source-Browser. Jetzt kann man sagen, dass Statista halt auch nur eine Quelle ist und irgendwelche “gefühlten” Zahlen angeben. Ich führe aus datenschutzgründen nur eine sehr rudimentäre Statistik, die ziemlich fehleranfällig ist, weil sie auf Fingerprinting und Cookies verzichtet, aber selbst die Logs hier ergeben nur noch circa 25% für Firefox und über 40% für Chrome.
Das hat mich doch überrascht, weil Firefox bei Linux immer noch der Standardbrowser unter allen Distributionen ist und oft auch der einzig richtig gut mit Sicherheitsupdates versorgte Weg ins Internet. Zudem lässt sich Firefox immer noch deutlich besser für eine privatsphäre- und datenschutzorientierte Nutzungsweise konfigurieren als die meisten Chromium-Varianten (Brave, Vivalid, Ungoogled Chromium etc.). Bei der Zielgruppe dieser Seite hätte ich daher mehr Firefox-Nutzer vermutet. Zuletzt hat man hier im Bereich Trackingschutz einiges richtig gemacht und die neu eingeführte automatische Cookiebannersteuerung ist auch vielversprechend.
Eine Umkehr werden wir nicht mehr erleben. Für die Zukunft ist das bedenklich, weil Google seine Torwächterfunktion immer hemmungsloser ausnutzen kann. Zuletzt kommentierte ich dies anlässlicher der Blockade von Drittanbieter-Cookies. Ob Abspaltungen von Chromium wirklich eigenständig lebensfähig sind und sich fragwürdigen Entscheidungen von Google konsequent widersetzen können, wird sich noch zeigen. Wir werden es vermutlich zeitnah bei den Werbeblockern sehen.
Mozilla hat Version 2.20 seiner VPN-Clients für das Mozilla VPN veröffentlicht. Dieser Artikel beschreibt die Neuerungen vom Mozilla VPN 2.20.
Mit dem Mozilla VPN bietet Mozilla in Zusammenarbeit mit Mullvad sein eigenes Virtual Private Network an und verspricht neben einer sehr einfachen Bedienung eine durch das moderne und schlanke WireGuard-Protokoll schnelle Performance, Sicherheit sowie Privatsphäre: Weder werden Nutzungsdaten geloggt noch mit einer externen Analysefirma zusammengearbeitet, um Nutzungsprofile zu erstellen.
Mit dem Update auf das Mozilla VPN 2.20 ist es bei Nutzung eines Monats-Abos nun innerhalb der App möglich, ein Upgrade auf ein Jahres-Abo vorzunehmen. Ansonsten bringt das Update vor allem Fehlerbehebungen sowie Verbesserungen unter der Haube.
Viele, die sich überlegen Linux zu nutzen bzw. die Linux erst seit kurzer Zeit verwenden, stellen sich die Frage wie sie helfen können. Meist führt das zu der Frage, welche Programmiersprache man kennen muss. Meine Antwort lautet, keine.
Viele Neulinge finden es beispielsweise erstrebenswert möglichst bald Änderungen am Linux-Kernel vorzunehmen. Ich sage, lasst es sein. Zumindest vorerst. Denn wenn es um den Kernel geht, arbeiten daran schon viele Leute, die euch deutlich überlegen sind. Und nein, ich bin keiner davon.
Meiner Meinung nach gibt es wichtigere Dinge.
Zum Beispiel das Erstellen einer guten Dokumentation für Endbenutzer für ein bestimmtes Programm. Denn viele Programmierer sind zwar gut, wenn es um das Programmieren geht. Aber sie sind unfähig oder unwillig eine gute Dokumentation zu erstellen.
Was auch oft fehlt, ist die Übersetzung einer grafischen Oberfläche eines Programms in eine andere Sprache als Englisch. Wer also sprachlich begabt ist, kann sich bei unzähligen Projekten austoben.
Oder offene “Issues”. Bei vielen Projekten sind oft sehr viele Issues noch offen. Viele dieser “Probleme” werden von Nutzern erzeugt, weil sie das Programm falsch benutzt. Andere hingegen, wurden zwischenzeitlich aufgrund einer anderen Meldung bereits behoben, aber nicht alle Issues geschlossen. Hier zu testen, ob ein gemeldetes Problem noch aktuell ist, kann den Entwicklern ebenfalls helfen. Oder vielleicht könnt ihr ein Problem sogar selbst beheben und den entsprechenden Code beisteuern.
Vielleicht denkt sich nun der eine oder andere Leser dieses Artikels, dass es vielleicht doch sinnvoller ist, nicht gleich am Kernel zu arbeiten. Aber er stellt sich die Frage, wo anfangen? Im Grunde ist das ganz einfach. Schaut euch an, welche Programme ihr selbst nutzt. Dann schaut euch beispielsweise die Issues an. Oder prüft, ob die grafische Oberfläche auch in einer Sprache angeboten wird, die ihre sprecht und ob es Verbesserungsmöglichkeiten gibt. Oder helft Leuten bei Ihren Problemen. Oder veröffentlicht Artikel zu bestimmten Dingen die es nicht schon unzählige Male im Internet gibt.
Ich persönlich habe ehrlich gesagt mehr Respekt vor Leuten die sich um solche “niederen Aufgaben” kümmern als vor den Leuten die gleich nach der ersten Installation einer Linux-Distribution am Kernel mitarbeiten wollen. Denn ohne die kleinen Zahnräder funktionieren auch die großen meist nicht.
Seit drei Jahren arbeitet das unabhängige Entwicklerteam hinter Asahi Linux daran, Linux auf Apple Silicon Macs lauffähig zu machen.
Anfänglich war Asahi Linux ein "instabiles Experiment", mittlerweile ist es aber ein überraschend funktionales und benutzbares Desktop-Betriebssystem geworden. Sogar Linus Torvalds, der Schöpfer von Linux, hat es benutzt, um Linux auf Apples Hardware laufen zu lassen. Apple selbst beteiligt sich nicht an diesem Projekt.
Seit Dezember 2022 hat das Team seinen Open-Source-GPU-Treiber für die M1- und M2-Chips stetig verbessert. Nun hat es einen wichtigen Meilenstein erreicht: Die OpenGL- und OpenGL ES-Unterstützung des Asahi-Treibers ist wieder einmal besser als die von Apple in macOS. Der neueste Asahi-Treiber unterstützt OpenGL 4.6 und OpenGL ES 3.2, die neuesten Versionen dieser APIs. Apples macOS hingegen unterstützt nur OpenGL 4.1, das schon seit 2010 aktuell ist.
Die Entwicklerin Alyssa Rosenzweig erklärt in einem Blogbeitrag, warum die Implementierung der neueren APIs auf Apples GPUs so schwierig war. Trotz der Herausforderungen hat das Asahi-Team es geschafft, einen performanten und konformen Treiber zu entwickeln. Als Nächstes will das Team Vulkan unterstützen, eine moderne Grafik-API mit geringem Overhead. Vulkan ist in macOS nur mit Übersetzungsschichten wie MoltenVK verfügbar, die die Leistung beeinträchtigen können.
Asahi Linux ist noch nicht perfekt. Es gibt einige Funktionen, die noch nicht funktionieren, z. B. Thunderbolt und Touch ID. Trotzdem ist es eine beeindruckende Leistung, dass ein kleines Team von Entwicklern so viel erreicht hat.
Asahi Linux macht Apple Silicon Macs zu einer attraktiven Option für Linux-Benutzer. Die überlegene OpenGL-Unterstützung und die bevorstehende Vulkan-Unterstützung sind wichtige Fortschritte, die Linux auf dieser Plattform noch attraktiver machen.
GNU/Linux.ch ist ein Community-Projekt. Bei uns kannst du nicht nur mitlesen, sondern auch selbst aktiv werden. Wir freuen uns, wenn du mit uns über die Artikel in unseren Chat-Gruppen oder im Fediverse diskutierst. Auch du selbst kannst Autor werden. Reiche uns deinen Artikelvorschlag über das Formular auf unserer Webseite ein.
Mozilla steht vor einer Umstrukturierung. Wenige Tage nach der Ernennung einer neuen CEO streicht Mozilla 60 Stellen und kürzt Investitionen in manchen Bereichen, um dafür stärker in andere Bereiche zu investieren. Mozilla Hubs wird eingestellt.
Vor wenigen Tagen hat Mozilla die Ernennung von Laura Chambers als neue CEO der Mozilla Corporation angekündigt. Heute hat Mozilla die Mitarbeiter über eine Umstrukturierung informiert. Demnach werden 60 Stellen gestrichen, was in etwa fünf Prozent der Gesamtbelegschaft entsprechen soll.
So möchte Mozilla in manchen Produktbereichen weniger investieren, um sich stärker auf andere Bereiche zu konzentrieren. Am stärksten davon betroffen ist Mozilla Hubs, was im Laufe des Jahres eingestellt werden soll. Aber auch die Investitionen in die eigene Mastodon-Instanz mozilla.social, das Mozilla VPN, Firefox Relay und den letzte Woche in den USA erst gestarteten Dienst zur Entfernung persönlicher Informationen von Personen-Suchmaschinen sollen laut TechCrunch reduziert werden.
Firefox Mobile wird in einem Statement von Mozilla (via Bloomberg) explizit als Produkt genannt, welches dafür mehr Ressourcen erhalten soll. Auch das Thema Künstliche Intelligenz und KI-Integration in Firefox wird einen noch stärkeren Fokus als bisher einnehmen. Zu diesem Zweck werden die Teams, die an Pocket, Content sowie Künstliche Intelligenz / Maschinellem Lernen arbeiten, mit der Firefox-Organisation zusammengeführt.
Wie sich das Ganze konkret auswirken wird, bleibt abzuwarten. Während sich einige Firefox-Fans darüber freuen werden, dass der Browser als Hauptprodukt einmal mehr einen stärkeren Fokus erhalten soll, klingt dies gleichzeitig nach einem signifikanten Strategiewechsel, der eine Diversifizierung der Einnahmequellen nicht länger priorisiert.
Das vollständige interne Memo (via TechChrunch), übersetzte Fassung:
Zurückfahren der Investitionen in mozilla.social: Mit mozilla.social gingen wir 2023 eine große Wette ein, um eine sicherere, bessere Social-Media-Erfahrung zu schaffen, die auf Mastodon und dem Fediverse basiert. Unser anfänglicher Ansatz basierte auf der Überzeugung, dass Mozilla schnell ein großes Ausmaß erreichen muss, um die Zukunft der sozialen Medien effektiv gestalten zu können. Das war eine edle Idee, aber wir hatten Schwierigkeiten, sie umzusetzen. Wir haben mozilla.social zwar stark mit Ressourcen ausgestattet, um diese ehrgeizige Idee zu verfolgen, aber im Nachhinein betrachtet hätte uns ein bescheidenerer Ansatz ermöglicht, mit wesentlich größerer Agilität an diesem Bereich teilzunehmen. Die Maßnahmen, die wir heute ergreifen, werden diese strategische Korrektur vornehmen, indem wir mit einem viel kleineren Team arbeiten, um am Mastodon-Ökosystem teilzunehmen und kleinere Experimente schneller zu den Menschen zu bringen, die sich für die mozilla.social-Instanz entscheiden.
Schutz, Experimentieren und Identität (PXI): Wir reduzieren die Investitionen in einige unserer eigenständigen Verbraucherprodukte im Bereich Sicherheit und Datenschutz. Wir reduzieren unsere Investitionen in Marktsegmenten, die von Wettbewerbern verdrängt werden und in denen es schwierig ist, ein differenziertes Angebot zu liefern. Konkret planen wir, unsere Investitionen in VPN, Relay und Online Footprint Scrubber zu reduzieren. Wir werden weiterhin in Produkte investieren, die den Kundenbedürfnissen in wachsenden Marktsegmenten entsprechen.
Hubs: Seit Anfang 2023 haben wir eine Verschiebung des Marktes für virtuelle 3D-Welten erlebt. Mit Ausnahme von Spielen, Bildung und einer Handvoll Nischenanwendungen hat sich die Nachfrage von virtuellen 3D-Welten entfernt. Dies wirkt sich auf alle Akteure der Branche aus. Die Benutzer- und Kundenbasis von Hubs ist nicht robust genug, um den weiteren Einsatz von Ressourcen gegen den Gegenwind der ungünstigen Nachfrageverschiebung zu rechtfertigen. Wir werden den Dienst abwickeln und den Kunden einen Plan für einen geordneten Ausstieg mitteilen.
Verkleinerung des Mitarbeiterteams: In Anbetracht des Personalabbaus und des geringeren Budgets für die Mitarbeiterzahl bei MozProd wurden einige Funktionen in der Personalabteilung und anderen Support-Organisationen konsolidiert, damit wir unserem Produktportfolio das richtige Maß an Unterstützung bieten können. Optimierung unserer Organisation, um den Fokus zu schärfen.
Im Jahr 2023 begann die generative KI, die Industrielandschaft schnell zu verändern. Mozilla ergriff die Gelegenheit, vertrauenswürdige KI in Firefox einzubringen, vor allem durch die Übernahme von Fakespot und die darauf folgende Produktintegration. Darüber hinaus ist die Suche nach großartigen Inhalten immer noch ein wichtiger Anwendungsfall für das Internet. Daher werden wir als Teil der heutigen Änderungen Pocket, Content und die KI/ML-Teams, die Inhalte unterstützen, mit der Firefox-Organisation zusammenführen. Weitere Details zu den spezifischen organisatorischen Änderungen werden in Kürze folgen. Innerhalb von MozProd gibt es keine Änderungen bei MDN, Ads oder Fakespot. Auch in den Bereichen Legal/Policy, Finance & Business Operations, Marketing und Strategy & Operations gibt es keine Änderungen.
Diese Änderung wird es der UBports Foundation ermöglichen, Fehler- und Sicherheitskorrekturen schneller als bisher bereitzustellen, um ein stabileres und zuverlässigeres Ubuntu Touch-Erlebnis zu gewährleisten.
Die UBports Foundation hat gestern angekündigt, dass sie für zukünftige OTA (Over-the-Air)-Updates für ihr mobiles Betriebssystem Ubuntu Touch zu einem Fixed-Release-Modell wechseln wird.
Vor fast einem Jahr hat die UBports Foundation das erste Ubuntu Touch OTA-Update auf Basis von Ubuntu 20.04 LTS veröffentlicht, nachdem sie jahrelang an der Migration von der Ubuntu 16.04 (Xenial Xerus) Serie gearbeitet hatte. Dieser Schritt brachte viele Vorteile für die Nutzer von Ubuntu Touch mit sich, führte aber auch einige Probleme mit sich, wie z.B. die Tatsache, dass sie keine individuellen Fehlerbehebungen oder Sicherheitslücken veröffentlichen können, ohne alle anderen Änderungen, die in der Codebasis gelandet sind, zu veröffentlichen oder die Tatsache, dass sie die Entwicklung einfrieren müssen, wenn ein neues OTA-Update erscheint.
Um diese Probleme, die durch die Umstellung von Ubuntu 16.04 auf Ubuntu 20.04, auf dem die aktuellen Ubuntu Touch-Builds basieren, zu beheben, hat die UBports Foundation einen Plan entwickelt, um zu einem Fixed-Release-Modell zu wechseln, wenn sie Ubuntu Touch auf die kommende Ubuntu 24.04 LTS (Noble Numbat) Version umstellen.
"Mit dem bevorstehenden Upgrade des Basis-Betriebssystems Ubuntu 24.04 nehmen wir die Gelegenheit wahr, unser Release-Modell zu ändern: Wir planen, auf das Fixed-Release-Modell umzustellen", so die UBports Foundation.
Diese Änderung hat keinerlei Auswirkungen auf Ubuntu Touch Nutzer. Der Wechsel zu einem Fixed-Release-Modell ermöglicht es der UBports Foundation, Fehler- und Sicherheitskorrekturen schneller als bisher bereitzustellen, um die Stabilität und Zuverlässigkeit von Ubuntu Touch zu erhöhen.
Das neue Ubuntu Touch Versionsmodell wird das Format <Jahr>.<Monat>.<Minor> verwenden, wobei die <Jahr> und <Monat> Versionsstrings mit dem erwarteten Jahr und Monat der jeweiligen Version nummeriert und der <Minor> Versionsstring bei 0 beginnt (z.B. 24.6.0), wobei Minor Releases um 1 erhöht werden.
Die UBports Foundation sagte auch, dass sie plant, alle sechs Monate ein grosses Funktionsupdate für Ubuntu Touch zu veröffentlichen und alle zwei Monate eine kleinere Version. Sie sagten auch, dass jede grössere Funktionsaktualisierung etwa einen Monat lang unterstützt wird, nachdem die nächste grössere Funktionsaktualisierung veröffentlicht wurde.
GNU/Linux.ch ist ein Community-Projekt. Bei uns kannst du nicht nur mitlesen, sondern auch selbst aktiv werden. Wir freuen uns, wenn du mit uns über die Artikel in unseren Chat-Gruppen oder im Fediverse diskutierst. Auch du selbst kannst Autor werden. Reiche uns deinen Artikelvorschlag über das Formular auf unserer Webseite ein.
Nachdem ich mich vor ein paar Wochen ausführlich mit der Installation von Fedora Asahi Linux auseinandergesetzt habe, geht es jetzt um die praktischen Erfahrungen. Der Artikel ist ein wenig lang geworden und geht primär auf Tools ein, die ich in meinem beruflichen Umfeld oft brauche.
Ich habe mich für die Gnome-Variante von Fedora Asahi Linux entschieden, die grundsätzlich ausgezeichnet funktioniert. Dazu aber gleich eine Einschränkung: Der Asahi-Entwickler Hector Martin ist KDE-Fan; insofern ist die KDE-Variante besser getestet und sollte im Zweifelsfall als Desktop-System vorgezogen werden.
Gnome Systemeinstellungen
Hardware-Unterstützung
Asahi Linux unterstützt aktuell noch keine Macs mit M3-CPUs. Außerdem hapert es noch bei USB-C-Displays (HDMI funktioniert), einigen Thunderbolt-/USB4-Features und der Mikrofon-Unterstützung. (Die Audio-Ausgabe funktioniert, bei den Notebooks anscheinend sogar in sehr hoher Qualität. Aus eigener Erfahrung kann ich da beim Mac Mini nicht mitreden, dessen Lautsprecher ist ja nicht der Rede wert.) Auf die Authentifizierung mit TouchId müssen Sie auch verzichten. Einen guten Überblick über die Hardware-Unterstützung finden Sie am Ende der folgenden Seite:
Ich habe Fedora Asahi Linux nur auf einem Mac Mini M1 getestet (16 GB RAM). Damit habe ich sehr gute Erfahrungen gemacht. Das System ist genauso leise wie unter macOS (sprich: lautlos, auch wenn der Lüfter sich immer minimal dreht). Aber ich kann keine Aussagen zur Akku-Laufzeit machen, weil ich aktuell kein MacBook besitze. Wie gut Linux die Last zwischen Performance- und Efficiency-Cores verteilt, kann ich ebenfalls nicht sagen.
Der Ruhezustand funktioniert, auch das Aufwachen ;-) Dazu muss allerdings kurz die Power-Taste gedrückt werden. Ein Tastendruck oder ein Mausklick reicht nicht.
Tastatur
An meinem Mac Mini ist eine alte Apple-Alu-Tastatur angeschlossen. Grundsätzlich funktioniert sie auf Anhieb. Ein paar kleinere Optimierungen habe ich vor einiger Zeit hier beschrieben.
Konfiguration bei der Linux-Installation
Ich habe ja schon in meinem Blog-Beitrag zur Installation festgehalten: Während der Installation von Fedora gibt es praktisch keine Konfigurationsmöglichkeiten. Insbesondere können Sie weder die Partitionierung noch das Dateisystem beeinflussen (es gibt eine Partition für alles, das darin enthaltene Dateisystem verwendet btrfs ohne Verschlüsselung).
Wenn Sie davon abweichende Vorstellungen haben und technisch versiert sind, können Sie anfänglich nur einen Teil des freien Disk-Speichers für das Root-System von Fedora nutzen und später eine weitere Partition (z.B. für /home) nach eigenen Vorstellungen hinzuzufügen.
Swap-File
Während der Installation wurde auf meinem System die Swap-Datei /var/swap/swapfile in der Größe von 8 GiB eingerichtet (halbe RAM-Größe?). Außerdem verwendet Fedora standardmäßig Swap on ZRAM. Damit kann Fedora gerade ungenutzte Speicherseite in ein im RAM befindliches Device auslagern. Der Clou: Die Speicherseiten werden dabei komprimiert.
Beim meiner Konfiguration (16 GiB RAM, 8 GiB Swap-File, 8 GiB ZRAM-Swap) glaubt das System, dass es über fast 32 GiB Speicherplatz verfügen kann. (Etwas RAM wird für das Grafiksystem abgezwackt.) Ganz geht sich diese Rechnung natürlich nicht aus, weil ja das ZRAM-Swap selbst wieder Arbeitsspeicher kostet. Aber sagen wir 4 GB ZRAM entspricht mit Komprimierung 8 GB Speicherplatz + 11 GB restliches RAM + 8 GB Swapfile: das würde 27 GB Speicherplatz ergeben. Wenn nicht alle Programme zugleich aktiv sind, kann man damit schon arbeiten.
cat /proc/swaps
Filename Type Size Used Priority
/var/swap/swapfile file 8388576 0 -2
/dev/zram0 partition 8388592 0 100
free -m
total used free shared buff/cache available
Mem: 15444 8063 2842 1521 7112 7381
Swap: 16383 0 16383
Weil ich beim Einsatz virtueller Maschinen gescheitert bin (siehe unten), kann ich nicht beurteilen, ob diese Konfiguration mit der Arbeitsspeicherverwaltung von macOS mithalten kann. Die funktioniert nämlich richtig gut. Auch macOS komprimiert Teile des gerade nicht genutzten Speichers und kompensiert so (ein wenig) den unendlichen Apple-Geiz, was die Ausstattung mit RAM betrifft (oder die Geldgier, wenn mehr RAM gewünscht wird).
Gnome Systemüberwachung
Gnome + Fractional Scaling: mühsam wie vor 10 Jahren
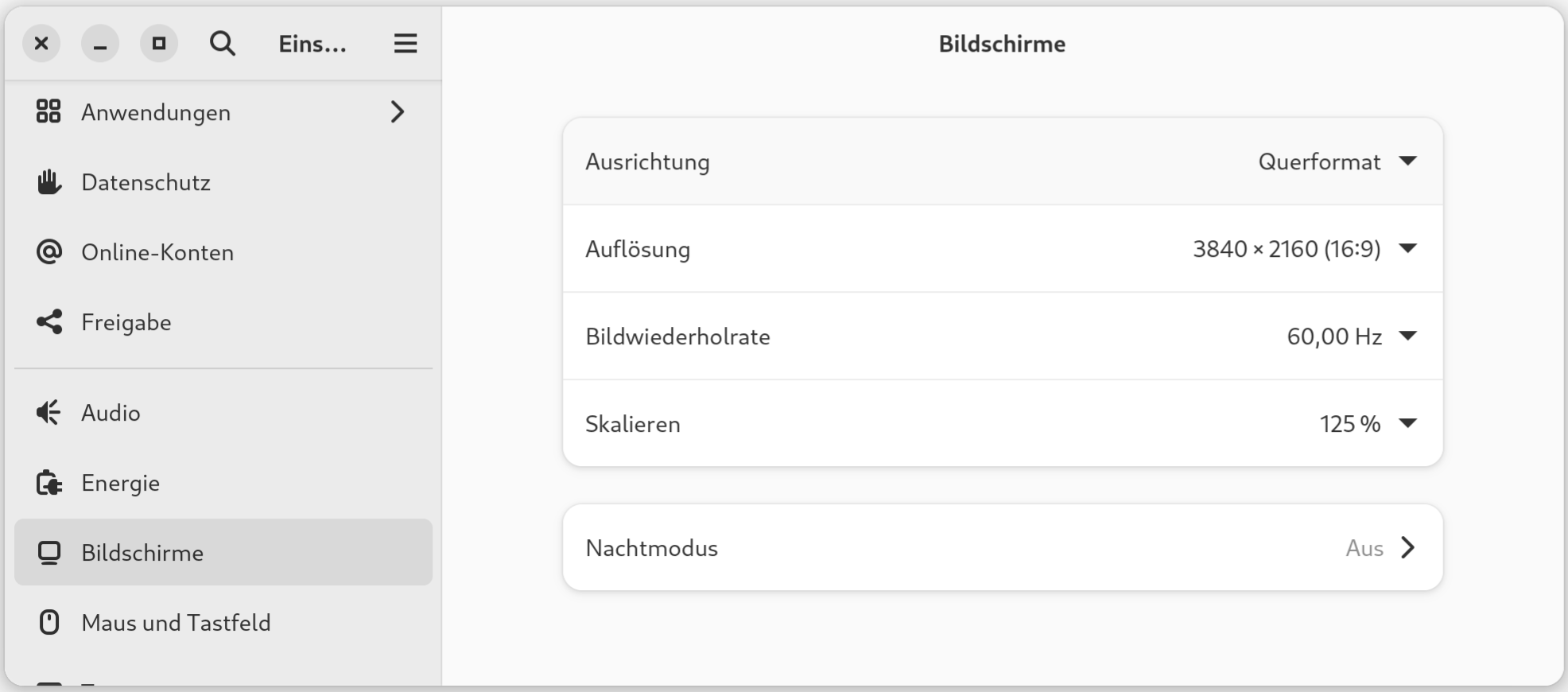
Ein altes Problem: Auf meinem 4k-Monitor (27 Zoll) ist der Bildschirminhalt bei einer Skalierung von 100 % arg klein, bei 200 % sinnlos groß. Seit Jahren wird gepredigt, wie toll Gnome + Wayland ist, aber Fractional Scaling funktioniert immer noch nicht standardmäßig?
Dieses Problem lässt sich zum Glück lösen:
gsettings set org.gnome.mutter experimental-features "['scale-monitor-framebuffer']"
Aus Gnome ausloggen, neu einloggen. Jetzt können in den Systemeinstellungen 125 % eingestellt, optimal für mich.
Die fraktionelle Skalierung funktioniert für Wayland-Programme gut, sie muss aber umständlich aktiviert werden
Die meisten Programme, die ich üblicherweise verwende, kommen mit 125 % gut zurecht. Wichtigste Ausnahme (für mich): Emacs. Die Textdarstellung ist ziemlich verschwommen. Angeblich gibt es eine Wayland-Version von Emacs (siehe hier), aber ich habe noch nicht versucht, sie zu installieren.
Webbrowser: kein Google Chrome
Als Webbrowser ist standardmäßig Firefox installiert und funktioniert ausgezeichnet. Chromium steht alternativ auch zur Verfügung (dnf install chromium). Ich bin allerdings, was den Webbrowser betrifft, in der Google-Welt zuhause. Ich habe mich vor über 10 Jahren für Google Chrome entschieden. Lesezeichen, Passwörter usw. — alles bei Google. (Bitte die Kommentare nicht für einen Browser-Glaubenskrieg nutzen, ich werde keine entsprechenden Kommentare freischalten.)
Insofern trifft es mich hart, dass es aktuell keine Linux-Version von Google Chrome für arm64 gibt. Ich habe also die Bookmarks + Passwörter nach Firefox importiert. Bookmarks sind easy, Passwörter müssen in Chrome in eine CSV-Datei exportiert und in Firefox wieder importiert werden. Mit etwas Webrecherche auch nicht schwierig, aber definitiv umständlich. Und natürlich ohne Synchronisation. (Für alle Firefox-Fans: Ja, auch Firefox funktioniert großartig, ich habe überhaupt keine Einwände. Wenn ich die Entscheidung heute treffen würde, wäre vielleicht Firefox der Gewinner. Google bekommt auch so genug von meinen Daten …)
Drag&Drop von Nautilus nach Firefox funktionierte bei meinen Tests nicht immer zuverlässig. Ich glaube, dass es sich dabei um ein Wayland-Problem handelt. Ähnliche Schwierigkeiten hatte ich auf meinen »normalen« Linux-Systemen (also x86) mit Google Chrome auch schon, wenn Wayland im Spiel war.
Nextcloud: perfekt
Zum Austausch meiner wichtigsten Dateien zwischen diversen Rechnern verwende ich Nextcloud. Ich habe nextcloud-client-nautilus installiert und eingerichtet, funktioniert wunderbar. Damit im Panel das Nextcloud-Icon angezeigt wird, ist die Gnome-Erweiterung AppIndicator and KStatusNotifierItem Support erforderlich.
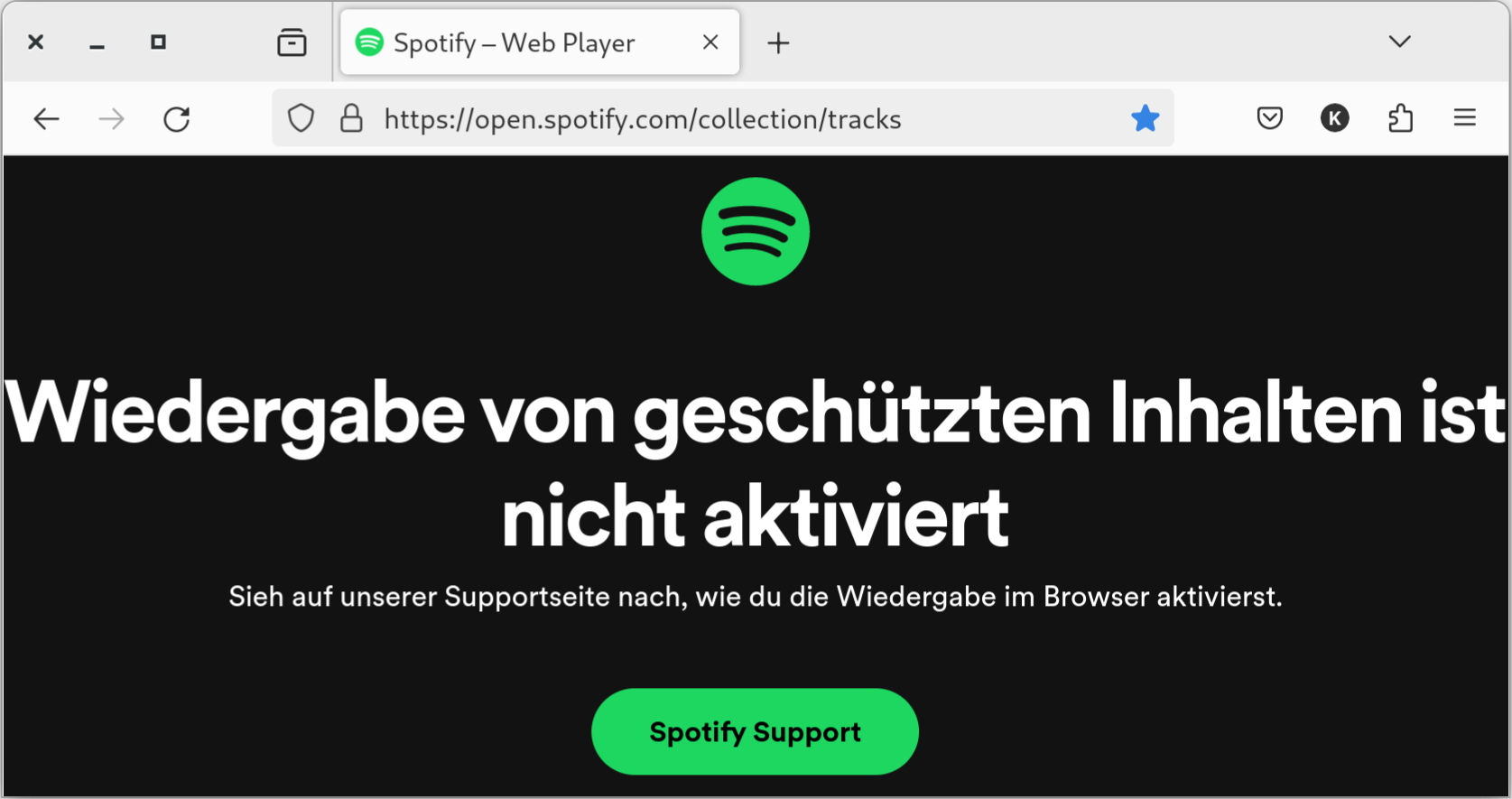
Spotify + Firefox: gescheitert
Ich höre beim Arbeiten gerne Musik. Die Spotify-App gibt es nicht für arm64. Kein Problem, ich habe mich schon lange daran gewöhnt, Spotify im Webbrowser auszuführen. Aber Spotify hält nichts von Firefox: Wiedergabe von geschützten Inhalten ist nicht aktiviert.
Spotify und Firefox vertragen sich nicht
Das Problem ist bekannt und gilt eigentlich als gelöst. Es muss das Widevine-Plugin installiert werden. Asahi greift dabei auf ein Paket der ChromeBooks zurück. Es kann mit widevine-installer installiert werden. (widevine-installer befindet sich im gleichnamigen Paket und ist standardmäßig installiert.) Gesagt, getan:
sudo widevine-installer
This script will download, adapt, and install a copy of the Widevine
Content Decryption Module for aarch64 systems.
Widevine is a proprietary DRM technology developed by Google.
This script uses ARM64 builds intended for ChromeOS images and is
not supported nor endorsed by Google. The Asahi Linux community
also cannot provide direct support for using this proprietary
software, nor any guarantees about its security, quality,
functionality, nor privacy. You assume all responsibility for
usage of this script and of the installed CDM.
This installer will only adapt the binary file format of the CDM
for interoperability purposes, to make it function on vanilla
ARM64 systems (instead of just ChromeOS). The CDM software
itself will not be modified in any way.
Widevine version to be installed: 4.10.2662.3
...
Installing...
Setting up plugin for Firefox and Chromium-based browsers...
Cleaning up...
Installation complete!
Please restart your browser for the changes to take effect.
Nach einem Firefox-Neustart ändert sich: nichts. Ein weiterer Blick in discussion.fedoraproject.org verrät: Es muss auch der User Agent geändert werden, d.h. Firefox muss als Betriebssystem ChromeOS angeben:
Es gibt zwei Möglichkeiten, den User Agent zu ändern. Die eine besteht darin, die Seite about:config zu öffnen, die Option general.useragent.override zu suchen und zu ändern. Das gilt dann aber für alle Webseiten, was mich nicht wirklich glücklich macht.
Die Alternative besteht darin, ein UserAgent-Plugin zu installieren. Ich habe mich für den User-Agent Switcher and Manager entschieden.
Langer Rede kurzer Sinn: Mit beiden Varianten ist es mir nicht gelungen, Spotify zur Zusammenarbeit zu überreden. An dieser Stelle habe ich nach rund einer Stunde Frickelei aufgegeben. Es gibt im Internet Berichte, wonach es funktionieren müsste. Vermutlich bin ich einfach zu blöd.
Spotify + Chromium: geht
Da wollte ich Firefox eine zweite Chance geben … Stattdessen Chromium installiert, damit funktioniert Spotify (widevine-installer vorausgesetzt) auf Anhieb. Sei’s drum.
Chromium läuft übrigens standardmäßig als X-Programm (nicht Wayland), aber nachdem ich den Browser aktuell nur als Spotify-Player benutze, habe ich mir nicht die Mühe gemacht, das zu ändern.
Wie Emacs und Chromium läuft auch Code vorerst als X-Programm. Entsprechend unscharf ist die Schrift bei 125% Scaling. Das ArchWiki verrät, dass beim Programmstart die Option --ozone-platform-hint=auto übergeben werden muss. Das funktioniert tatsächlich: Plötzlich gestochen scharfe Schrift auch in Code.
Ich habe mir eine Kopie von code.desktop erstellt und die gerade erwähnte Option in die Exec-Zeile eingebaut. Bingo!
qemu/libvirt/virt-manager: keine Grafik, keine Maus, keine Tastatur, kein Glück
Meine Arbeit spielt sich viel in virtuellen Maschinen und Containern ab. QEMU und die libvirt-Bibliotheken sind standardmäßig installiert, die grafische VM-Verwaltung gibt es mit dnf install virt-manager dazu.
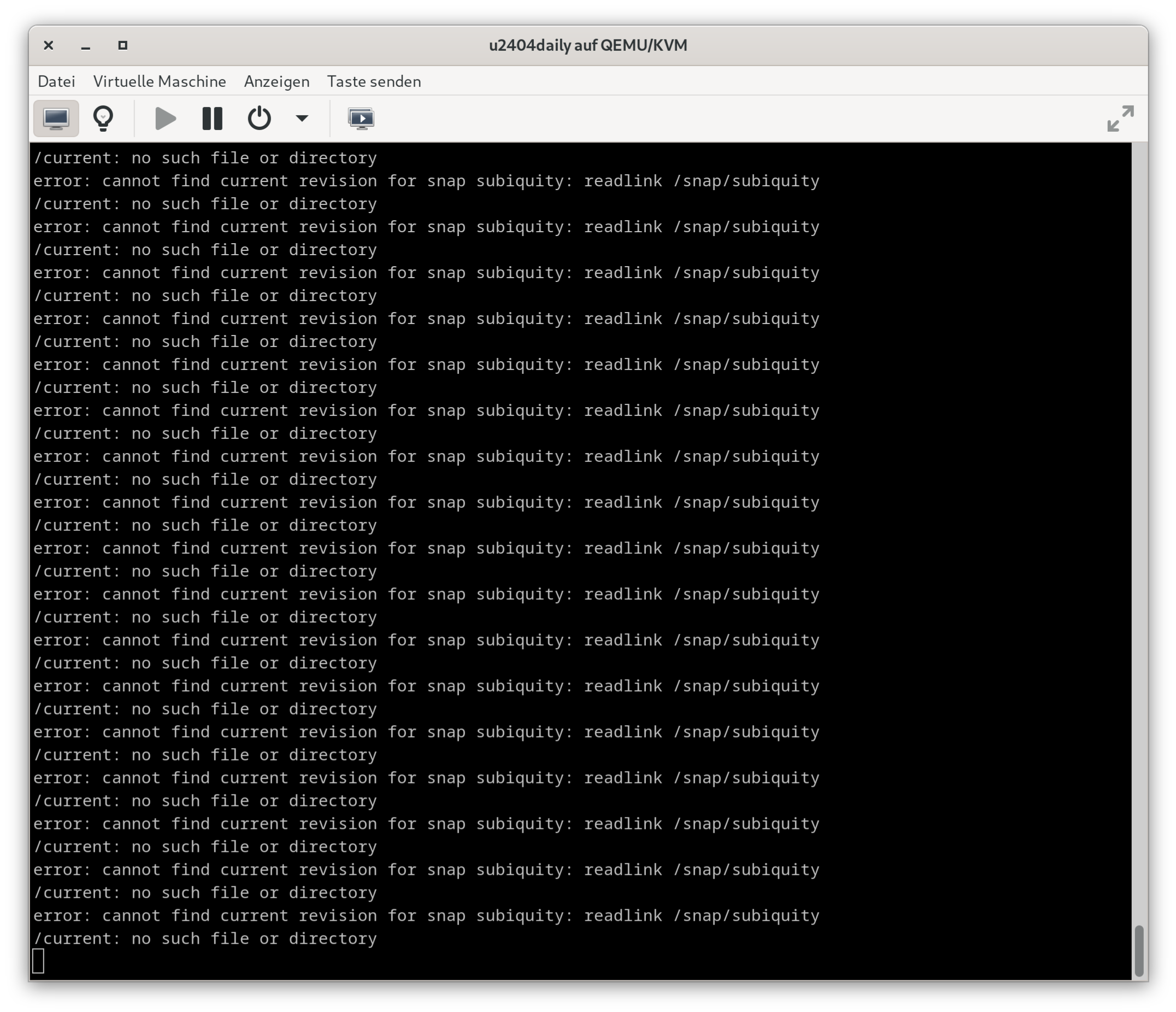
Als nächstes habe ich mir ein Daily-ISO-Image für Arm64 von Ubuntu 24.04 heruntergeladen und versucht, es in einer virtuellen Maschine zu installieren. Kurz nach dem Start stürzt der virt-manager ab. Die virtuelle Maschine läuft weiter, allerdings nur im Textmodus. Später bleibt die die Installation in einer snap-Endlosschleife hängen. Nun gut, es ist eine Entwicklerversion, die noch nicht einmal offiziellen Beta-Status hat.
Eine gescheiterte Installation von Ubuntu 24.04 daily
Nächster Versuch mit 23.10. Allerdings gibt es auf cdimage.ubuntu.com kein Desktop-Image für arm64!? Gut, ich nehme das Server-Image und baue dieses nach einer Minimalinstallation mit apt install ubuntu-desktop in ein Desktop-System um. Allerdings stellt sich heraus, dass aptsehr lange braucht (Größenordnung: eine Stunde, bei nur sporadischer CPU-Belastung; ich weiß nicht, was da schief läuft). Die Textkonsole im Viewer von virt-manager ist zudem ziemlich unbrauchbar. Installation fertig, Neustart der virtuellen Maschine. Es gelingt nicht, den Grafikmodus zu aktivieren.
Dritter Versuch, Debian 12 für arm64. Obwohl ich mich für eine Installation im Grafikmodus entscheide, erscheinen die Setup-Dialoge in einem recht trostlosen Textmodus (so, als würde die Konsole keine Farben unterstützen).
Super-minimalistischer Textmodus in der VM
Schön langsam dämmert mir, dass mit dem Grafiksystem etwas nicht stimmt. Tatsächlich hat keine der virtuellen Maschinen ein Grafiksystem! (virt-manager unter x86 richtet das Grafiksystem automatisch ein, und es funktioniert — aber offenbar ist das unter arm64 anders.) Ich füge also das Grafiksystem manuell hinzu, aber wieder treten diverse Probleme auf: der VGA-Modus funktioniert nicht, beim Start der VM gibt es die Fehlermeldung failed to find romfile vgabios-stdvga.bin. QXL lässt sich nicht aktivieren: domain configuration does not support video model qxl. RAMfb führt zu einem EFI-Fehler während des Startups. Zuletzt habe ich mit virtio Glück. Allerdings funktioniert jetzt die Textkonsole nicht mehr, der Bootvorgang erfolgt im Blindflug.
Der Grafikmodus erscheint, aber die Maus bewegt sich nicht. Klar, weil der virt-manager auch das Mauseingabe-Modul nicht aktiviert hat. Ich füge auch diese Hardware-Komponente hinzu. Tatsächlich lässt sich der Mauscursor nach dem nächsten Neustart nutzen — aber die Tastatur geht nicht. Ja, die fehlt auch. Wieder ‚Gerät hinzufügen‘, ‚Eingabe/USB-Tastatur‘ führt zum Ziel. Vorübergehend habe ich jetzt ein Erfolgserlebnis, für ein paar Minuten kann ich Ubuntu 23.10 tatsächlich im Grafikmodus verwenden. Ich kann sogar eine angemessene Auflösung einstellen. Aber beim nächsten Neustart bleibt der Monitor schwarz: Display output is not active.
An dieser Stelle habe ich aufgegeben. Die nächste Auflage meines Linux-Buchs (die steht zum Glück erst 2025 an) könnte ich in dieser Umgebung nicht schreiben. Dazu brauche ich definitiv eine Linux-Installation auf x86-Hardware.
Docker, pardon, Podman: voll OK
Red Hat und Fedora meiden Docker wie der Teufel das Weihwasser. Dafür ist die Eigenentwicklung Podman standardmäßig installiert (Version 4.9). Das Programm ist weitestgehend kompatibel zu Docker und in der Regel ein guter Ersatz.
Ich setze in Docker normalerweise stark auf docker compose. Dieses Subkommando ist in Podman noch nicht integriert. Abhilfe schafft das (einigermaßen kompatible) Python-Script podman-compose, das mit dnf installiert wird und aktuell in Version 1.0.6 vorliegt.
Mein Versuch, mit Podman mein aus LaTeX und Pandoc bestehendes Build-System für meine Bücher zusammenzubauen, gelang damit überraschend problemlos. In compose.yaml musste ich die Services mit privileged: true kennzeichnen, um diversen Permission-denied-Fehlern aus dem Weg zu gehen. Auf jeden Fall sind hier keine unlösbaren Hürden aufgetreten.
Fazit
Soweit Asahi Linux mit Ihrem Mac kompatibel ist und Sie keine Features nutzen möchten, die noch nicht unterstützt werden (aus meiner Sicht am schmerzhaftesten: USB-C-Monitor, Mikrofon), funktioniert es großartig. Einerseits die Apple-Kombination aus hoher Performance und Stille, andererseits Linux mit all seinen Konfigurationsmöglichkeiten. Was will man mehr?
Leider sind die arm64-Plattform (genaugenommen aarch64) und Wayland noch immer nicht restlos Linux-Mainstream. Alle hier beschriebenen Ärgernisse hatten irgendwie damit zu tun — und nicht mit Asahi Linux! Der größte Stolperstein für mich: Mit virt-manager lässt sich nicht vernünftig arbeiten. Mag sein, dass sich diese Probleme umgehen lassen (Gnome Boxes?; Cockpit), aber ich befürchte, dass die Probleme tiefer gehen.
Eine gewisse Ironie an der Geschichte besteht darin, dass ich gerade am Raspberry-Pi-Buch arbeite: Raspberry Pi OS ist mittlerweile ebenfalls für die arm64-Architektur optimiert, es verwendet ebenfalls Wayland. Aber Fractional Scaling ist für den PIXEL Desktop sowieso nicht vorgesehen, damit entfallen alle damit verbundenen Probleme. So fällt es nicht auf, dass diverse Programme via XWayland laufen. Und um die arm64-Optimierungen hat sich die Raspberry Pi Foundation in den letzten Monaten gekümmert — zumindest, soweit es für den Raspberry Pi relevante Programme betrifft. Ich arbeite also momentan sowie schon in einer arm64-Welt, und es funktioniert verblüffend gut!
Wenn es also außer dem Raspberry Pi und den MacBooks noch ein paar »normale« Notebooks mit arm64-CPUs gäbe, würde das sowohl dem Markt als auch der Stabilität von Linux auf dieser Plattform gut tun.
Bleibt noch die Frage, ob Asahi Linux besser als macOS ist. Schwer zu sagen. Für hart-gesottene Linux-Fans sicher. Für meine alltägliche Arbeit ist der größte Linux-Pluspunkt absurderweise ein ganz winziges Detail: Ich verwende ununterbrochen die Linux-Funktion, dass ich Text mit der Maus markieren und dann sofort mit der mittleren Maustaste wieder einfügen kann. macOS kann das nicht. Für macOS spricht hingegen die naturgemäß bessere Unterstützung der Apple-Hardware.
Losgelöst davon funktionieren fast alle gängigen Open-Source-Tools auch unter macOS. Über den Desktop von macOS kann man denken, wie man will; ich kann damit leben. Hundertprozentig glücklich machen mich auch Gnome oder KDE nicht. In jedem Fall ist es unter macOS wie unter Linux mit etwas Arbeit verbunden, den Desktop so zu gestalten, wie ich ihn haben will.
PS: Ein persönliches Nachwort
Seit zwei Monaten verwende ich versuchsweise macOS auf einem Mac Mini (wie beschrieben, M1-CPU + 16 GB RAM) als Hauptdesktop. Ich schreibe/überarbeite dort meine Bücher, bereite den Unterricht vor, administriere Linux-Server, entwickle Code. Virtuelle Maschinen laufen mit UTM. Docker funktioniert gut, allerdings stört, dass der Speicher für Docker fix alloziert wird. (Docker unterstützt sogar Rosetta. Ich habe eine Docker-Umgebung, die ein x86-Binary enthält, zu dem es kein arm64-Äquivalent gibt. Und es läuft einfach, es ist schwer zu glauben …)
Ich verwende Chrome als Webbrowser, Thunderbird als E-Mail-Programm, LibreOffice für Office-Aufgaben, Gimp als Bitmap-Editor, draw.io als Zeichenprogramm, Emacs + Code als Editoren, Skim als PDF-Viewer. Im Terminal sind diverse SSH-Sessions aktiv, so dass ich den Raspberry Pi, meine Linux-Server usw. administrieren kann. Zusatzsoftware installiere ich mit brew so unkompliziert wie mit dnf oder apt. Im Prinzip bin ich auf keine unüberwindbaren Hindernisse gestoßen, um meine alltägliche Arbeit auszuführen.
Es gibt nur ganz wenige originale macOS-Programme, die ich regelmäßig ausführe: das Terminal, Preview + Fotos. Außerdem finde ich es praktisch, dass ich M$ Office nativ verwenden kann. Ich hasse Word zwar abgrundtief, muss aber beruflich doch hin und wieder damit arbeiten. Das habe ich bisher auf einem Windows-Rechner erledigt.
Letzten Endes ist der Grund für dieses Experiment banal: Mich nervt der Lüfter meines Linux-Notebooks (ein fünf Jahre alter Lenovo P1) immer mehr. Wenn ich die meiste Zeit Ruhe haben will, muss ich den Turbo-Modus der CPU deaktivieren. Ist es für Intel/AMD wirklich unmöglich, eine CPU zu bauen, die so energieeffizient ist wie die CPUs von Apple? Kann keiner der Mainstream-Notebook-Hersteller (Lenovo, Dell etc.) ein Notebook bauen, das ganz gezielt für den leisen Betrieb gedacht ist, OHNE die Performance gleich komplett auf 0 zu reduzieren?
Im Unterschied zum Lenovo P1 läuft mein Mac komplett lautlos und ist gleichzeitig um ein Mehrfaches schneller. Es ist nicht auszuschließen, dass mein nächstes Notebook keine CPU von Intel oder AMD haben wird, sondern eine M3- oder M4-CPU von Apple. Die Option, auf diesem zukünftigen MacBook evt. auch Linux ausführen zu können, ist ein Pluspunkt und der Grund, weswegen ich mich so intensiv mit Asahi Linux auseinandersetze.
Ich habe es nicht ausprobiert, aber Sie können auch Ubuntu auf M1/M2-Macs installieren. Canonical überlegt anscheinend sogar, das irgendwann offiziell zu unterstützen.
Stellt euch vor, ihr habt eine Menge von Servern, welche ausschließlich über IPv6-Adressen verfügen und deshalb keine Dienste nutzen können, welche nur über IPv4 bereitgestellt werden. Wer sich dies nicht vorstellen mag, findet in „IPv6… Kein Anschluss unter dieser Nummer“ ein paar Beispiele dafür.
Was kann man nun tun, damit diese IPv6-only-Hosts dennoch mit der IPv4-only-Welt kommunizieren können?
Eine mögliche Lösung ist die Nutzung eines Dualstack-Proxy-Servers. Das ist ein Server, welcher über Adressen beider Internet-Protokoll-Versionen verfügt und so stellvertretend für einen IPv6-Host mit einem IPv4-Host kommunizieren kann. Das folgende Bild veranschaulicht den Kommunikationsablauf:
Ablauf der Netzwerkkommunikation eines IPv6-Hosts mit einem IPv4-Host über einen Dualstack-Proxy-Server
Im Bild ist zu sehen:
Wie IPv6-Host A eine Verbindung über IPv6 zum Proxy-Server B aufbaut und diesem bspw. die gewünschte URL mitteilt
Der Proxy-Server B baut nun seinerseits eine IPv4-Verbindung zu IPv4-Host C auf, welcher die gewünschten Inhalte bereitstellt
IPv4-Host C sendet seine Antwort über IPv4 an den Proxy-Server
Der Proxy-Server sendet die gewünschten Inhalte anschließend via IPv6 an den IPv6-Host A zurück
Screencast zur Demonstration der Proxy-Nutzung
Das obige Video demonstriert die Nutzung eines Proxy-Servers durch den Abruf einer Demo-Seite mit curl:
Mit dem host-Kommando wird gezeigt, dass für die Demo-Seite kein AAAA-Record existiert; die Seite ist also nicht via IPv6 erreichbar
Mit dem ip-Kommando wird geprüft, dass der Host auf dem Interface ens18 ausschließlich über IPv6-Adressen verfügt
Ohne Proxy ist die Demo-Seite nicht abrufbar
Erst durch Nutzung des Proxys kann die Seite abgerufen werden
Funktioniert das auch von IPv4 nach IPv6?
Ja. Entscheidend ist, dass der verwendete Proxy beide IP-Versionen unterstützt.
Welcher Proxy ist empfehlenswert?
Der Proxy-Server muss beide IP-Versionen beherrschen. Ich persönlich bevorzuge Squid. Dieser ist in so gut wie allen Linux-Distributionen verfügbar, weit verbreitet, robust und selbstverständlich Freie Software.
Sind damit alle Herausforderungen bewältigt?
Für eine Virtualisierungs-Umgebung mit einer IPv4-Adresse und einem /64-IPv6-Netzsegment funktioniert diese Lösung gut. Sie funktioniert auch in jeder anderen Umgebung, wie gezeigt. Man beachte jedoch, dass man mit nur einem Proxy einen Single-Point-of-Failure hat. Um diesem zu begegnen, kann man Squid mit keepalived hochverfügbar gestalten.
Keepalived ist ebenfalls Freie Software. Sie kostet kein Geld, erhöht jedoch die Komplexität der Umgebung. Verfügbarkeit vs. Komplexität möge jeder Sysadmin selbst gegeneinander abwägen.
Wie mache ich meine IPv6-Dienste für IPv4-User erreichbar, die keinen Proxy haben?
Das Stichwort lautet Reverse-Proxy. Ein Artikel dazu erscheint in Kürze in diesem Blog. ;-)
Firefox bekommt eine neue Funktion, um bei Herüberfahren mit der Maus über einen Tab eine Vorschau der jeweiligen Website anzuzeigen.
Bislang zeigt Firefox bei Herüberfahren mit der Maus über einen Tab einen ganz einfachen Tooltip mit dem Titel der Website als Inhalt an. Diesen hat Mozilla für die Tabs nicht nur optisch überarbeitet, sondern zeigt jetzt zusätzlich die URL sowie einen Screenshot der geöffneten Website an.
Die Funktion kann ab Firefox 123 über about:config aktiviert werden, indem der Schalter browser.tabs.cardPreview.enabled per Doppelklick auf true gesetzt wird. Allerdings ist zu beachten, dass die Arbeiten an der Funktion noch nicht komplett abgeschlossen sind und daher für die finale Version von Firefox 123 auch noch keine standardmäßige Aktivierung geplant ist.
Wird zusätzlich der Schalter browser.tabs.cardPreview.showThumbnails auf false gesetzt, können die neuen Tooltips ohne Vorschaubilder genutzt werden. Der Schalter browser.tabs.cardPreview.delayMs kontrolliert die Verzögerung, wann der Tooltip gezeigt werden soll. Standardmäßig steht diese Option auf 1000 (Millisekunden), sodass der Tooltip erst erscheint, nachdem man wenigstens eine Sekunde mit der Maus auf dem Tab war.
Gestern hatte ich einen Artikel veröffentlicht, in dem ich darauf hingewiesen habe, dass ich vorerst nichts mehr (automatisiert) auf Mastodon veröffentlichen werden. Grund hierfür war, dass nach der Deaktivierung des Applets (durch mich selbst) bei IFTTT eine erneute Aktivierung gescheitert ist. Der Grund ist wohl, dass die Funktion, neue Einträge eines RSS Feeds bei Mastodon (oder anderen Plattformen) per Webhook zu veröffentlichen, nun kostenpflichtig ist.
Bis gestern hat das Applet, soweit ich es nachvollziehen kann, aber seinen Dienst getan. Hätte ich es nicht deaktiviert, würde es vermutlich immer noch funktionieren. Wenn ich recht habe, finde ich die Art Leute zu kostenpflichtigen Tarifen zu “überreden” fragwürdig. Laut Quellen wie beispielsweise https://old.reddit.com/r/ifttt/comments/18p7pxa/webhooks_suddenly_stopped_working_requires_pro/ sind scheinbar auch andere Nutzer betroffen.
Ich habe mich allerdings für eine andere Lösung entschieden, da ich möglichst unabhängig von Diensten Dritter sein möchte. Gestern hatte ich mir noch diverse alternative Lösungen angesehen. Schlussendlich bin ich bei https://gitlab.com/chaica/feed2toot gelandet. Das Tool macht, was es soll und man kann es leicht selbst hosten. Auf “Dirks Logbuch” wurde schon vor einiger Zeit eine entsprechende Anleitung veröffentlicht, an der ich mich orientiert habe.
Vor wenigen Wochen habe ich mein zweites Fachbuch fertiggestellt. In diesem Blogpost gehe ich ein wenig tiefer ein, was meine Motivation war, wie sich der Fortschritt gestaltet hat und welche Hilfsmittel (nicht) geholfen haben.
Bücher schreiben klingt für viele total toll. Die Realität fühlte sich häufig allerdings das Meme oben an …
Rückblick
Vor langer Zeit fing ich hier auf meinem Blog eine vierteilige Tutorial-Reihe zu Git an. Der erste Blogpost erschien im Oktober 2014. Das ist jetzt auch schon fast zehn Jahre her. Meine damalige Intention war recht einfach: Ich hatte Lust etwas über das Thema zu schreiben, denn ich bekam sowohl bei der Arbeit, als auch bei der Mitarbeit in Open-Source-Projekten ständig Fragen, wie dieses Git denn nun funktioniert. Da ich keine Lust hatte, es immer wieder zu erklären, schrieb ich es eben einmal ordentlich runter und verlinkte diese Blog-Posts und beantwortete erst später konkretere Fragen.
Durch eine Verkettung von Umständen kam es dann dazu, dass ich die Möglichkeit hatte, ein Buch über Git zu schreiben. Diese vier Artikel dienten als Basis für das Buch, wo ich natürlich dann sehr sehr viel erweitert habe. Zwei Jahre später im August 2016, erschien dann die erste Auflage meines Git-Buches beim mitp-Verlag. Im Mai 2019 folgte die zweite Auflage, im März 2021 die dritte und im März 2022 folgte der Git Schnelleinstieg als abgespeckte Variante. Über die vergangenen 7,5 Jahre verkauften sich knapp über 4000 Exemplare.
Die Vor- und Nachteile des Autorendaseins
Ein Buch geschrieben zu haben, hat sowohl diverse Vor- als auch Nachteile. Jedes Mal, wenn mir jemand Anfängerfragen zu Git gestellt hat, folgte von mir ein stark ironisches „Also … ich kann dir da ein Buch empfehlen“. Das war immer wieder zur Aufheiterung lustig. Was ich meistens nicht so geil fand, waren Random Gespräche bei Feiern jeglicher Art. Da wurde man plötzlich von Freunden, Bekannten und Verwandten anderen Personen als Autor vorgestellt … was dazu geführt hat, dass ich ständig wildfremden Leuten, die nicht in der IT sind, erklären musste, was denn diese Versionsverwaltung mit Git ist. Meistens sah ich nach zwei oder drei Sätzen schon, wie sie bei meinem Versuch es zu erklären, ausgestiegen sind, aber natürlich empfanden sie es als super und toll! Spaß macht das nicht. Außerdem ist scheinbar „Buch schreiben“ ein Bucketlist-Item für viele Leute. Ich weiß bis heute nicht, warum, aber ich muss auch nicht alles verstehen.
Wer übrigens etwas näher hören will, wie so ein Buch entsteht, darüber habe ich in der zweiten Folge unseres Podcasts TILpod von und mit Dirk Deimeke gesprochen.
Ursprüngliche Motivation & Umsetzung
Zurück zur Motivation und der Umsetzung: Nachdem ich die ursprünglichen Blogposts ohne tieferen Hintergedanken geschrieben habe, war das bei einem Buch natürlich etwas anderes. Die Qualitätsansprüche sind hier natürlich deutlich höher, denn hier bezahlen die Kunden mit Geld. Von diesem Geld blieb allerdings nicht sehr viel in meinem Geldbeutel hängen. Dass man als Autor nicht reich wird, war mir bewusst.
Eine gewisse Reputation und ein „einfacherer“ Einstieg in idealerweise gut bezahlten Job mit guten Arbeitsbedingungen war mein Hauptmotivationstreiber. 2015, als ich mit der Arbeit am Buch begann, war ich gerade erst mit dem Bachelor fertig. Die darauffolgenden Jobwechsel waren beim Hinblick auf Gehalt, Arbeitsbedingungen und Interessantheit der Tätigkeiten alle nicht so das wahre (in verschiedenen Konstellationen).
Long story short: Im April 2020 fing ich meinen Job als Solutions Architect bei GitLab an. Zu den ausgeschriebenen Jobs bei GitLab hatte ich ohnehin schon seit einigen Jahren einen Blick geworfen und dann hat es auch auf Anhieb geklappt. Ein deutlicher Gehaltssprung war dabei, deutlich bessere Arbeitsbedingungen und auch die Tätigkeit im Pre-Sales, was ich so vorher auch nie gemacht habe, hat super gepasst. Mein Plan ging also einige Jahre später auf: Durch das Git-Buch habe ich mich deutlich tiefer in Git und dem gesamten Software-Delivery-Lifecycle eingearbeitet, sodass ich mich für den Job qualifizieren konnte.
Soweit so gut. Ein Grund für ein komplett neues Buch brauchte ich eigentlich nicht … oder? Oder?
Motivation für das zweite Buch
Tja, ich wäre nicht ich, wenn ich immer wieder ein größeres Projekt angehen würde.
Fachliche Motivation
Zunächst zur fachlichen Motivation: In tagtäglichen Gesprächen mit diversen (potenziellen) Kunden von GitLab merkte ich primär eins: Viele fokussieren sich viel zu stark auf die eingesetzten Tools – etwa GitLab –, ohne jedoch zu schauen, ob und wie „kaputt“ die Arbeitskultur ist.
GitLab selbst positioniert sich als ganzheitliche DevOps-Plattform, womit man einfacher und schneller Projekte mit DevOps-Prinzipien umsetzen kann, in dem besser in einem, statt in vielen, Tools kollaboriert wird. Das ist gut, richtig und wichtig.
Wichtige Voraussetzung ist allerdings, dass man erst die Arbeitskultur anpasst und dann die Prozesse anpasst, gefolgt vom Tooling. Im DevOps-Kontext spricht man nicht umsonst von „People over Processes over Tools“. Die besten Tools helfen nicht, wenn die Prozesse beschissen sind. Die Prozesse helfen nicht, wenn die Kolleginnen und Kollegen mit den verschiedenen Rollen (Development, Operations, Security, QA, …) gegeneinander statt miteinander arbeiten.
Mit diesem Buch möchte ich aufklären, wie es „richtig“ geht. Das beste, tollste, schnellste und effizienteste Auto bringt schließlich auch nicht, wenn man keine Straßen hat … und einen Führerschein auch nicht.
Fachlich war die Motivation also klar: Wenn es um DevOps geht, gibt es großen Nachholbedarf, das sehe ich schließlich bei den ganzen Gesprächen. Ein „echtes“ deutsches Buch zu DevOps gab es auch nicht, sondern nur zwei Übersetzungen aus dem Englischen. Und so reifte die Idee für das zweite Buch.
Nicht fachliche Motivation
Auf der nicht fachlichen Ebene sah es noch ein wenig anders aus. Hier kommen gleich mehrere Faktoren ins Spiel. Zunächst einmal war das Git-Buch recht technisch. Obwohl ich die Arbeit an dem Buch schon ziemlich herausfordernd fand, gab es hier meist nur eine technische Lösung, was das Schreiben deutlich vereinfacht hat. Bei DevOps ist das Ganze anders. Hier geht es viel um „weiche“ Themen, wie Menschen miteinander arbeiten. Das ist um ein Vielfaches herausfordernder. Das hat mich auch angespornt.
Weiterhin wollte ich dieses Mal bei einem größeren Verlag veröffentlichen. Die Zusammenarbeit mit dem mitp-Verlag war zwar gut und ich soweit zufrieden, aber im Marketing und bei Verkaufszahlen merkt man dann schon einige Unterschiede. Der Einstieg beim größten deutschen IT-Verlag, dem Rheinwerk-Verlag, hat mit diesem Buch dann auch funktioniert.
Die damalige Motivation für einen „besseren“ Job hatte ich beim DevOps-Buch hingegen nicht. Finanzielles spielte demnach weder primär noch sekundär eine Rolle. Ich bin trotzdem gespannt, welche neue Türe sich hierdurch gegebenenfalls öffnen.
Meine grundlegende Motivation liest sich bis hierhin eigentlich gut, aber die Motivation muss schließlich nicht nur beim Start vorhanden sein, sondern auch während man das Buch schreibt …
Der Fortschritt …
Die Motivation kontinuierlich und mit (höchster) Disziplin am Buch zu arbeiten, klang zu Beginn viel einfacher als es am Ende dann war. Um es kurz zu sagen: Es war ein Kampf. Und das war überhaupt nicht geil.
Der Unterschied zu damals™
Im Vergleich zum Git-Buch hatte ich ein Aspekt komplett vernachlässigt. Mein Job damals war deutlich weniger anstrengend. Damals war ich rein in der Technik und ohne Reisetätigkeiten. Das lässt sich viel einfacher steuern, als mein jetziger Job. Bei GitLab hatte und habe ich jeden Tag etliche Videocalls mit Kunden. Bei diesen Calls muss ich stets fokussiert und effizient sein, was für den Kopf deutlich anstrengender ist. Zudem machte mir der Job auch noch deutlich mehr Spaß, ich hatte auch noch (ab Mai 2022) etliche Dienstreisen, die einen regelten Tagesablauf nicht ermöglicht haben. Am Ende des Arbeitstages und auch am Wochenende war so nicht mehr so viel Gehirnkapazität übrig, um stetigen Fortschritt zu gewährleisten.
Das „weiche“ Thema führte auch dazu, dass ich immer wieder überlegen musste, wie ich diverse Themen angehen sollte, damit man daraus auch etwas Sinnvolles herausziehen kann. Das führte immer wieder zu Verzögerungen, da ich dann noch die Gedanken schweifen lassen oder mit der ein oder der anderen Person aus dem Arbeitsumfeld besprechen musste, um mir neue Eindrücke abzuholen. Gleichzeitig hing die Frist immer im Nacken …
Produktivitätstechniken
Während des Schreibens probierte ich auch immer wieder ein paar Produktivitätstechniken aus. Je nach Phase des Buches war das auch relativ gut und hilfreich.
Zu Beginn, nachdem die Grobstruktur gestanden hatte, fokussierte ich mich zunächst um Stichpunkte. Ich tippte also, was mir in den Kopf kam zu den einzelnen Themen in Stichpunkten herunter, und kümmerte mich kaum um die Grammatik. Das war wichtig, um überhaupt mal die Gedanken strukturieren zu können. Dabei fielen mir noch etliche Themen ein, die ich vorher gar nicht betrachtet hatte … die dann zu neuen Kapiteln führten.
Ich setzte hierfür auf die Pomodoro-Technik: Ich versuchte jeden Tag mindestens 25min, ohne Ablenkungen, Stichpunkte herunterzuschreiben, gefolgt von einer 5min Pause. Danach habe ich weiter gemacht … oder häufig auch nicht. Das war auch völlig in Ordnung.
Das Ganze funktionierte so lange, bis es nicht mehr funktionierte. Irgendwann hatte ich dann alles notiert und es ging mehr Zeit drauf, zu überlegen, was man noch vergessen hat. Gerade für diese Phase benötigte ich viel Ruhe und Zeit, die durch Real-Life und Vollzeitjob nicht sonderlich gegeben war.
Es gab also immer wieder Phasen – teilweise einige Monate – wo ich wenig bis gar nicht am Buch gearbeitet habe. Dabei war das offene Großprojekt, das Wissen, noch etwas erledigen zu müssen, die Frist und was sonst noch dazu gehört, stets im Hinterkopf. Schön war das zugegeben nicht wirklich.
Später, beim Ausformulieren der Stichpunkte, habe ich mir hingegen ein Output-Ziel gesetzt. An Arbeitstagen wollte ich für zwei zusätzliche Seiten sorgen, an arbeitsfreien Tagen hingegen fünf. Da dann primär viel ausformuliert werden musste, klappte das für eine Weile auch einigermaßen gut.
Öffentlicher Statusbericht
Gleichzeitig habe ich meinen eigenen Podcast TILpod, den ich mit Dirk Deimeke betreibe, vorangetrieben. Dort erzählte ich in jeder Folge, wie der Fortschritt am Buch ist. Treue Hörer und Hörerinnen haben also stets mitbekommen, wie ich vorankomme … oder auch nicht.
Das öffentliche Dokumentieren des Fortschritts hat hingegen nicht zu mehr Druck geführt, zumindest nicht bewusst. Einige lustige Gegebenheiten haben sich hingegen schon dadurch ergeben. Vergangenes Jahr war ich dienstlich bei der KubeCon in Amsterdam, wo ich Standdienst bei GitLab gemacht habe. Es kamen erstaunlich viele mir unbekannte Personen auf mich zu und fragten, ob mein Buch denn nun fertig ist. Auch eine spannende Form, auf Hörer vom Podcast zu treffen.
Ursprünglich war mein Plan, bis Ende 2022 fertig zu werden. Dass das nicht zu halten war, war mir schon zu Beginn klar. Unterschrieben habe ich den Autorenvertrag übrigens im Januar 2022. Erst im Sommer 2023, nachdem ich mehrfach die Fertigstellung nach hinten schieben musste, war der erste Entwurf fertig. Und dann ging erst die Arbeit mit diversen Korrekturläufen, dann zusammen mit meinem Lektor, los.
Mein Ziel es dann noch im Jahr 2023 fertigzustellen hat dann nicht auch nicht mehr geklappt. Nachdem ich selbst für so viel Verspätung gesorgt hatte, lag es dann auch noch eine Weile bei meinem Lektor auf Halde: Mein Buch ist schließlich nicht das Einzige, meins musste entsprechend warten.
Der Spätsommer und Herbst war dann ebenfalls ziemlich frustrierend. Jeden Monat verschob sich die Fertigstellung um einen Monat. Jedes Mal, wenn ich dachte, dass ich jetzt wirklich mal fertig wurde, mussten wir es abermals um einen Monat verschieben. Insgesamt lagen zwischen der Unterzeichnung des Autorenvertrags und der Fertigstellung ziemlich genau zwei Jahre.
(Keine) Hilfsmittel
Ganz unabhängig von der Motivation und der Produktivität finde ich es auch noch spannend auf mögliche Hilfsmittel zu werfen. Insbesondere ChatGPT, LanguageTool und Obsidian.
ChatGPT
Während des Schreibens des Buches ploppte dann auch noch ChatGPT auf und der AI-Hype ging so richtig los. An vielen Stellen las ich dann, dass man ja jetzt „ganz einfach“ Texte schreiben lassen kann und bald nur noch AI-generierte Bücher gibt.
Ich dachte dann: Ja gut, ich habe hier ja ein Beispiel, schauen wir mal, ob ChatGPT hier überhaupt realistisch helfen kann. Tja, nun … tat es nicht wirklich.
Ich hatte natürlich nicht vor, mein Buch per ChatGPT schreiben zu lassen. Das funktioniert ohnehin nicht. Die Frage, die ich mir stattdessen stellte, ging mehr in die Richtung: Wie kann mir ggf. ChatGPT helfen?
Typische Prompts à la „Schreib mir etwas zu $THEMA im Rahmen von DevOps“ produzierten (natürlich) sehr, sehr oberflächliche Texte, die sich zu 95 % ohnehin immer nur wiederholten. Praktisch war hingegen, ChatGPT zu nutzen, um zu prüfen, ob man etwas vergessen hatte. So ergänzte ich zur „normalen“ Recherche auch ChatGPT, wobei der tatsächliche Nutzen eher gering war, schließlich stand der Großteil und ChatGPT kann man ja bekanntlich auch nicht alles glauben. Häufig kam da auch nur Mist raus.
LanguageTool
ChatGPT war also nur wenig hilfreich, anders sah es bei LanguageTool aus, was für sprachliche Korrekturen sehr hilfreich war. Dafür setzte ich auf die Premium-Variante für knapp 60 € pro Jahr.
LanguageTool gab mir einige Hinweise für die korrekte Nutzung der deutschen Sprache. Viel zu lange Sätze, Wortwiederholungen, Kommasetzung und noch etliche weitere Hinweise wurden mir dann regelmäßig angezeigt, sodass ich da noch einmal drauf geschaut habe.
Praktisch war zudem das Feature „Sentence rephrasing by A.I.“. Hier konnte man einzelne Sätze aus einigen Paragrafen neu formulieren lassen. Das half mir insbesondere dann, wenn ich an einigen komplexen Sätzen viel zu lange hing, weil diese kaum verständlich waren.
Obsidian
DIe meiste Zeit beim Schreiben verbrachte ich im Tool Obsidian. Das ist eigentlich mehr als persönliches Knowledge-Base gedacht. Für mich half es hingegen das Buch primär in Markdown herunter zu schreiben, da es mich nicht zu sehr abgelenkt hat. Viele der Features von Obsidian habe ich allerdings nicht verwendet. Einige fehlerhafte Verlinkungen fielen mir dann nur regelmäßig auf. LanguageTool ließ sich zudem als Plug-in einbinden und nutzen.
Zum Ende hin musste ich allerdings sowieso auf Microsoft Word switchen, weil das der Workflow vom Verlag so vorgibt. Bis dahin konnte man es wenigstens gut in Git-Repositorys tracken, sodass ich Anpassungen von Reviewern und Lektor einfach nachvollziehen konnte.
Fazit
Warum sollte man also eher kein Fachbuch schreiben?
Es ist verdammt anstrengend, es geht richtig viel Zeit drauf und ist häufig auch echt frustrierend. Reich wird man nicht. Ob es sich für mich gelohnt hat, wird sich zeigen. In den letzten zwei Jahren verbrachte ich also sehr viel Zeit mit meinem Vollzeitjob und dem Schreiben des Buches. Viel Zeit drum herum, blieb da nicht. Gesund war das ganze auch nicht sonderlich.
Das fertige Buch
Wer bis hierhin gelesen hat, wird gemerkt haben, dass das Thema des Buches eine untergeordnete Rolle gespielt hat, dazu folgt noch ein weiterer Artikel. Das DevOps-Buch gibt es überall da, wo es Bücher gibt – insbesondere direkt beim Verlag. Es erscheint am 5. März 2024. Ich warte zurzeit noch auf meine Belegexemplare und kann es kaum erwarten.
Seit einiger Zeit wird unter https://social.tchncs.de/@fryboyter ein Hinweis angezeigt, wenn ich einen neuen Artikel veröffentlicht habe. Damit ist vorerst Schluss.
Für die automatische Veröffentlichung hatte ich bisher den Dienst IFTTT verwendet. Vorhin wollte ich etwas an dem betreffenden Applets ändern und habe dies hierbei deaktiviert. Was ich wohl lieber nicht gemacht hätte. Wenn ich das Applet nun aktivieren will, erhalte ich nun den Hinweis “This Applet has Pro features”. Scheinbar sind Webhooks bei IFTTT zwischenzeitlich kostenpflichtig geworden. Und sobald man ein ehemalig kostenloses Applet deaktiviert, hat man die Arschkarte gezogen und soll nun zahlen, wenn man es wieder aktivieren will. 2,92 Dollar im Monat, wenn man jährlich zahlt oder 3,49 Dollar, wenn man monatlich bezahlt.
Wenn man bedenkt, dass ich bei Mastodon im Grunde nicht aktiv bin und dort nur entsprechende Hinweise auf neue Artikel veröffentlicht habe, will ich weder 2,92 noch 3,29 Dollar bezahlen. Zumal ich auch beispielsweise RSS-Feeds wie https://fryboyter.de/index.xml anbieten über die man sich über neue Artikel in Kenntnis setzen lassen kann und ich IFTTT für nichts anderes nutze.
Ich hatte schon vor einiger Zeit mit Alternativen wie Node Red oder N8N experimentiert. Leider bin ich entweder komplett daran gescheitert, dass es funktioniert hat oder es wurden alle Beiträge der angegebenen Feed-Adresse bei Mastodon veröffentlicht und nicht nur der neuste Beitrag. Falls jemand hierfür eine Lösung hätte und bereit ist mir sinnvoll zu helfen, wäre es sehr nett. Ich aktiviere daher bei diesem Beitrag die Kommentarfunktion. Alternativ kann man mir auch eine E-Mail schreiben. Die Adresse ist im Impressum genannt.