Mozilla wird am Mittwoch Firefox 60 veröffentlichen. Firefox 60 wird gleichzeitig die neue Basis für Firefox ESR sein, die Firefox-Version mit Langzeitunterstützung. Während Firefox 60 und Firefox ESR 60 grundsätzlich identisch sind, gibt es doch ein paar wichtige Unterschiede zwischen beiden Versionen.
Mozilla wird am 9. Mai 2018 Firefox 60 und Firefox ESR 60 veröffentlichen. Nutzer von Firefox ESR 52 haben ab dann noch 17 Wochen Zeit, ehe sie mit Erscheinen von Firefox 62 und Firefox ESR 60.2 am 5. September 2018 automatisch auf Firefox ESR 60 migriert werden. Wie schon Firefox ESR 52 unterscheidet sich auch Firefox ESR 60 in ein paar Aspekten von seinem Mainstream-Pendant.
Firefox ESR 60: standardmäßig keine Service Workers
Service Workers gehören zweifelsohne zu den Webstandards, welche in Zukunft aus vielen modernen Webapplikationen nicht mehr wegzudenken sein werden. Firefox unterstützt Service Workers seit Version 44. Schon in Firefox ESR 45 waren Service Workers aufgrund damals zu erwartender Spezifikations- und Implementierungsänderungen standardmäßig deaktiviert. Auch in Firefox ESR 52 waren Service Workers standardmäßig deaktiviert, wegen andauernden Änderungen unter der Haube zur vollständigungen Unterstützung mehrerer Content-Prozesse, was es schwierig machen würde, Fixes für Firefox ESR zurück zu portieren. Aus dem gleichen Grund werden Service Workers auch in Firefox ESR 60 standardmäßig deaktiviert sein.
Zur Aktivierung in Firefox ESR 60 muss der folgende Schalter über about:config auf true geschaltet werden:
dom.serviceWorkers.enabled
Firefox ESR 60: standardmäßig keine Push-Benachrichtigungen
Ebenfalls werden Push-Benachrichtigungen in Firefox ESR 60 standardmäßig deaktiviert sein, da diese Service Workers als technische Voraussetzung haben.
Zur Aktivierung in Firefox ESR 60 muss der folgende Schalter über about:config auf true geschaltet werden:
dom.push.enabled
Nur in Firefox ESR 60: zusätzliche Enterprise Policies
Mit Firefox 60 liefert Mozilla erstmals seine sogenannte Enterprise Policy Engine aus. Damit ist es für Systemadministratoren möglich, Firefox für die Verteilung im Unternehmen vorzukonfigurieren, wofür bis einschließlich Firefox ESR 52 gerne der sogenannte CCK2 Wizard benutzt worden ist, der allerdings mit Firefox 57 und höher nicht kompatibel ist.
Firefox ESR 60 wird zusätzliche Enterprise Policies unterstützen, welche in der Mainstream-Version von Firefox nicht funktionieren.
Tipp: Die Firefox-Erweiterung Enterprise Policy Generator, welche ich voraussichtlich in dieser Woche veröffentlichen werde, erlaubt ein einfaches Zusammenklicken aller möglichen Enterprise Policies und wird außerdem diejenigen Policies besonders kennzeichnen, welche ausschließlich in Firefox ESR funktionieren.
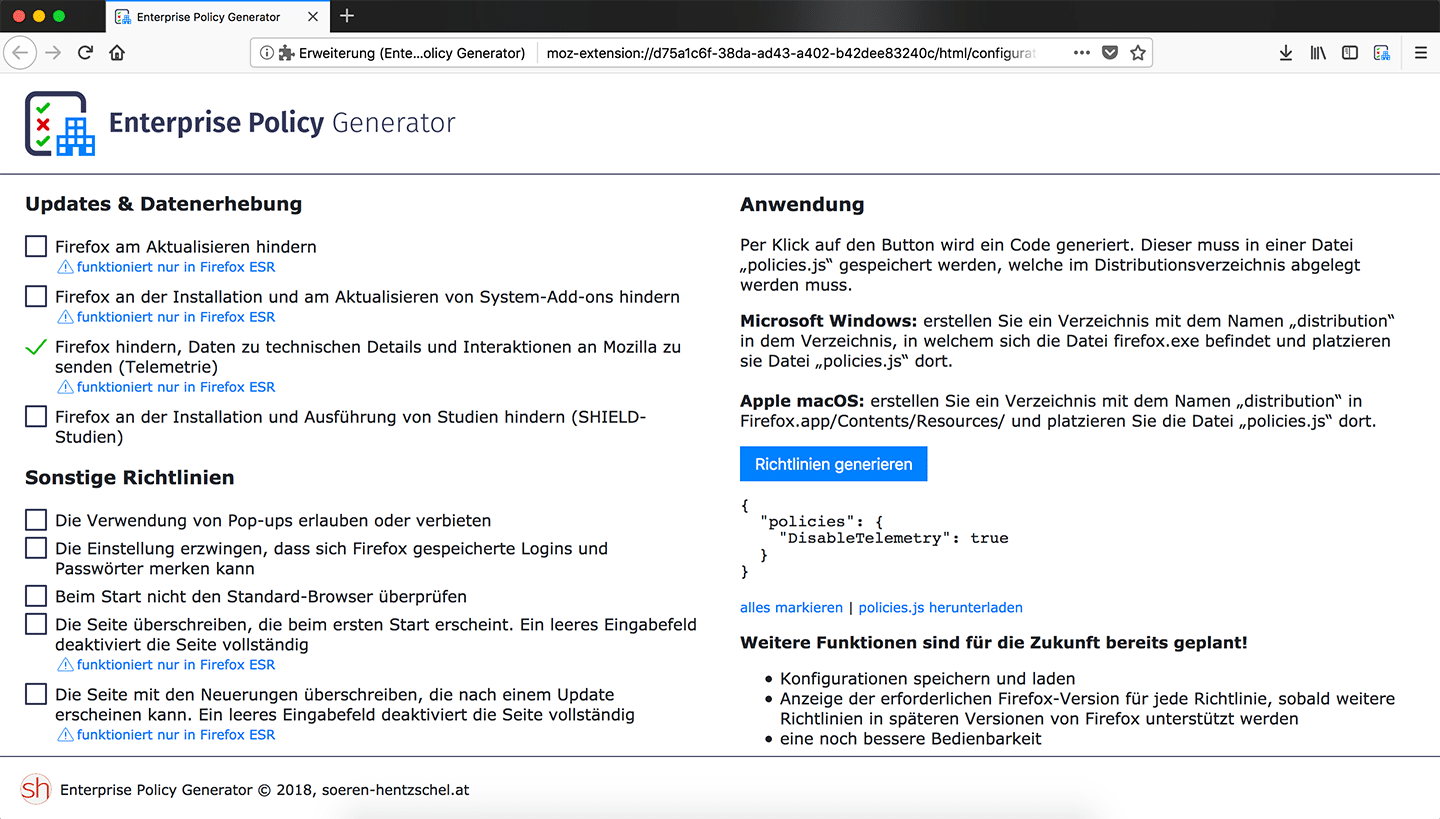
Nur in Firefox ESR 60: deaktivierbare Signaturpflicht für Add-ons
Zum Schutz seiner Nutzer hat Mozilla eine Signaturpflicht für Add-ons in Firefox eingeführt, welche seit Firefox 43 standardmäßig aktiviert ist. Diese kann nur in Nightly-Builds sowie in der Developer Edition von Firefox deaktiviert werden, nicht in Beta- oder finalen Versionen. Die ESR-Version von Firefox 60 erlaubt auch in der finalen Ausführung die Deaktivierung der Signaturpflicht.
Zur Deaktivierung in Firefox ESR 60 muss der folgende Schalter über about:config auf false geschaltet werden:
xpinstall.signatures.required
Achtung: Es ist aus Sicherheitsgründen nicht empfohlen, die Signaturpflicht für Erweiterungen zu deaktivieren. Wer seine Erweiterungen ausschließlich über addons.mozilla.org bezieht, findet außerdem in der Regel sowieso ausschließlich signierte Erweiterungen vor.
Folgende Unterschiede aus Firefox ESR 52 existieren nicht mehr
Folgende Unterschiede existierten noch zwischen Firefox 52 und Firefox ESR 52, werden aber nicht mehr zwischen Firefox 60 und Firefox ESR 60 existieren:
Multiprozess-Architektur: Für die Auslieferung der Multiprozess-Architektur gab es in Firefox ESR 52 strengere Kriterien als in der Mainstream-Version von Firefox 52, was dazu führte, dass die Multiprozess-Architektur in der ESR-Version mit einer höheren Wahrscheinlichkeit deaktiviert war. In Firefox ESR 60 besteht diesbezüglich kein Unterschied zu Firefox 60.
NPAPI-Plugins: Während in der Mainstream-Version von Firefox 52 der Adobe Flash Player als einziges NPAPI-Plugin unterstützt worden ist, konnten in Firefox ESR 52 auch andere NPAPI-Plugins wie Microsoft Silverlight und Oracle Java genutzt werden. Firefox ESR 60 unterstützt wie die Mainstream-Version nur noch den Adobe Flash Player als einziges NPAPI-Plugin.
WebAssembly (wasm): WebAssembly, oder kurz: wasm, ist ein neues Binärformat für das Web. Ähnlich wie bei Mozillas asm.js oder Googles PNaCl handelt es sich dabei um das Resultat kompilierten Codes und soll die Performance von Webanwendungen auf eine neue Ebene heben. In Firefox ESR 52 war WebAssembly standardmäßig deaktiviert, in Firefox ESR 60 wird WebAssembly standardmäßig aktiviert sein.
Windows XP: Nutzer von Windows XP und Windows Vista erhalten bis zum Lebensende von Firefox ESR 52 noch Sicherheits-Aktualisierungen. Ein Update auf Firefox 60 respektive Firefox ESR 60 wird es für entsprechende Nutzer nicht mehr geben.
Der Beitrag Alle Unterschiede zwischen Firefox 60 und Firefox ESR 60 erschien zuerst auf soeren-hentzschel.at.